Een spoedcursus synthetische data
Introductie
Wat is synthetische data?
Het antwoord is relatief eenvoudig. Terwijl originele data worden verzameld in al uw interacties met echte personen (bijv. klanten, patiënten, medewerkers enz.) en via al uw interne processen, worden synthetische data gegenereerd door een computeralgoritme. Dit computeralgoritme genereert volledig nieuwe en kunstmatige datapunten.
Los uitdagingen op het gebied van dataprivacy op
Synthetisch gegenereerde data bestaat uit volledig nieuwe en kunstmatige datapunten zonder een-op-een relaties met de originele data. Daarom kan geen van de synthetische datapunten worden herleid of reverse-engineered naar originele data. Als gevolg hiervan zijn synthetische data vrijgesteld van privacyregelgeving, zoals de AVG, en dienen ze als oplossing om uitdagingen op het gebied van dataprivacy op te lossen en te overwinnen.
Vergroten en simuleren
Het generatieve aspect van het genereren van synthetische data maakt het mogelijk om volledig nieuwe data te vergroten en te simuleren. Dit fungeert als oplossing wanneer u niet genoeg data heeft (data schaarste), edge-cases wilt up-samplen of wanneer u nog geen data heeft.
Hier ligt de focus van Syntho op gestructureerde data (data opgemaakt in tabellen met rijen en kolommen, zoals je ziet in een Excel-sheet), maar we illustreren het concept van synthetische data altijd graag via afbeeldingen, omdat dit aantrekkelijker is.
Soorten synthetische data
Er zijn drie soorten synthetische data binnen de paraplu van synthetische data. Die 3 soorten synthetische data zijn: dummy data, op regels gebaseerde gegenereerde synthetische data en synthetische data gegenereerd door kunstmatige intelligentie (AI). We leggen kort uit wat de 3 verschillende soorten synthetische data zijn.
Dummy-data / nepdata
Dummy-data zijn willekeurig gegenereerde data (bijvoorbeeld door een nepdatagenerator).
Bijgevolg worden kenmerken, relaties en statistische patronen die in de originele data voorkomen niet bewaard, vastgelegd en gereproduceerd in de gegenereerde dummydata. Daarom is de representativiteit van dummy data / mock data minimaal in vergelijking met de originele data.
- Wanneer te gebruiken: ter vervanging van direct identifiers (PII) of wanneer u (nog) geen data heeft en geen tijd en energie wilt steken in het definiëren van regels.
Op regels gebaseerde synthetische data
Op regels gebaseerde gegenereerde synthetische data zijn synthetische data die zijn gegenereerd door een vooraf gedefinieerde set regels. Voorbeelden van die vooraf gedefinieerde regels kunnen zijn dat u synthetische data wilt hebben met een bepaalde minimumwaarde, maximumwaarde of gemiddelde waarde. Elk van de kenmerken, relaties en statistische patronen die u zou willen reproduceren in de op regels gebaseerde gegenereerde synthetische data, moeten vooraf worden gedefinieerd.
Hierdoor zal de datakwaliteit zo goed zijn als de vooraf gedefinieerde set van regels. Dit levert uitdagingen op wanneer een hoge datakwaliteit van essentieel belang is. Ten eerste kan men slechts een beperkte set regels definiëren die in de synthetische data moeten worden vastgelegd. Bovendien leidt het instellen van meerdere regels doorgaans tot overlappende en tegenstrijdige regels. Bovendien dekt u nooit alle relevante regels volledig. Bovendien kunnen er relevante regels zijn waarvan u niet eens op de hoogte bent. En tot slot (en niet te vergeten) kost dit u veel tijd en energie met als gevolg een niet-efficiënte oplossing.
- Wanneer gebruiken: wanneer u (nog) geen data heeft
Synthetische data gegenereerd door kunstmatige intelligentie (AI)
Zoals je van de naam mag verwachten, zijn synthetische data gegenereerd door kunstmatige intelligentie (AI) synthetische data die zijn gegenereerd door een kunstmatige intelligentie (AI) algoritme. Het AI-model is getraind op de originele data om alle kenmerken, relaties en statistische patronen te leren. Daarna is dit AI-algoritme in staat om volledig nieuwe datapunten te genereren en die nieuwe datapunten zo te modelleren dat het de kenmerken, relaties en statistische patronen uit de oorspronkelijke dataset reproduceert. Dit noemen we een synthetische data-tweeling.
Het AI-model bootst originele data na om synthetische datatweelingen te genereren die kunnen worden gebruikt alsof het originele data zijn. Dit ontgrendelt verschillende use-cases waarbij de door AI gegenereerde synthetische data kan worden gebruikt als alternatief voor het gebruik van originele (gevoelige) data, zoals het gebruik van door AI gegenereerde synthetische data als testdata, demodata of voor analyses.
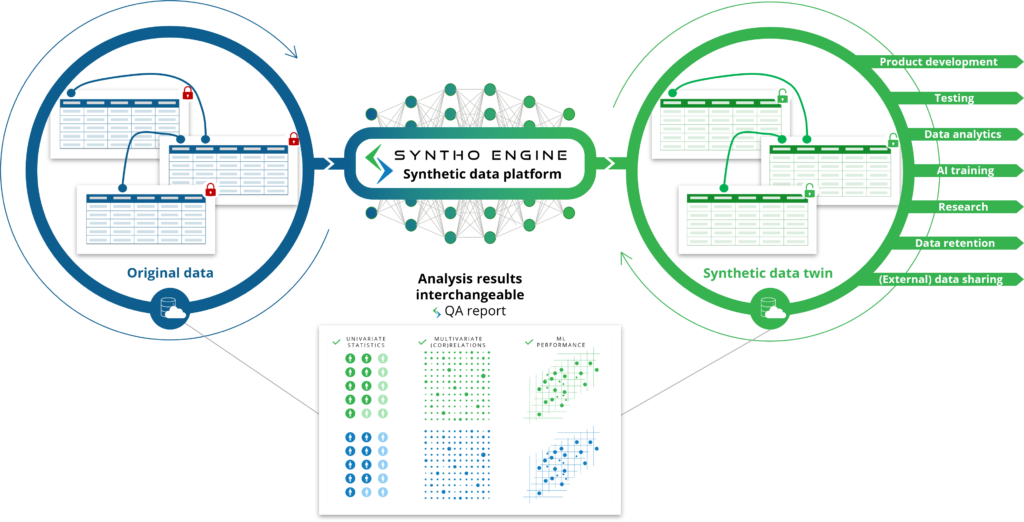
In vergelijking met op regels gebaseerde gegenereerde synthetische data: in plaats van dat u relevante regels bestudeert en definieert, doet het AI-algoritme dit automatisch voor u. Hier worden niet alleen kenmerken, relaties en statistische patronen behandeld waarvan u zich bewust bent, maar ook kenmerken, relaties en statistische patronen waarvan u zich niet eens bewust bent.
- Wanneer te gebruiken: wanneer u (sommige) data als invoer hebt om na te bootsen of om te gebruiken als startpunt voor slimme datageneratie en augmentatiefuncties
Welk type synthetische data gebruiken?
Afhankelijk van uw use-case wordt een combinatie van dummy data / mock data, rule-based gegenereerde synthetische data of synthetische data gegenereerd door kunstmatige intelligentie (AI) geadviseerd. Dit overzicht geeft u een eerste indicatie van welk type synthetische data u kunt gebruiken. Aangezien Syntho ze allemaal ondersteunt, kunt u gerust contact opnemen met onze experts om uw use-case met ons te verdiepen.


