



Syntho bootst (gevoelige) data na met AI om synthetische data-tweelingen te genereren
Syntho maakt gebruik van geavanceerde kunstmatige intelligentie (AI) om synthetische data te creëren die gevoelige data nauwkeurig nabootsen. Ons doel is om synthetische data genereren met de hoogste nauwkeurigheid, in vergelijking met de oorspronkelijke data. Onze gebruiken Syntho Engine-software en geavanceerde machine learning-modellen, kunnen we volledig nieuwe datapunten genereren met behoud van dezelfde statistische patronen en relaties die in de oorspronkelijke data worden aangetroffen. Het resultaat zijn synthetische data die de belangrijkste kenmerken van de originele data behouden, waardoor ze niet te onderscheiden zijn van echte data, zodat ze zelfs voor analyse kunnen worden gebruikt. Daarom noemen we deze door AI gegenereerde synthetische data a synthetische data twin, omdat het “zo goed als echt is in vergelijking met de echte data. Door gebruik te maken van synthetische data-tweelingen, kunnen bedrijven tal van voordelen ontsluiten via verschillende synthetische data met toegevoegde waarde toepassingen.
Kernvraag: hoe nauwkeurig zijn de synthetische data in vergelijking met de echte data?
Deel 1
Bij Syntho begrijpen we het belang van betrouwbare en nauwkeurige data voor uw bedrijf. Daarom we bieden een uitgebreid kwaliteitsborgingsrapport voor elke synthetische datarun, dat de nauwkeurigheid van de synthetische data in vergelijking met de oorspronkelijke data aantoont. Ons kwaliteitsrapport bevat verschillende statistieken zoals distributies, correlaties, multivariate distributies, privacystatistieken en meer. Op deze manier kunt u eenvoudig beoordelen of de synthetische data die wij verstrekken van de hoogste kwaliteit zijn en met hetzelfde niveau van nauwkeurigheid en betrouwbaarheid kunnen worden gebruikt als uw oorspronkelijke data.
Deel 2
Hoewel Syntho er trots op is haar gebruikers een geavanceerd kwaliteitsborgingsrapport aan te bieden, dat automatisch wordt gegenereerd door onze Syntho Engine, begrijpen we ook het belang van een externe, objectieve evaluatie van onze synthetische data. Daarom hebben we de hulp ingeroepen van SAS, een toonaangevende data-expert, om onze synthetische data te beoordelen.
SAS voert verschillende grondige evaluaties uit op datanauwkeurigheid, privacybescherming en bruikbaarheid van Syntho's door AI gegenereerde synthetische data in vergelijking met de originele data. als conclusie, SAS de synthetische data van Syntho beoordeeld en goedgekeurd als nauwkeurig, veilig en bruikbaar in vergelijking met de oorspronkelijke data.
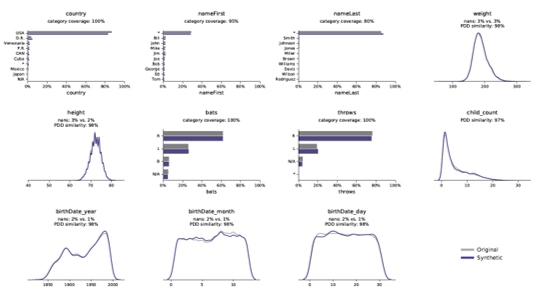
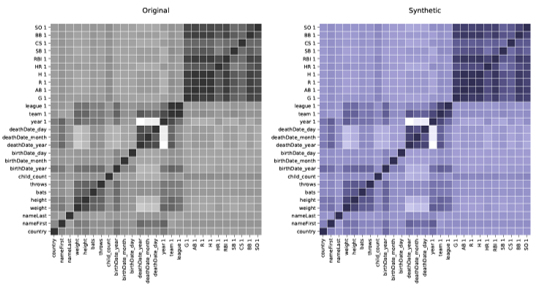
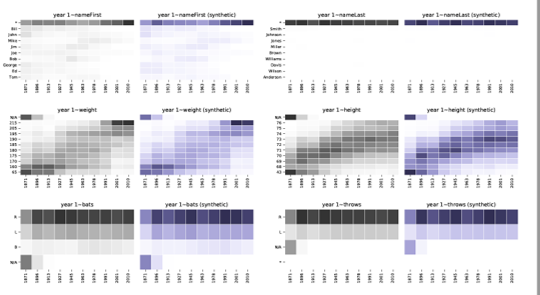
Momentopnamen uit ons rapport over synthetische datakwaliteit
Externe referenties
Voor de casus, de doeldataset was een telecom dataset. De dataset bevat 128 kolommen, waaronder één kolom die aangeeft of een klant het bedrijf heeft verlaten ('churned') of niet. Het doel van de casestudy was om de synthetische data te gebruiken om enkele modellen te trainen om klantverloop te voorspellen en om de prestaties van elk model te beoordelen. Omdat churn-voorspelling een classificatietaak is, heeft SAS vijf populaire classificatiemodellen geselecteerd om de voorspellingen te doen, waaronder:
Alvorens de synthetische data te genereren, splitste SAS de telecomdataset willekeurig op in een treinset (voor het trainen van de modellen) en een holdout-set (voor het scoren van de modellen). Het hebben van een aparte holdout-set voor scores zorgt voor een onbevooroordeelde beoordeling van hoe goed het classificatiemodel zou kunnen werken wanneer het wordt toegepast op nieuwe data.
Met het treinstel als invoer, Syntho gebruikte zijn Syntho Engine om een synthetische dataset te genereren. Voor benchmarking heeft SAS ook een geanonimiseerde versie van het treinstel gemaakt na toepassing van verschillende anonimiseringstechnieken om een bepaalde drempel (van k-anonimiteit) te bereiken. De vorige stappen resulteerden in vier datasets:
Datasets 1, 3 en 4 werden gebruikt om elk classificatiemodel te trainen, wat resulteerde in 12 (3 x 4) getrainde modellen. SAS gebruikte vervolgens de holdout-dataset om de nauwkeurigheid te meten waarmee elk model klantverloop voorspelt. De resultaten worden hieronder weergegeven, te beginnen met enkele basisstatistieken.
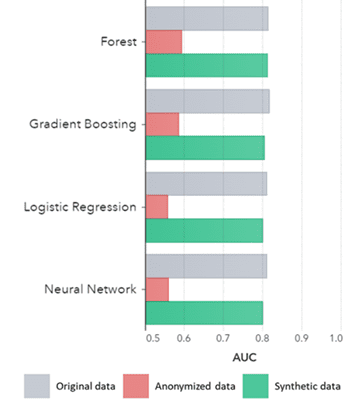
Synthetische data geldt niet alleen voor basispatronen (zoals getoond in de eerdere grafieken van het Syntho QA-rapport), het legt ook diep 'verborgen' statistische patronen vast die nodig zijn voor geavanceerde analysetaken. Dit laatste wordt gedemonstreerd in het staafdiagram, wat aangeeft dat de nauwkeurigheid van modellen die zijn getraind op synthetische data versus modellen die zijn getraind op originele data, op één lijn liggen. Verder met een oppervlakte onder de curve (AUC*) dicht bij 0.5 presteren de modellen die zijn getraind op geanonimiseerde data verreweg het slechtst. Het volledige rapport met alle advanced analytics assessments op synthetische data in vergelijking met de originele data is op aanvraag beschikbaar.
Bovendien kunnen deze synthetische data worden gebruikt om datakenmerken en hoofdvariabelen te begrijpen die nodig zijn voor daadwerkelijke training van de modellen. De invoer die door de algoritmen op synthetische data werd geselecteerd in vergelijking met de oorspronkelijke data, leek sterk op elkaar. Daarom kan het modelleringsproces op deze synthetische versie worden uitgevoerd, wat het risico op datalekken verkleint.
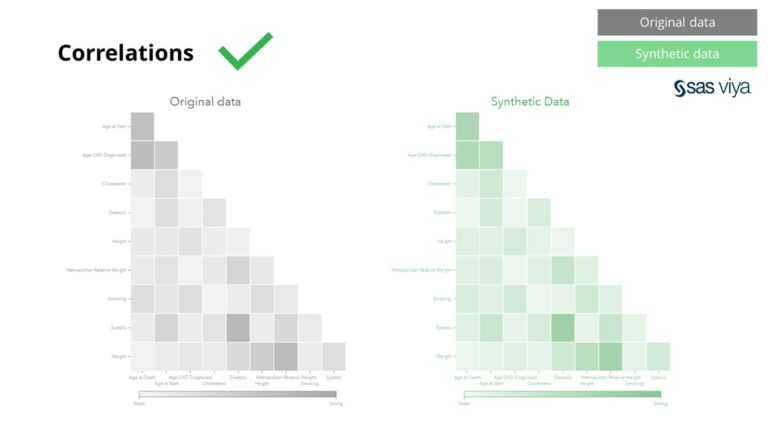
De correlaties en relaties tussen variabelen werden nauwkeurig bewaard in synthetische data.
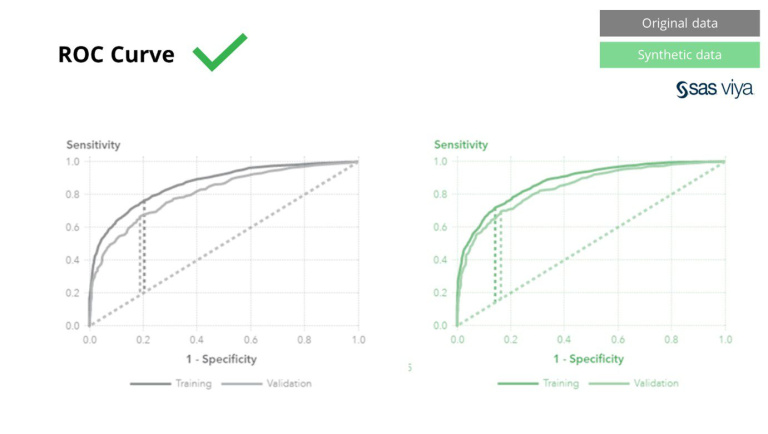
De Area Under the Curve (AUC), een maatstaf voor het meten van modelprestaties, bleef consistent.
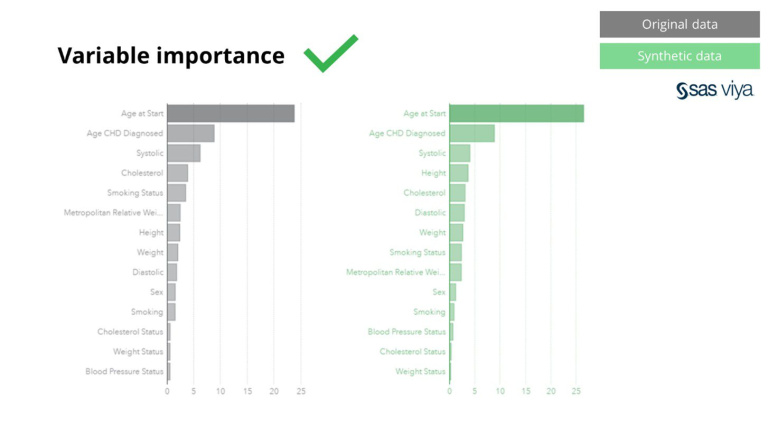
Bovendien bleef het variabele belang, dat de voorspellende kracht van variabelen in een model aangaf, intact bij het vergelijken van synthetische data met de originele dataset.
Op basis van deze waarnemingen kunnen we vol vertrouwen concluderen dat synthetische data die door de Syntho Engine in SAS Viya worden gegenereerd, qua kwaliteit inderdaad op één lijn liggen met echte data. Dit valideert het gebruik van synthetische data voor modelontwikkeling, wat de weg vrijmaakt voor kankeronderzoek gericht op het voorspellen van achteruitgang en sterfte.
