

Syntho ontwikkelt software voor door AI gegenereerde synthetische data. In tegenstelling tot het gebruik van gevoelige originele data, gebruiken klanten onze AI-software om hoogwaardige synthetische data te creëren. We genereren geheel nieuwe data, maar we zijn in staat om die nieuwe datapunten te modelleren om de kenmerken, relaties en statistische patronen van de originele data zo te behouden dat ze kunnen worden gebruikt alsof het originele data zijn. Syntho biedt voor elke gegenereerde synthetische dataset een kwaliteitsrapport aan om dit aan te tonen. Ons kwaliteitsrapport bevat verschillende basisstatistieken, waaronder aggregaten, verdelingen en correlaties, verrijkt met meer geavanceerde metingen, zoals multivariate verdelingen. Deze blog illustreert hoogtepunten uit ons datakwaliteitsrapport op basis van een case-studykwaliteit met de openbaar beschikbare Census Income Database (1994)
Deze casestudy demonstreert hoogtepunten uit ons kwaliteitsrapport, dat verschillende statistieken bevat van synthetische data die zijn gegenereerd door onze Syntho Engine in vergelijking met de originele data. We oefenen met de publiek beschikbare inkomensdataset uit de Census Income Database (1994). Deze dataset bevat verschillende persoonlijke attributen (leeftijd, opleiding, relatie etc.) verrijkt met inkomensgerelateerde data (uren per week, inkomen etc.). De verschillende categorieën uit deze oorspronkelijke dataset, aangevuld met voorbeelddatarecords, vindt u in onderstaande tabel.
De originele Census Income Database (1994)
Voorbeeld datarecords
| id | 1 | 2 | 3 |
| leeftijd | 39 | 50 | 38 |
| werkklas | staat-gov | Zelfstandig-niet-inc | Privé |
| fnlwgt | 77516 | 83311 | 215646 |
| onderwijs | Bachelors | Bachelors | HS-grad |
| opleidingsnummer | 13 | 13 | 9 |
| burgerlijke staat | Nooit getrouwd | Getrouwd-civ-echtgenoot | Gescheiden |
| bezetting | Adm-klerikaal | Executive-managerial | Handlers-reinigers |
| verwantschap | Niet-in-familie | Man | Niet-in-familie |
| race | Wit | Wit | Wit |
| geslacht | Mannelijk frezen | Mannelijk frezen | Mannelijk frezen |
| meerwaarde | 2174 | 0 | 0 |
| kapitaalverlies | 0 | 0 | 0 |
| uren per week | 40 | 13 | 40 |
| geboorteland | Verenigde Staten | Verenigde Staten | Verenigde Staten |
| inkomen | <= 50K | <= 50K | <= 50K |
| id | 1 |
| leeftijd | 39 |
| werkklas | staat-gov |
| fnlwgt | 77516 |
| onderwijs | Bachelors |
| opleidingsnummer | 9 |
| burgerlijke staat | Nooit getrouwd |
| bezetting | Adm-klerikaal |
| verwantschap | Niet-in-familie |
| race | Wit |
| geslacht | Mannelijk frezen |
| meerwaarde | 2174 |
| kapitaalverlies | 0 |
| uren per week | 40 |
| geboorteland | Verenigde Staten |
| inkomen | <= 50K |
Syntho genereert een kwaliteitsrapport voor elke gegenereerde synthetische dataset. Ons kwaliteitsrapport bevat verschillende veelvoorkomende statistieken zoals gemiddelden en verdelingen, verrijkt met meer geavanceerde statistieken, zoals correlaties en multivariate verdelingen.
Deze casestudy biedt een voorproefje van ons kwaliteitsrapport, aangezien het volledige statistische rapport vele pagina's met beschrijvende statistieken beslaat. De volledige versie van het kwaliteitsrapport voor de case study met de Census Income Database (1994) is op aanvraag verkrijgbaar via het formulier onderaan deze pagina.
Dit eerste deel van ons kwaliteitsrapport behandelt samenvattende statistieken van de originele dataset in vergelijking met de synthetische dataset gegenereerd door Syntho. Deze tabel bevat beschrijvende statistieken zoals gemiddelden, standaarddeviaties, minima, maxima en correlaties. Zoals te zien is in de onderstaande tabel, zijn samenvattende statistieken voor originele data (links) en synthetische data (rechts) bijna identiek.
Houd er ook rekening mee dat we de vereiste hoeveelheid data (aantal) kunnen afstemmen op de doelen van uw gebruiksscenario. Hoewel we adviseren om het aantal datapunten (count, N) gelijk te houden voor statistische analysedoeleinden, kunnen we een onbeperkte hoeveelheid synthetische data genereren.
Beschrijvende statistiek
Oorspronkelijke data: links – synthetische data: rechts
Originele data | Synthetische data | |||
leeftijd | kapitaalverlies | leeftijd | kapitaalverlies | |
| tellen | 32.561 | 32.561 | ∞ | ∞ |
| gemiddelde | 38,58 | 87,30 | 38,59 | 86,96 |
| Standaarddeviatie | 13,64 | 402,96 | 13,65 | 402,17 |
| Min | 17 | 0 | 17 | 0 |
| 25% | 28 | 0 | 28 | 0 |
| 50% | 37 | 0 | 37 | 0 |
| 75% | 48 | 0 | 48 | 0 |
max | 90 | 4.356 | 90 | 4.356 |
| correlatie | 0,056726 | 0,057775 | ||
| Leeftijd | ||
| ORIGINELE | Synthetisch | |
| tellen | 32.561 | ∞ |
| gemiddelde | 38,58 | 38,59 |
| Standaarddeviatie | 13,64 | 13,65 |
| Min | 17 | 17 |
| 25% | 28 | 28 |
| 50% | 37 | 37 |
| 75% | 48 | 48 |
| max | 90 | 90 |
| kapitaalverlies | ||
| ORIGINELE | Synthetisch | |
| tellen | 32.561 | ∞ |
| gemiddelde | 87,30 | 86,96 |
| Standaarddeviatie | 402,96 | 402,17 |
| Min | 0 | 0 |
| 25% | 0 | 0 |
| 50% | 0 | 0 |
| 75% | 0 | 0 |
| max | 4.356 | 4.356 |
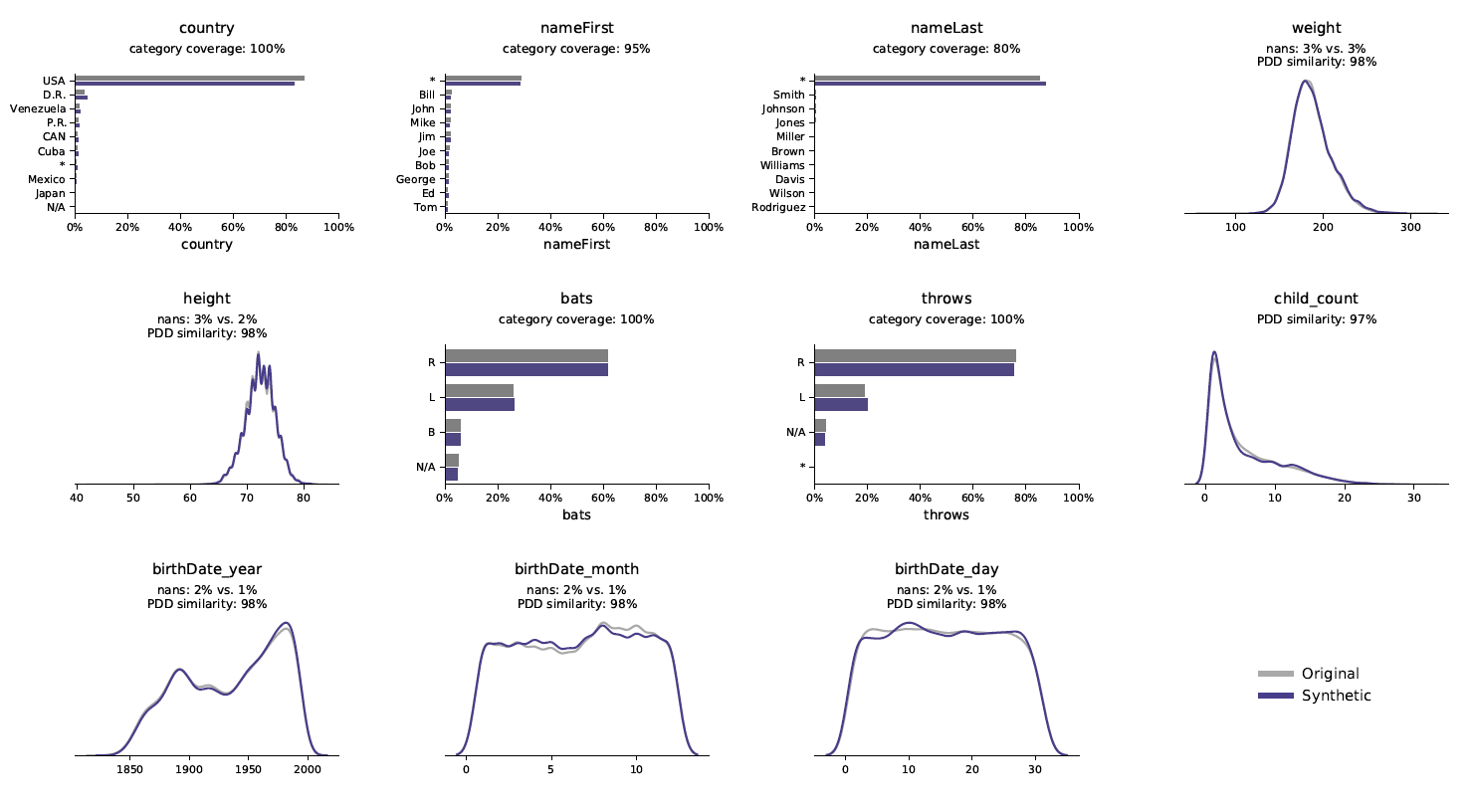
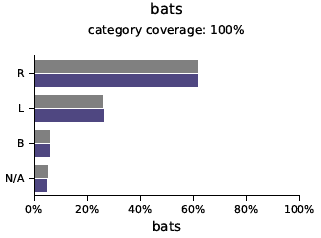
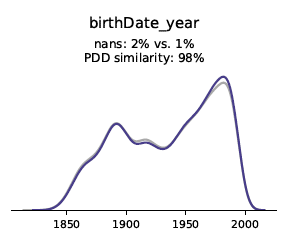
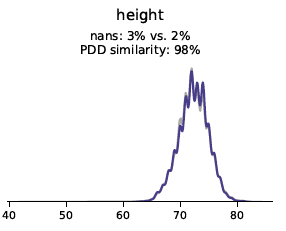
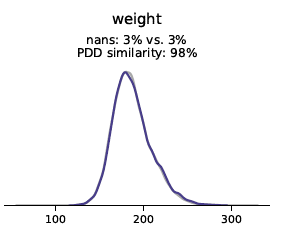
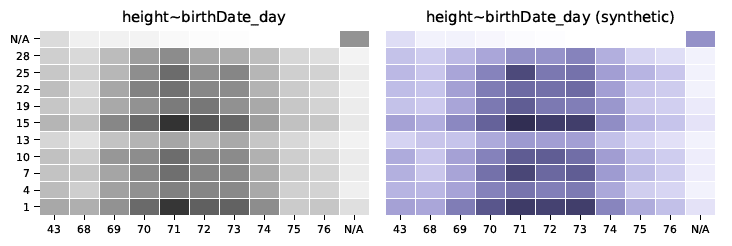
Univariate verdelingen geven inzicht in de frequentie van een bepaald datarecord voor een bepaalde categorie of waarde. Bij weergave in een grafiek kan men de frequentie van alle datarecords voor een bepaalde waarde bekijken, wat inzicht geeft in de verdeling. Zoals te zien is in de volgende grafieken, is de verdeling voor originele data (grijs) en synthetische data (blauw) bijna identiek voor de categorieën gewicht, geboortedatum, lengte (continue variabelen) en vleermuizen (categoriale variabele).
Distributies geven inzicht in de frequentie van een bepaald datarecord voor een bepaalde categorie of waarde en worden vastgelegd door de Syntho Engine.
Oorspronkelijke data: grijs – synthetische data: blauw
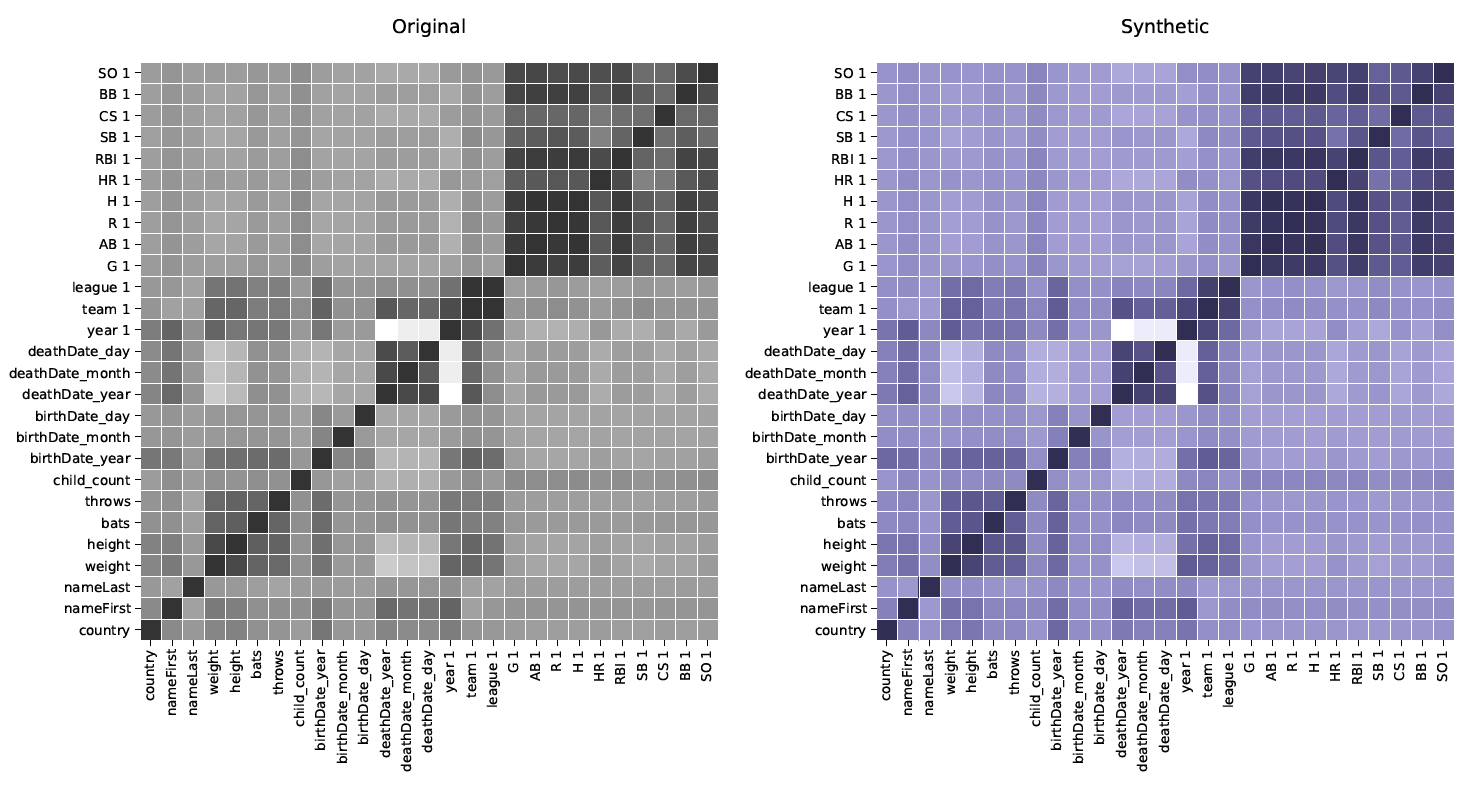
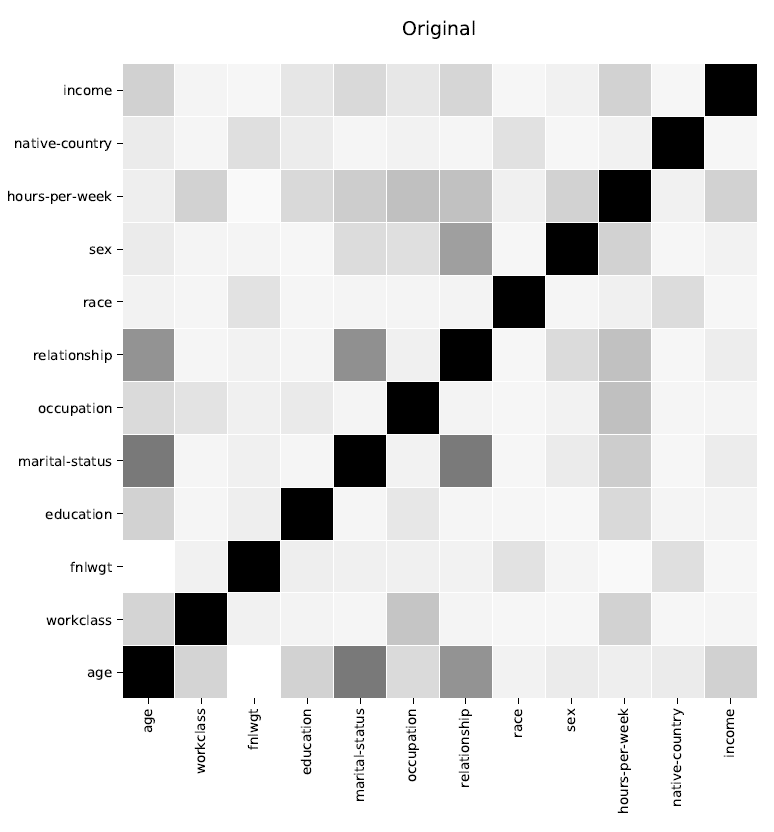
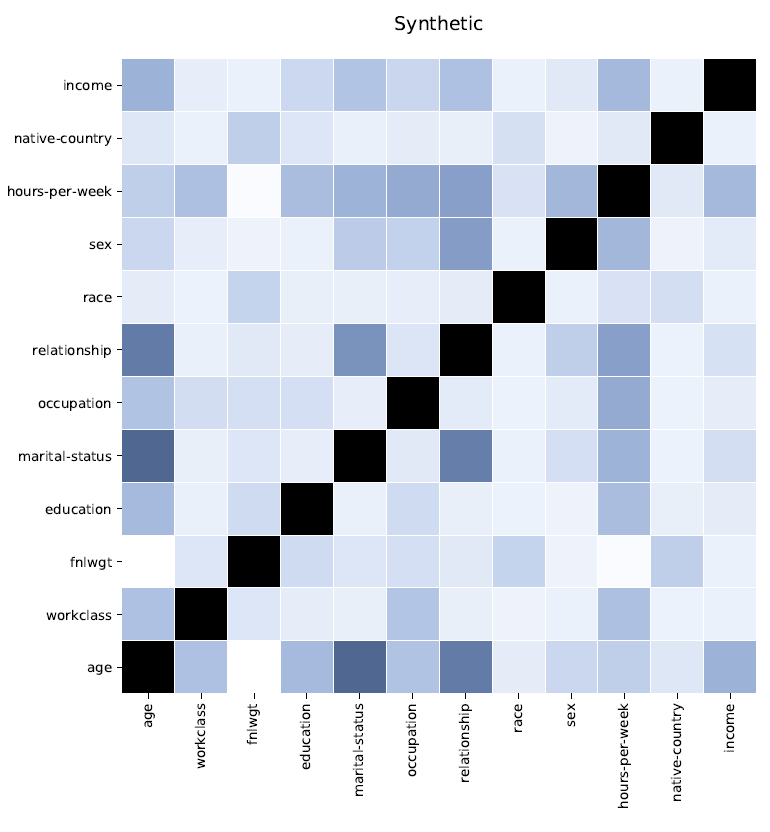
Correlaties geven inzicht in de mate waarin twee variabelen gerelateerd zijn. Weergegeven in een matrix, kan men gemakkelijk correlaties waarnemen voor elke combinatie van variabelen. Zoals te zien is in de volgende afbeelding, zijn de matrix voor originele data (grijs) en de matrix voor synthetische data (blauw) bijna identiek voor alle combinaties van categorieën uit de Census Income Database (1994).
Correlaties geven inzicht in de mate waarin twee variabelen gerelateerd zijn en worden vastgelegd door de Syntho Engine.
Oorspronkelijke data: links in grijs – synthetische data: rechts in blauw
Waar univariate distributies en correlaties inzicht geven in de distributies en relaties voor enkele categorieën, bieden multivariate distributies inzicht voor combinaties van categorieën en worden ze ook vastgelegd door de Syntho Engine.
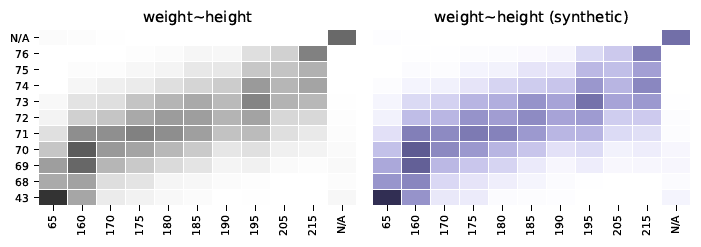
Als voorbeeld geven we je het resultaat van de bivariate verdeling die inzicht geeft in de frequentie van een combinatie van datarecords voor twee gegeven categorieën. Wanneer weergegeven in een matrix, kan men de frequentie van alle mogelijke combinaties van datarecords voor twee categorieën bekijken. Zoals te zien is in de volgende matrices, zijn de matrix voor originele data (grijs) en de matrix voor synthetische data (blauw) bijna identiek voor alle mogelijke combinaties van datarecords voor de categorieën [lengte – geboortedatum] en [gewicht – lengte] .
Multivariate distributies en correlaties geven inzicht in combinaties van categorieën en worden ook vastgelegd door de Syntho Engine.
Oorspronkelijke data: links in grijs – synthetische data: rechts in blauwcq
Aangezien voor elke combinatie van categorieën multivariate correlaties en verdelingen kunnen worden berekend, levert deze oefening veel grafieken op. Zoals geïllustreerd, geven we in deze verkorte versie van het kwaliteitsrapport alleen de bivariate verdeling tussen leeftijd en opleiding en delen we graag onze volledige versie van deze Census Income Database (1994) case study.
De Syntho Engine legt ook diepere, 'verborgen' relaties vast, behalve multivariate correlaties en bivariate distributies. We evalueren deze door een ingebouwd mechanisme in onze Syntho Engine dat de nauwkeurigheid evalueert van een machine learning-model dat is getraind om onderscheid te maken tussen echte en synthetische data. Experimenten tonen aan dat zelfs modellen voor machinaal leren nauwelijks originele data van synthetische data kunnen onderscheiden. Deze resultaten zijn niet alleen een van de interessante elementen in ons kwaliteitsrapport, ze zijn ook de belangrijkste prestatiemaatstaf die Syntho gebruikt voor de optimalisatie van de Syntho Engine.
Omdat alle diepe 'verborgen' relaties van de data binnen synthetische data worden bewaard, kan deze worden gebruikt als een volledige vervanging voor de originele data in machine learning-taken. Als voorbeeld zullen we opnieuw de Census-dataset gebruiken, laten we zeggen dat u het inkomen van een persoon wilt voorspellen gezien zijn andere kenmerk. Als we nu de nauwkeurigheid testen op een afzonderlijke hold-testset voor twee machine learning-modellen, één getraind op de originele data en de andere getraind op de synthetische data, wordt een nauwkeurigheidsverlies van minder dan 2% waargenomen. Dit toont aan dat synthetische data statistische eigenschappen behouden in die mate dat het, zelfs bij machine learning-taken, een superieur alternatief biedt voor echte data.
Wij streven naar maximale datakwaliteit. Daarom evalueren data analytics experts van SAS (marktleider in analytics) naast ons eigen kwaliteitsrapport regelmatig gegenereerde synthetische datasets van Syntho via verschillende analytics (Artificial Intelligence, Business Intelligence, modellering, algoritme training etc.) assessments en zullen on-demand voor u beschikbaar zijn. Dit doen we omdat we u graag inzicht willen geven in onze superieure datakwaliteit, maar niet alleen vanuit het oogpunt van de generator of synthetische data (Syntho), maar ook vanuit en extern en objectief oogpunt (in dit geval SAS, marktleider in analyse).
Die resultaten zijn op aanvraag beschikbaar. Daarnaast zullen we een webinar organiseren met SAS, waar de analyse-experts hun resultaten met u zullen delen.
SAS: www.sas.com