Raad eens wie? 5 voorbeelden waarom namen verwijderen geen optie is



Raad eens wie? Hoewel ik zeker weet dat de meesten van jullie dit spel van vroeger kennen, hier een korte samenvatting. Het doel van het spel: ontdek de naam van het stripfiguur dat door je tegenstander is geselecteerd door 'ja' en 'nee' vragen te stellen, zoals 'draagt de persoon een hoed?' of 'draagt de persoon een bril'? Spelers elimineren kandidaten op basis van de reactie van de tegenstander en leren attributen die betrekking hebben op het mysterieuze karakter van hun tegenstander. De eerste speler die het mysterieuze personage van de andere speler ontcijfert, wint het spel.
Jij hebt het. Men moet het individu uit een dataset identificeren door alleen toegang te hebben tot de bijbehorende attributen. In feite zien we dit concept van Guess Who regelmatig toegepast in de praktijk, maar dan toegepast op datasets die zijn opgemaakt met rijen en kolommen die attributen van echte mensen bevatten. Het belangrijkste verschil bij het werken met data is dat mensen de neiging hebben om het gemak te onderschatten waarmee echte individuen kunnen worden ontmaskerd door toegang te hebben tot slechts een paar attributen.
Zoals het Guess Who-spel illustreert, kan iemand individuen identificeren door toegang te hebben tot slechts een paar attributen. Het dient als een eenvoudig voorbeeld van waarom het verwijderen van alleen 'namen' (of andere directe identifiers) uit uw dataset als anonimiseringstechniek niet werkt. In deze blog geven we vier praktijkvoorbeelden om u te informeren over de privacyrisico's van het verwijderen van kolommen als middel voor dataanonimisering.
Het risico van een koppelingsaanval is de belangrijkste reden waarom het alleen verwijderen van namen niet (meer) werkt als methode voor anonimisering. Bij een koppelingsaanval combineert de aanvaller de originele data met andere toegankelijke databronnen om een individu uniek te identificeren en (vaak gevoelige) informatie over deze persoon te verkrijgen.
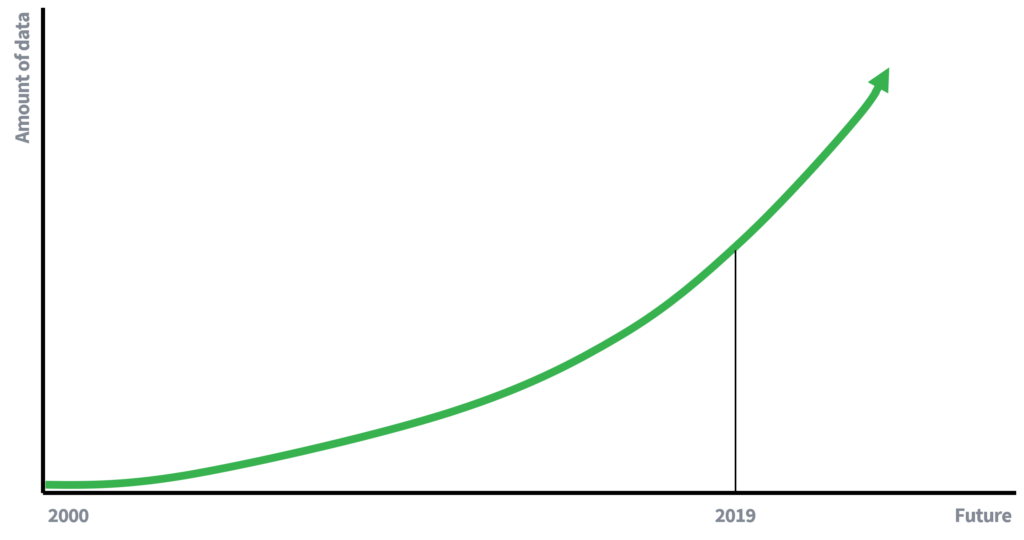
Sleutel hierbij is de beschikbaarheid van andere databronnen die nu aanwezig zijn, of in de toekomst aanwezig kunnen worden. Denk aan jezelf. Hoeveel van uw eigen persoonlijke data zijn te vinden op Facebook, Instagram of LinkedIn die mogelijk kunnen worden misbruikt voor een koppelingsaanval?
Vroeger was de beschikbaarheid van data veel beperkter, wat mede verklaart waarom het verwijderen van namen voldoende was om de privacy van personen te vrijwaren. Minder beschikbare data betekent minder mogelijkheden om data te koppelen. We zijn nu echter (actieve) deelnemer in een datagedreven economie, waar de hoeveelheid data exponentieel groeit. Meer data en verbeterde technologie voor het verzamelen van data zullen leiden tot een groter potentieel voor koppelingsaanvallen. Wat zou men over 10 jaar schrijven over het risico van een koppelingsaanval?
Afbeelding 1
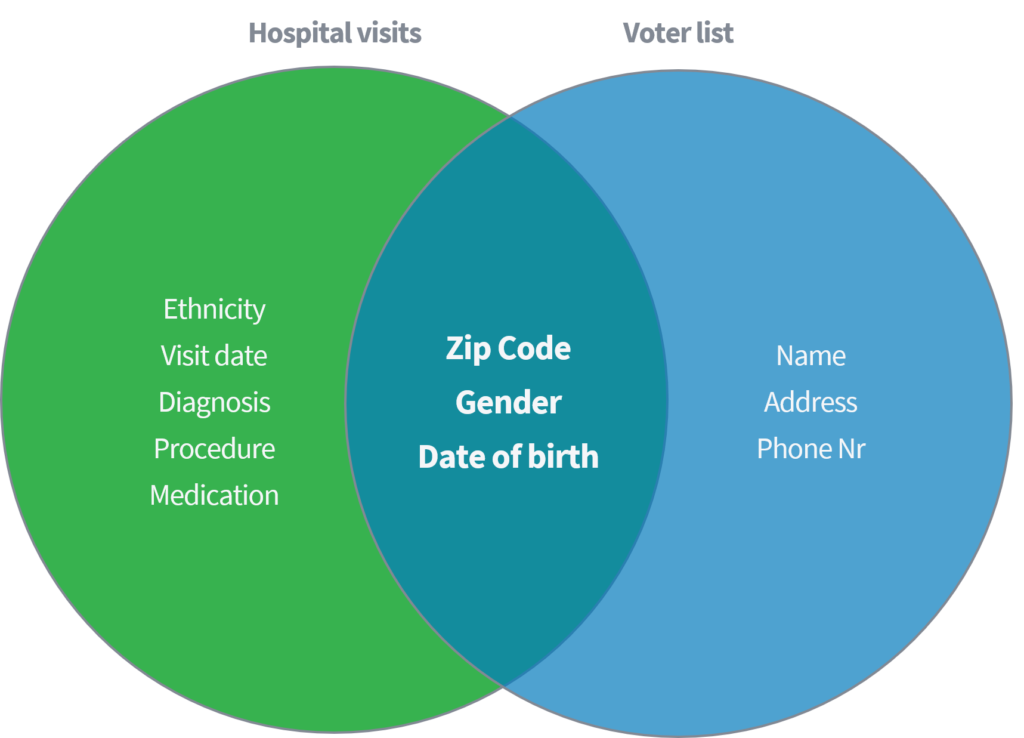
Sweeney (2002) demonstreerde in een academische paper hoe ze in staat was om gevoelige medische data van individuen te identificeren en op te halen door een openbaar beschikbare dataset van 'ziekenhuisbezoeken' te koppelen aan de publiek beschikbare stemregistrar in de Verenigde Staten. Beide datasets werden verondersteld correct te zijn geanonimiseerd door het verwijderen van namen en andere directe identifiers.
Afbeelding 2
Op basis van alleen de drie parameters (1) postcode, (2) geslacht en (3) geboortedatum, toonde ze aan dat 87% van de gehele Amerikaanse bevolking opnieuw kon worden geïdentificeerd door bovengenoemde kenmerken uit beide datasets te matchen. Sweeney herhaalde vervolgens haar werk met 'land' als alternatief voor 'postcode'. Bovendien toonde ze aan dat 18% van de gehele Amerikaanse bevolking alleen geïdentificeerd kon worden door toegang te hebben tot een dataset met informatie over (1) thuisland, (2) geslacht en (3) geboortedatum. Denk aan de eerder genoemde openbare bronnen, zoals Facebook, LinkedIn of Instagram. Zijn uw land, geslacht en geboortedatum zichtbaar of kunnen andere gebruikers dit aftrekken?
Afbeelding 3
| Quasi-ID's | % uniek geïdentificeerd van de Amerikaanse bevolking (248 miljoen) |
| 5-cijferige ZIP, geslacht, geboortedatum | 87% |
| plaats, geslacht, geboortedatum | 53% |
| Land, geslacht, geboortedatum | 18% |
Dit voorbeeld laat zien dat het opmerkelijk eenvoudig kan zijn om individuen te de-anonimiseren in schijnbaar anonieme data. Ten eerste wijst deze studie op een enorme omvang van het risico, zoals: 87% van de Amerikaanse bevolking kan gemakkelijk worden geïdentificeerd met behulp van paar kenmerken. Ten tweede waren de blootgestelde medische data in deze studie zeer gevoelig. Voorbeelden van data van blootgestelde personen uit de dataset over ziekenhuisbezoeken zijn etniciteit, diagnose en medicatie. Eigenschappen die men liever geheim houdt, bijvoorbeeld voor verzekeringsmaatschappijen.
Een ander risico van het verwijderen van alleen directe identifiers, zoals namen, doet zich voor wanneer geïnformeerde individuen superieure kennis of informatie hebben over eigenschappen of gedrag van specifieke individuen in de dataset. Op basis van hun kennis kan de aanvaller vervolgens specifieke datarecords koppelen aan echte personen.
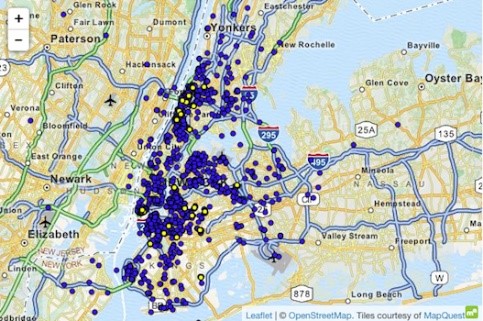
Een voorbeeld van een aanval op een dataset met behulp van superieure kennis is de taxizaak New York, waarbij Atockar (2014) specifieke individuen wist te ontmaskeren. De gebruikte dataset bevatte alle taxiritten in New York, verrijkt met basisattributen zoals startcoördinaten, eindcoördinaten, prijs en tip van de rit.
Een geïnformeerd persoon die New York kent, kon taxiritten afleiden naar de volwassenenclub 'Hustler'. Door de 'eindlocatie' te filteren, herleidde hij de exacte startadressen en identificeerde daarmee verschillende frequente bezoekers. Evenzo zou men taxiritten kunnen afleiden wanneer het huisadres van de persoon bekend was. De tijd en locatie van verschillende filmsterren van beroemdheden werden ontdekt op roddelsites. Na het koppelen van deze informatie aan de taxidata van NYC was het eenvoudig om hun taxiritten af te leiden, het bedrag dat ze betaalden en of ze een fooi hadden gegeven.
Afbeelding 4
drop-off coördinaten Hustler
Bradley Cooper
Jessica Alba
Een veelgehoorde argumentatie is 'deze data zijn waardeloos' of 'niemand kan iets met deze data'. Dit is vaak een misvatting. Zelfs de meest onschuldige data kunnen een unieke 'vingerafdruk' vormen en worden gebruikt om individuen opnieuw te identificeren. Het is het risico dat voortvloeit uit de overtuiging dat de data zelf waardeloos zijn, terwijl dat niet zo is.
Het risico van identificatie zal toenemen met de toename van data, AI en andere tools en algoritmen die het mogelijk maken om complexe relaties in data bloot te leggen. Dus zelfs als uw dataset nu niet kan worden ontdekt en vandaag vermoedelijk nutteloos is voor onbevoegden, is het misschien niet morgen.
Een goed voorbeeld is het geval waarin Netflix van plan was zijn R&D-afdeling te crowdsourcen door een open Netflix-competitie te introduceren om hun filmaanbevelingssysteem te verbeteren. 'Degene die het collaboratieve filteralgoritme verbetert om gebruikersbeoordelingen voor films te voorspellen, wint een prijs van US $ 1,000,000'. Om de crowd te steunen, publiceerde Netflix een dataset met alleen de volgende basisattributen: userID, film, datum van graad en graad (dus geen verdere informatie over de gebruiker of film zelf).
Afbeelding 5
| Gebruikers-ID | Film | Datum van cijfer | Rang |
| 123456789 | Missie onmogelijk | 10-12-2008 | 4 |
Afzonderlijk leken de data zinloos. Op de vraag 'Is er klantinformatie in de dataset die privé moet worden gehouden?', was het antwoord:
'Nee, alle klantidentificerende informatie is verwijderd; het enige dat overblijft zijn beoordelingen en datums. Dit volgt ons privacybeleid …'
Narayanan (2008) van de Universiteit van Texas in Austin bewees echter het tegendeel. De combinatie van cijfers, cijferdatum en film van een individu vormt een unieke filmvingerafdruk. Denk na over je eigen Netflix-gedrag. Hoeveel mensen denk je dat naar dezelfde reeks films hebben gekeken? Hoeveel hebben tegelijkertijd dezelfde reeks films bekeken?
Hoofdvraag, hoe deze vingerafdruk te matchen? Het was best simpel. Op basis van informatie van de bekende filmbeoordelingswebsite IMDb (Internet Movie Database) zou een vergelijkbare vingerafdruk kunnen worden gevormd. Hierdoor kunnen personen opnieuw worden geïdentificeerd.
Hoewel het kijken naar films misschien niet als gevoelige informatie wordt beschouwd, moet u eens nadenken over uw eigen gedrag - zou u het erg vinden als het openbaar zou worden gemaakt? Voorbeelden die Narayanan in zijn paper gaf, zijn politieke voorkeuren (beoordelingen op 'Jesus of Nazareth' en 'The Gospel of John') en seksuele voorkeuren (beoordelingen op 'Bent' en 'Queer as folk') die gemakkelijk kunnen worden gedestilleerd.
GDPR is misschien niet superspannend, noch de zilveren kogel onder blogonderwerpen. Toch is het handig om de definities op een rij te krijgen bij het verwerken van persoonsdata. Aangezien deze blog gaat over de veelvoorkomende misvatting over het verwijderen van kolommen als een manier om data te anonimiseren en om u als dataverwerker op te leiden, laten we beginnen met het onderzoeken van de definitie van anonimisering volgens de AVG.
Volgens overweging 26 van de AVG wordt geanonimiseerde informatie gedefinieerd als:
'informatie die geen betrekking heeft op een geïdentificeerde of identificeerbare natuurlijke persoon of persoonsdata die zodanig zijn geanonimiseerd dat de betrokkene niet (meer) identificeerbaar is.'
Aangezien men persoonsdata verwerkt die betrekking hebben op een natuurlijke persoon, is alleen deel 2 van de definitie relevant. Om aan de definitie te voldoen moet men ervoor zorgen dat de betrokkene (individu) niet (meer) identificeerbaar is. Zoals in deze blog is aangegeven, is het echter opmerkelijk eenvoudig om individuen te identificeren op basis van enkele kenmerken. Het verwijderen van namen uit een dataset voldoet dus niet aan de AVG-definitie van anonimisering.
We hebben een algemeen overwogen en helaas nog steeds veel toegepaste benadering van dataanonimisering ter discussie gesteld: het verwijderen van namen. In het Guess Who-spel en vier andere voorbeelden over:
er werd aangetoond dat het verwijderen van namen mislukt als anonimisering. Hoewel de voorbeelden opvallende gevallen zijn, toont elk de eenvoud van heridentificatie en de mogelijke negatieve impact op de privacy van individuen.
Kortom, het verwijderen van namen uit uw dataset resulteert niet in anonieme data. Daarom kunnen we beter vermijden om beide termen door elkaar te gebruiken. Ik hoop oprecht dat u deze benadering niet zult toepassen voor anonimisering. En als u dat nog steeds doet, zorg er dan voor dat u en uw team de privacyrisico's volledig begrijpen en deze risico's namens de betrokken personen mogen aanvaarden.
Neem contact op met Syntho en een van onze experts neemt razendsnel contact met je op om de waarde van synthetische data te onderzoeken!