رازداری کے تحفظ کی تعمیل کے لیے ڈیٹا کی گمنامی کے بہترین ٹولز
تنظیمیں ہٹانے کے لیے ڈیٹا کی گمنامی کے ٹولز کا استعمال کرتی ہیں۔ ذاتی طور پر شناختی معلومات ان کے ڈیٹاسیٹس سے۔ عدم تعمیل ریگولیٹری اداروں کی طرف سے بھاری جرمانے کا باعث بن سکتی ہے۔ ڈیٹا کی خلاف ورزی. بغیر گمنام ڈیٹا، آپ ڈیٹاسیٹس کو مکمل طور پر استعمال یا اشتراک نہیں کرسکتے ہیں۔
بہت گمنام ٹولز مکمل تعمیل کی ضمانت نہیں دے سکتا۔ پچھلی نسل کے طریقے ذاتی معلومات کو نقصان دہ اداکاروں کے ذریعے شناخت نہ کرنے کے لیے خطرے میں ڈال سکتے ہیں۔ کچھ شماریاتی گمنامی کے طریقے ڈیٹاسیٹ کے معیار کو اس مقام تک کم کر دیں جب یہ قابل اعتبار نہ ہو۔ ڈیٹا تجزیات.
ہم کم سنتو۔ آپ کو گمنامی کے طریقوں اور past-gen اور Next-gen ٹولز کے درمیان کلیدی فرق سے متعارف کرائے گا۔ ہم آپ کو ڈیٹا کی گمنامی کے بہترین ٹولز کے بارے میں بتائیں گے اور ان کو منتخب کرنے کے لیے اہم نکات تجویز کریں گے۔
کی میز کے مندرجات
- مصنوعی ڈیٹا کیا ہے؟
- یہ کیسے کام کرتا ہے
- تنظیمیں اسے کیوں استعمال کرتی ہیں۔
- کس طرح شروع کرنا

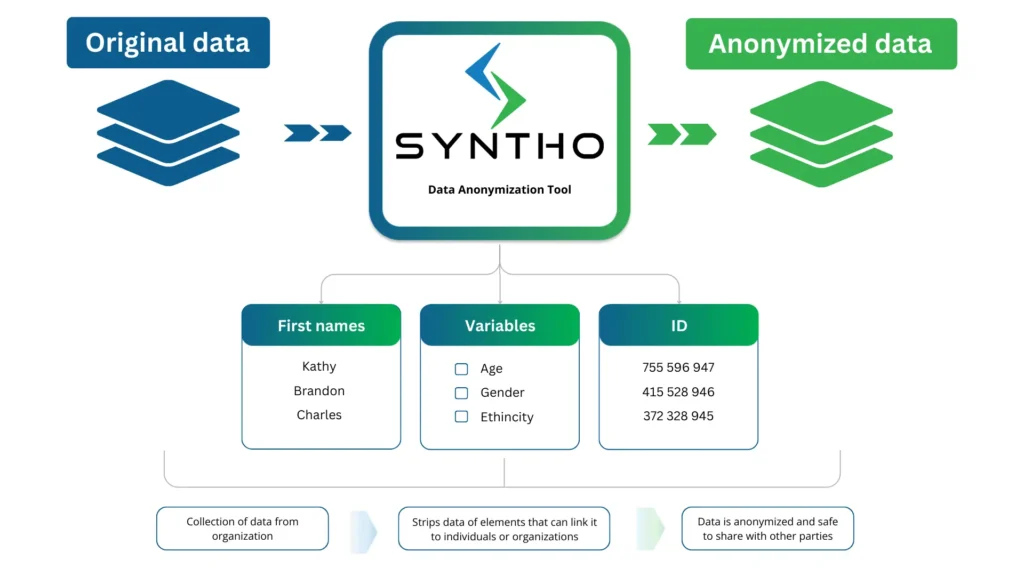
ڈیٹا گمنامی ٹولز کیا ہیں؟
ڈیٹا کی گمنامی ڈیٹا سیٹس میں موجود خفیہ معلومات کو ہٹانے یا تبدیل کرنے کی تکنیک ہے۔ تنظیمیں آزادانہ طور پر دستیاب ڈیٹا تک رسائی، اشتراک اور استعمال نہیں کر سکتیں جس کا براہ راست یا بالواسطہ طور پر افراد تک پتہ لگایا جا سکتا ہے۔
- عام ڈیٹا تحفظ ریگولیشن (جی ڈی پی آر). یورپی یونین کی قانون سازی ذاتی ڈیٹا کی رازداری کی حفاظت کرتا ہے، ڈیٹا پروسیسنگ کے لیے رضامندی کو لازمی قرار دیتا ہے اور افراد کو ڈیٹا تک رسائی کے حقوق دیتا ہے۔ برطانیہ میں بھی اسی طرح کا ایک قانون ہے جسے UK-GDPR کہتے ہیں۔
- کیلیفورنیا کنزیومر پرائیویسی ایکٹ (CCPA)۔ کیلیفورنیا کا رازداری کا قانون کے بارے میں صارفین کے حقوق پر توجہ مرکوز کرتا ہے۔ ڈیٹا شیئرنگ.
- ہیلتھ انشورنس پورٹیبلٹی اینڈ احتساب ایکٹ (HIPAA)۔ رازداری کا اصول۔ مریض کی صحت کی معلومات کے تحفظ کے لیے معیارات قائم کرتا ہے۔
ڈیٹا گمنامی کے ٹولز کیسے کام کرتے ہیں؟
ڈیٹا گمنامی ٹولز حساس معلومات کے لیے ڈیٹا سیٹس کو اسکین کرتے ہیں اور انہیں مصنوعی ڈیٹا سے بدل دیتے ہیں۔ سافٹ ویئر اس طرح کے ڈیٹا کو ٹیبلز اور کالمز، ٹیکسٹ فائلز اور اسکین شدہ دستاویزات میں تلاش کرتا ہے۔
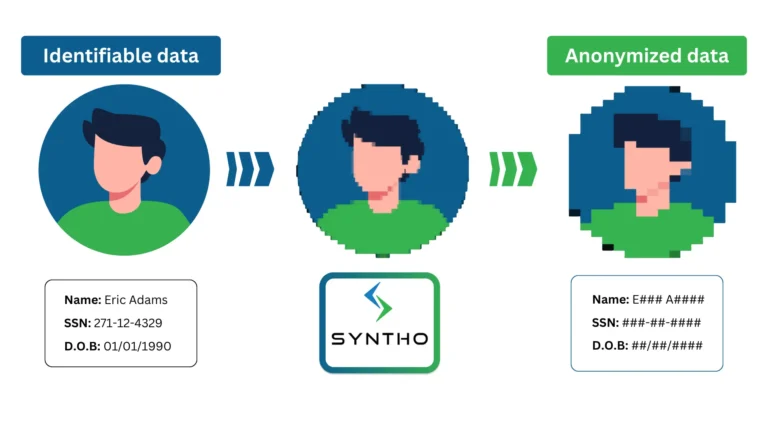
یہ عمل ان عناصر کے ڈیٹا کو ہٹا دیتا ہے جو اسے افراد یا تنظیموں سے جوڑ سکتے ہیں۔ ان ٹولز کے ذریعے غیر واضح ڈیٹا کی اقسام میں شامل ہیں:
- ذاتی طور پر قابل شناخت معلومات (PII): نام، شناختی نمبر، تاریخ پیدائش، بلنگ کی تفصیلات، فون نمبر، اور ای میل پتے۔
- محفوظ صحت کی معلومات (PHI): طبی ریکارڈ، ہیلتھ انشورنس کی تفصیلات، اور ذاتی صحت کے ڈیٹا کا احاطہ کرتا ہے۔
- مالی معلومات: کریڈٹ کارڈ نمبر، بینک اکاؤنٹ کی تفصیلات، سرمایہ کاری کا ڈیٹا، اور دیگر جو کارپوریٹ اداروں سے منسلک ہو سکتے ہیں۔
مثال کے طور پر، صحت کی دیکھ بھال کرنے والی تنظیمیں کینسر کی تحقیق کے لیے HIPAA کی تعمیل کو یقینی بنانے کے لیے مریضوں کے پتے اور رابطے کی تفصیلات کو گمنام کرتی ہیں۔ ایک فنانس کمپنی نے GDPR قوانین کی پابندی کرنے کے لیے اپنے ڈیٹا سیٹس میں لین دین کی تاریخوں اور مقامات کو چھپا دیا۔
جبکہ تصور ایک ہی ہے، اس کے لیے کئی الگ تکنیکیں موجود ہیں۔ گمنام ڈیٹا.
ڈیٹا گمنامی کی تکنیک
گمنامی کئی طریقوں سے ہوتی ہے، اور تمام طریقے تعمیل اور افادیت کے لیے یکساں طور پر قابل اعتماد نہیں ہوتے۔ یہ سیکشن مختلف اقسام کے طریقوں کے درمیان فرق کو بیان کرتا ہے۔
تخلص۔
تخلص ایک الٹ جانے والا غیر شناختی عمل ہے جہاں ذاتی شناخت کنندگان کو تخلص کے ساتھ تبدیل کیا جاتا ہے۔ یہ اصل ڈیٹا اور تبدیل شدہ ڈیٹا کے درمیان میپنگ کو برقرار رکھتا ہے، میپنگ ٹیبل کو الگ سے محفوظ کیا جاتا ہے۔
تخلص کا منفی پہلو یہ ہے کہ یہ الٹنے والا ہے۔ اضافی معلومات کے ساتھ، بدنیتی پر مبنی اداکار اسے فرد تک واپس لے سکتے ہیں۔ GDPR کے قوانین کے تحت، تخلص والے ڈیٹا کو گمنام ڈیٹا نہیں سمجھا جاتا ہے۔ یہ ڈیٹا کے تحفظ کے ضوابط کے تابع رہتا ہے۔
ڈیٹا ماسکنگ
ڈیٹا ماسکنگ کا طریقہ حساس معلومات کی حفاظت کے لیے ان کے ڈیٹا کا ساختی طور پر ملتا جلتا لیکن جعلی ورژن بناتا ہے۔ یہ تکنیک اصلی ڈیٹا کو تبدیل شدہ حروف سے بدل دیتی ہے، عام استعمال کے لیے ایک ہی فارمیٹ کو برقرار رکھتے ہوئے۔ نظریہ میں، یہ ڈیٹا سیٹس کی آپریشنل فعالیت کو برقرار رکھنے میں مدد کرتا ہے۔
پریکٹس میں، ماسکنگ ڈیٹا اکثر کم کر دیتا ہے ڈیٹا افادیت. یہ محفوظ کرنے میں ناکام ہو سکتا ہے۔ اصل ڈیٹاکی تقسیم یا خصوصیات، اسے تجزیہ کے لیے کم مفید بناتی ہے۔ ایک اور چیلنج یہ فیصلہ کر رہا ہے کہ کس چیز کو ماسک کرنا ہے۔ اگر غلط طریقے سے کیا جاتا ہے تو، نقاب پوش ڈیٹا کی دوبارہ شناخت کی جا سکتی ہے۔
عام کرنا (مجموعہ)
جنرلائزیشن ڈیٹا کو کم تفصیلی بنا کر گمنام کر دیتی ہے۔ یہ ایک جیسے ڈیٹا کو ایک ساتھ گروپ کرتا ہے اور اس کے معیار کو کم کرتا ہے، جس سے ڈیٹا کے انفرادی ٹکڑوں کو الگ بتانا مشکل ہو جاتا ہے۔ اس طریقہ کار میں اکثر ڈیٹا کا خلاصہ کرنے کے طریقے شامل ہوتے ہیں جیسے کہ انفرادی ڈیٹا پوائنٹس کی حفاظت کے لیے اوسط یا مجموعی کرنا۔
حد سے زیادہ عام کرنا ڈیٹا کو تقریباً بیکار بنا سکتا ہے، جبکہ انڈر جنرلائزیشن کافی پرائیویسی پیش نہیں کر سکتی۔ بقایا افشاء کا خطرہ بھی ہے، کیونکہ جمع شدہ ڈیٹاسیٹس اب بھی دیگر کے ساتھ مل کر کافی تفصیل سے ڈی-شناخت فراہم کر سکتے ہیں اعداد و شمار ذرائع.
گڑبڑ
گڑبڑ قدروں کو جمع کرکے اور بے ترتیب شور کو شامل کرکے اصل ڈیٹاسیٹس میں ترمیم کرتی ہے۔ ڈیٹا پوائنٹس کو ٹھیک طریقے سے تبدیل کیا جاتا ہے، مجموعی ڈیٹا پیٹرن کو برقرار رکھتے ہوئے ان کی اصل حالت میں خلل پڑتا ہے۔
پریشان ہونے کا منفی پہلو یہ ہے کہ ڈیٹا مکمل طور پر گمنام نہیں ہے۔ اگر تبدیلیاں کافی نہیں ہیں، تو اس بات کا خطرہ ہے کہ اصل خصوصیات کی دوبارہ شناخت کی جا سکتی ہے۔
ڈیٹا کی تبدیلی
سویپنگ ایک تکنیک ہے جہاں ڈیٹاسیٹ میں انتساب کی قدروں کو دوبارہ ترتیب دیا جاتا ہے۔ یہ طریقہ خاص طور پر لاگو کرنے کے لئے آسان ہے. حتمی ڈیٹاسیٹس اصل ریکارڈ سے مطابقت نہیں رکھتے اور اپنے اصل ذرائع سے براہ راست سراغ نہیں پاتے۔
بالواسطہ طور پر، تاہم، ڈیٹاسیٹس الٹ سکتے ہیں۔ تبدیل شدہ ڈیٹا محدود ثانوی ذرائع کے باوجود بھی انکشاف کے لیے خطرناک ہے۔ اس کے علاوہ، کچھ تبدیل شدہ ڈیٹا کی معنوی سالمیت کو برقرار رکھنا مشکل ہے۔ مثال کے طور پر، ڈیٹا بیس میں ناموں کو تبدیل کرتے وقت، نظام مرد اور عورت کے ناموں میں فرق کرنے میں ناکام ہو سکتا ہے۔
ٹوکن بنانا
ٹوکنائزیشن حساس اعداد و شمار کے عناصر کو ٹوکنز سے بدل دیتی ہے — استحصالی اقدار کے بغیر غیر حساس مساوی۔ ٹوکنائزڈ معلومات عام طور پر نمبروں اور حروف کی ایک بے ترتیب تار ہوتی ہے۔ یہ تکنیک اکثر مالی معلومات کی حفاظت کے لیے استعمال کی جاتی ہے جبکہ اس کی فعال خصوصیات کو برقرار رکھا جاتا ہے۔
کچھ سافٹ ویئر ٹوکن والٹس کا انتظام اور اسکیل کرنا مشکل بنا دیتا ہے۔ یہ سسٹم ایک سیکورٹی رسک بھی متعارف کراتا ہے: اگر کوئی حملہ آور انکرپشن والٹ سے گزرتا ہے تو حساس ڈیٹا خطرے میں پڑ سکتا ہے۔
randomization ہے
رینڈمائزیشن بے ترتیب اور فرضی ڈیٹا کے ساتھ اقدار کو تبدیل کرتی ہے۔ یہ ایک سیدھا سادا طریقہ ہے جو انفرادی ڈیٹا کے اندراجات کی رازداری کو محفوظ رکھنے میں مدد کرتا ہے۔
اگر آپ درست شماریاتی تقسیم کو برقرار رکھنا چاہتے ہیں تو یہ تکنیک کام نہیں کرتی۔ پیچیدہ ڈیٹا سیٹس، جیسے جغرافیائی یا وقتی ڈیٹا کے لیے استعمال کیے جانے والے ڈیٹا سے سمجھوتہ کرنے کی ضمانت ہے۔ ناکافی یا غلط طریقے سے لاگو بے ترتیب طریقے رازداری کے تحفظ کو یقینی نہیں بنا سکتے۔
ڈیٹا کی اصلاح
ڈیٹا ریڈیکشن ڈیٹا سیٹس سے معلومات کو مکمل طور پر ہٹانے کا عمل ہے: متن اور تصاویر کو بلیک آؤٹ کرنا، خالی کرنا یا مٹانا۔ یہ حساس تک رسائی کو روکتا ہے۔ پروڈکشن ڈیٹا اور قانونی اور سرکاری دستاویزات میں ایک عام عمل ہے۔ یہ بالکل واضح ہے کہ یہ اعداد و شمار کو درست شماریاتی تجزیات، ماڈل سیکھنے، اور طبی تحقیق کے لیے نااہل بنا دیتا ہے۔
جیسا کہ واضح ہے، ان تکنیکوں میں خامیاں ہیں جو ایسی خامیاں چھوڑ دیتی ہیں جن کا بدسلوکی کرنے والے غلط استعمال کر سکتے ہیں۔ وہ اکثر ڈیٹاسیٹس سے ضروری عناصر کو ہٹا دیتے ہیں، جو ان کے استعمال کو محدود کر دیتے ہیں۔ یہ آخری نسل کی تکنیکوں کا معاملہ نہیں ہے۔
اگلی نسل کے گمنام ٹولز
جدید گمنامی سافٹ ویئر دوبارہ شناخت کے خطرے کی نفی کرنے کے لیے جدید ترین تکنیکوں کا استعمال کرتا ہے۔ وہ ڈیٹا کے ساختی معیار کو برقرار رکھتے ہوئے رازداری کے تمام ضوابط کی تعمیل کرنے کے طریقے پیش کرتے ہیں۔
مصنوعی ڈیٹا جنریشن
مصنوعی ڈیٹا جنریشن ڈیٹا کی افادیت کو برقرار رکھتے ہوئے ڈیٹا کو گمنام کرنے کے لیے ایک بہتر طریقہ پیش کرتا ہے۔ یہ تکنیک نئے ڈیٹا سیٹس بنانے کے لیے الگورتھم کا استعمال کرتی ہے جو حقیقی ڈیٹا کی ساخت اور خصوصیات کو آئینہ دار کرتی ہے۔
مصنوعی ڈیٹا PII اور PHI کی جگہ فرضی ڈیٹا سے لے لیتا ہے جس کا افراد کو پتہ نہیں لگایا جا سکتا۔ یہ ڈیٹا رازداری کے قوانین، جیسے GDPR اور HIPAA کی تعمیل کو یقینی بناتا ہے۔ مصنوعی ڈیٹا جنریشن ٹولز کو اپنا کر، تنظیمیں ڈیٹا کی رازداری کو یقینی بناتی ہیں، ڈیٹا کی خلاف ورزیوں کے خطرات کو کم کرتی ہیں، اور ڈیٹا سے چلنے والی ایپلی کیشنز کی ترقی کو تیز کرتی ہیں۔
ہومومورفک خفیہ کاری
ہومومورفک انکرپشن ("ایک ہی ڈھانچہ" کے طور پر ترجمہ) ڈیٹا کو تبدیل کرتا ہے۔ سائفر ٹیکسٹ میں خفیہ کردہ ڈیٹاسیٹس اصل ڈیٹا کی ساخت کو برقرار رکھتے ہیں، جس کے نتیجے میں جانچ کے لیے بہترین درستگی ہوتی ہے۔
یہ طریقہ پیچیدہ حسابات کو براہ راست پر کرنے کی اجازت دیتا ہے۔ خفیہ کردہ ڈیٹا پہلے اسے ڈکرپٹ کرنے کی ضرورت کے بغیر۔ تنظیمیں محفوظ طریقے سے خفیہ فائلوں کو پبلک کلاؤڈ میں محفوظ کر سکتی ہیں اور سیکیورٹی سے سمجھوتہ کیے بغیر ڈیٹا پروسیسنگ کو تیسرے فریق کو آؤٹ سورس کر سکتی ہیں۔ یہ ڈیٹا بھی مطابقت رکھتا ہے، کیونکہ رازداری کے اصول خفیہ کردہ معلومات پر لاگو نہیں ہوتے ہیں۔
تاہم، پیچیدہ الگورتھم کو درست نفاذ کے لیے مہارت کی ضرورت ہوتی ہے۔ اس کے علاوہ، ہومومورفک انکرپشن غیر خفیہ کردہ ڈیٹا پر کارروائیوں کے مقابلے میں سست ہے۔ یہ DevOps اور کوالٹی ایشورنس (QA) ٹیموں کے لیے بہترین حل نہیں ہو سکتا، جنہیں جانچ کے لیے ڈیٹا تک فوری رسائی کی ضرورت ہوتی ہے۔
محفوظ کثیر جماعتی حساب کتاب
سیکیور ملٹی پارٹی کمپیوٹیشن (SMPC) کئی ممبروں کی مشترکہ کوشش سے ڈیٹا سیٹس بنانے کا ایک خفیہ طریقہ ہے۔ ہر فریق اپنے ان پٹ کو خفیہ کرتا ہے، کمپیوٹیشن کرتا ہے، اور پروسیس شدہ ڈیٹا حاصل کرتا ہے۔ اس طرح، ہر ممبر کو اپنا ڈیٹا خفیہ رکھتے ہوئے مطلوبہ نتیجہ ملتا ہے۔
اس طریقہ کار کے لیے متعدد فریقوں کو تیار کردہ ڈیٹاسیٹس کو ڈکرپٹ کرنے کی ضرورت ہوتی ہے، جو اسے اضافی رازدارانہ بناتا ہے۔ تاہم، SMPC کو نتائج پیدا کرنے کے لیے کافی وقت درکار ہے۔
| پچھلی نسل کے ڈیٹا کو گمنام کرنے کی تکنیک | اگلی نسل کے گمنام ٹولز | ||||
|---|---|---|---|---|---|
| تخلص۔ | علیحدہ میپنگ ٹیبل کو برقرار رکھتے ہوئے ذاتی شناخت کنندگان کو تخلص کے ساتھ بدل دیتا ہے۔ | - HR ڈیٹا مینجمنٹ - کسٹمر سپورٹ کی بات چیت - تحقیقی سروے | مصنوعی ڈیٹا جنریشن | نئے ڈیٹا سیٹس بنانے کے لیے الگورتھم کا استعمال کرتا ہے جو رازداری اور تعمیل کو یقینی بناتے ہوئے حقیقی ڈیٹا کے ڈھانچے کی عکاسی کرتا ہے۔ | - ڈیٹا سے چلنے والی ایپلیکیشن ڈویلپمنٹ - طبی تحقیق - اعلی درجے کی ماڈلنگ - کسٹمر مارکیٹنگ |
| ڈیٹا ماسکنگ | ایک ہی فارمیٹ کو برقرار رکھتے ہوئے، جعلی حروف کے ساتھ اصلی ڈیٹا کو تبدیل کرتا ہے۔ | - مالیاتی رپورٹنگ - صارف کی تربیت کے ماحول | ہومومورفک خفیہ کاری | اصل ڈھانچے کو برقرار رکھتے ہوئے ڈیٹا کو سائفر ٹیکسٹ میں تبدیل کرتا ہے، بغیر ڈکرپشن کے خفیہ کردہ ڈیٹا پر حساب کی اجازت دیتا ہے۔ | - محفوظ ڈیٹا پروسیسنگ - ڈیٹا کمپیوٹیشن آؤٹ سورسنگ - اعلی درجے کا ڈیٹا تجزیہ |
| عام کرنا (مجموعہ) | ڈیٹا کی تفصیل کو کم کرتا ہے، اسی طرح کے ڈیٹا کو گروپ کرتا ہے۔ | - آبادیاتی مطالعہ - مارکیٹ اسٹڈیز | محفوظ کثیر جماعتی حساب کتاب | کرپٹوگرافک طریقہ جہاں متعدد فریق اپنے ان پٹ کو خفیہ کرتے ہیں، کمپیوٹنگ انجام دیتے ہیں، اور مشترکہ نتائج حاصل کرتے ہیں۔ | - باہمی تعاون کے ساتھ ڈیٹا کا تجزیہ - خفیہ ڈیٹا جمع کرنا |
| گڑبڑ | قدروں کو گول کرکے اور بے ترتیب شور کو شامل کرکے ڈیٹا سیٹس میں ترمیم کرتا ہے۔ | - اقتصادی ڈیٹا کا تجزیہ - ٹریفک پیٹرن کی تحقیق - سیلز ڈیٹا کا تجزیہ | |||
| ڈیٹا کی تبدیلی | براہ راست ٹریس ایبلٹی کو روکنے کے لیے ڈیٹاسیٹ کی خصوصیت کی قدروں کو دوبارہ ترتیب دیتا ہے۔ | - ٹرانسپورٹیشن اسٹڈیز - تعلیمی ڈیٹا کا تجزیہ | |||
| ٹوکن بنانا | حساس ڈیٹا کو غیر حساس ٹوکنز سے تبدیل کرتا ہے۔ | - ادائیگی کی کارروائی - کسٹمر ریلیشن شپ ریسرچ | |||
| randomization ہے | اقدار کو تبدیل کرنے کے لیے بے ترتیب یا فرضی ڈیٹا شامل کرتا ہے۔ | - جغرافیائی ڈیٹا کا تجزیہ - طرز عمل کا مطالعہ | |||
| ڈیٹا کی اصلاح | ڈیٹاسیٹس سے معلومات کو ہٹاتا ہے، | - قانونی دستاویزات کی کارروائی - ریکارڈ کا انتظام | |||
جدول 1۔ پچھلی اور اگلی نسل کی گمنامی کی تکنیکوں کے درمیان موازنہ
ڈیٹا کی گمنامی کے لیے ایک نئے نقطہ نظر کے طور پر اسمارٹ ڈیٹا ڈی-شناخت
اسمارٹ ڈی شناخت AI سے تیار کردہ ڈیٹا کو گمنام کرتا ہے۔ مصنوعی فرضی ڈیٹا. خصوصیات کے ساتھ پلیٹ فارم حساس معلومات کو درج ذیل طریقوں سے مطابقت پذیر، ناقابل شناخت ڈیٹا میں تبدیل کرتے ہیں:
- ڈی آئیڈینٹیفکیشن سافٹ ویئر موجودہ ڈیٹا سیٹس کا تجزیہ کرتا ہے اور PII اور PHI کی شناخت کرتا ہے۔
- تنظیمیں منتخب کر سکتی ہیں کہ کون سا حساس ڈیٹا مصنوعی معلومات سے تبدیل کرنا ہے۔
- ٹول مطابقت پذیر ڈیٹا کے ساتھ نئے ڈیٹاسیٹس تیار کرتا ہے۔
یہ ٹیکنالوجی اس وقت کارآمد ہوتی ہے جب تنظیموں کو تعاون کرنے اور قیمتی ڈیٹا کا محفوظ طریقے سے تبادلہ کرنے کی ضرورت ہوتی ہے۔ یہ اس وقت بھی کارآمد ہوتا ہے جب ڈیٹا کو متعدد میں موافق بنانے کی ضرورت ہو۔ انحصار ڈیٹا بیس.
سمارٹ ڈی-آئیڈینٹیفیکیشن ڈیٹا کے اندر مستقل میپنگ کے ذریعے تعلقات کو برقرار رکھتی ہے۔ کمپنیاں تیار کردہ ڈیٹا کو گہرائی سے کاروباری تجزیات، مشین لرننگ ٹریننگ، اور کلینیکل ٹیسٹس کے لیے استعمال کر سکتی ہیں۔
بہت سارے طریقوں کے ساتھ، آپ کو یہ تعین کرنے کے لیے ایک طریقہ درکار ہے کہ آیا گمنامی کا ٹول آپ کے لیے صحیح ہے۔
صحیح ڈیٹا گمنامی ٹول کا انتخاب کیسے کریں۔
- آپریشنل اسکیل ایبلٹی۔ آپ کے آپریشنل مطالبات کے مطابق اوپر اور نیچے کی پیمائش کرنے کے قابل ایک ٹول کا انتخاب کریں۔ کام کے بڑھتے ہوئے بوجھ کے تحت آپریشنل کارکردگی کو جانچنے کے لیے وقت نکالیں۔
- انٹیگریشن ڈیٹا گمنامی ٹولز کو آپ کے موجودہ سسٹمز اور تجزیاتی سافٹ ویئر کے ساتھ ساتھ مسلسل انضمام اور مسلسل تعیناتی (CI/CD) پائپ لائن کے ساتھ آسانی سے ضم ہونا چاہیے۔ آپ کے ڈیٹا اسٹوریج، انکرپشن، اور پروسیسنگ پلیٹ فارمز کے ساتھ مطابقت بغیر کسی رکاوٹ کے آپریشنز کے لیے ضروری ہے۔
- مستقل ڈیٹا میپنگ۔ اس بات کو یقینی بنائیں کہ گمنام ڈیٹا محفوظ کرنے والوں میں سالمیت اور شماریاتی درستگی ہے جو آپ کی ضروریات کے لیے موزوں ہے۔ پچھلی نسل کی گمنامی کی تکنیک ڈیٹاسیٹس سے قیمتی عناصر کو مٹا دیتی ہے۔. جدید ٹولز، تاہم، حوالہ جاتی سالمیت کو برقرار رکھتے ہیں، جو ڈیٹا کو جدید استعمال کے معاملات کے لیے کافی درست بناتے ہیں۔
- سیکیورٹی میکانزم۔ ایسے ٹولز کو ترجیح دیں جو اندرونی اور بیرونی خطرات سے حقیقی ڈیٹاسیٹس اور گمنام نتائج کی حفاظت کرتے ہیں۔ سافٹ ویئر کو ایک محفوظ کسٹمر انفراسٹرکچر، رول پر مبنی رسائی کنٹرولز، اور ٹو فیکٹر توثیق APIs میں تعینات کیا جانا چاہیے۔
- ہم آہنگ انفراسٹرکچر۔ یقینی بنائیں کہ ٹول ڈیٹا سیٹس کو محفوظ اسٹوریج میں اسٹور کرتا ہے جو GDPR، HIPAA، اور CCPA کے ضوابط کی تعمیل کرتا ہے۔ اس کے علاوہ، اسے ڈیٹا بیک اپ اور ریکوری ٹولز کو سپورٹ کرنا چاہیے تاکہ غیر متوقع غلطیوں کی وجہ سے ٹائم ٹائم کے امکان سے بچا جا سکے۔
- ادائیگی کا ماڈل۔ یہ سمجھنے کے لیے فوری اور طویل مدتی اخراجات پر غور کریں کہ آیا ٹول آپ کے بجٹ کے مطابق ہے۔ کچھ ٹولز بڑے کاروباری اداروں اور درمیانے درجے کے کاروباروں کے لیے بنائے گئے ہیں، جبکہ دیگر کے پاس لچکدار ماڈل اور استعمال پر مبنی منصوبے ہیں۔
- ٹیکنیکل سپورٹ. کسٹمر اور تکنیکی مدد کے معیار اور دستیابی کا اندازہ کریں۔ فراہم کنندہ آپ کو ڈیٹا گمنامی کے ٹولز کو مربوط کرنے، عملے کو تربیت دینے اور تکنیکی مسائل کو حل کرنے میں مدد کر سکتا ہے۔
ڈیٹا گمنامی کے 7 بہترین ٹولز
اب جب کہ آپ جانتے ہیں کہ کس چیز کو تلاش کرنا ہے، آئیے اس بات کو دریافت کریں کہ ہمارے خیال میں کون سے سب سے زیادہ قابل اعتماد ٹولز ہیں۔ حساس معلومات کو ماسک کریں۔.
1. سنتھو
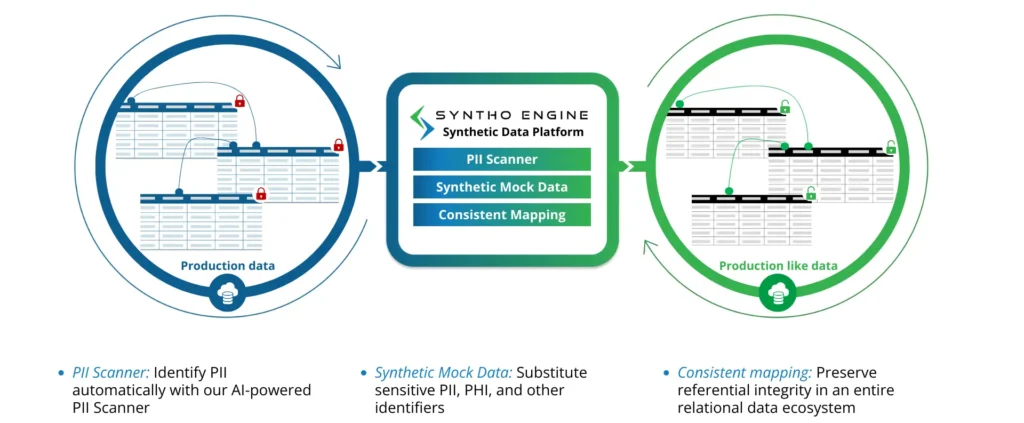
سنتھو مصنوعی ڈیٹا جنریشن سافٹ ویئر کے ذریعے تقویت یافتہ ہے۔ جو سمارٹ ڈی-آئیڈینٹیفیکیشن کے مواقع فراہم کرتا ہے۔. پلیٹ فارم کے اصول پر مبنی ڈیٹا کی تخلیق استراحت لاتی ہے، جس سے تنظیموں کو ان کی ضروریات کے مطابق ڈیٹا تیار کرنے کا اہل بناتا ہے۔
اے آئی سے چلنے والا سکینر ڈیٹا سیٹس، سسٹمز اور پلیٹ فارمز میں تمام PII اور PHI کی شناخت کرتا ہے۔ تنظیمیں منتخب کر سکتی ہیں کہ کون سا ڈیٹا ہٹانا ہے یا ریگولیٹری معیارات کی تعمیل کرنے کے لیے اس کا مذاق اڑانا ہے۔ دریں اثنا، سب سیٹنگ فیچر ٹیسٹنگ کے لیے چھوٹے ڈیٹا سیٹس بنانے میں مدد کرتا ہے، اسٹوریج اور پروسیسنگ کے وسائل پر بوجھ کو کم کرتا ہے۔
یہ پلیٹ فارم صحت کی دیکھ بھال، سپلائی چین مینجمنٹ اور فنانس سمیت مختلف شعبوں میں مفید ہے۔ تنظیمیں Syntho پلیٹ فارم کا استعمال غیر پروڈکشن بنانے اور اپنی مرضی کے مطابق جانچ کے منظرناموں کو تیار کرنے کے لیے کرتی ہیں۔
آپ سنتھو کی صلاحیتوں کے بارے میں مزید جان سکتے ہیں۔ ایک ڈیمو شیڈولنگ.
2. K2view
3. براڈ کام
4. زیادہ تر AI
5. اے آر ایکس
6. بھولنے کی بیماری
7. Tonic.ai
ڈیٹا اینومائزیشن ٹولز کیسز کا استعمال کرتے ہیں۔
فنانس، ہیلتھ کیئر، ایڈورٹائزنگ اور پبلک سروس میں کمپنیاں ڈیٹا پرائیویسی قوانین کے مطابق رہنے کے لیے گمنام ٹولز کا استعمال کرتی ہیں۔ غیر شناخت شدہ ڈیٹاسیٹس کو مختلف منظرناموں کے لیے استعمال کیا جاتا ہے۔
سافٹ ویئر ڈویلپمنٹ اور جانچ
گمنام ٹولز سافٹ ویئر انجینئرز، ٹیسٹرز، اور QA پیشہ ور افراد کو PII کو سامنے لائے بغیر حقیقت پسندانہ ڈیٹا سیٹس کے ساتھ کام کرنے کے قابل بناتے ہیں۔ جدید ٹولز ٹیموں کو ضروری ڈیٹا خود فراہم کرنے میں مدد کرتے ہیں جو تعمیل کے مسائل کے بغیر حقیقی دنیا کی جانچ کے حالات کی نقل کرتا ہے۔ اس سے تنظیموں کو ان کی سافٹ ویئر ڈویلپمنٹ کی کارکردگی اور سافٹ ویئر کے معیار کو بہتر بنانے میں مدد ملتی ہے۔
حقیقی معاملات:
- سنتھو کے سافٹ ویئر نے گمنام ٹیسٹ ڈیٹا بنایا جو حقیقی ڈیٹا کی شماریاتی اقدار کو محفوظ رکھتا ہے، جس سے ڈویلپرز کو مختلف منظرناموں کو زیادہ رفتار سے آزمانے کے قابل بناتا ہے۔
- Google کا BigQuery گودام ڈیٹا سیٹ کی گمنامی کی خصوصیت پیش کرتا ہے۔ رازداری کے ضوابط کو توڑے بغیر فراہم کنندگان کے ساتھ ڈیٹا شیئر کرنے میں تنظیموں کی مدد کرنے کے لیے۔
کلینیکل تحقیق
طبی محققین، خاص طور پر دواسازی کی صنعت میں، اپنے مطالعے کے لیے رازداری کو محفوظ رکھنے کے لیے ڈیٹا کو گمنام کرتے ہیں۔ محققین رجحانات، مریض کی آبادی اور علاج کے نتائج کا تجزیہ کر سکتے ہیں، مریض کی رازداری کو خطرے میں ڈالے بغیر طبی ترقی میں حصہ ڈال سکتے ہیں۔
حقیقی معاملات:
- ایراسمس میڈیکل سینٹر سنتھو کے گمنام AI جنریشن ٹولز استعمال کرتا ہے۔ طبی تحقیق کے لیے اعلیٰ معیار کے ڈیٹاسیٹس بنانے اور ان کا اشتراک کرنے کے لیے۔
فراڈ سے بچاؤ
دھوکہ دہی کی روک تھام میں، گمنامی کے ٹولز لین دین کے ڈیٹا کے محفوظ تجزیے کی اجازت دیتے ہیں، نقصان دہ نمونوں کی نشاندہی کرتے ہیں۔ ڈی آئیڈینٹیفیکیشن ٹولز AI سافٹ ویئر کو حقیقی ڈیٹا پر تربیت دینے کی بھی اجازت دیتے ہیں تاکہ دھوکہ دہی اور خطرے کی نشاندہی کو بہتر بنایا جا سکے۔
حقیقی معاملات:
- Brighterion Mastercard کے گمنام ٹرانزیکشن ڈیٹا پر تربیت یافتہ ہے۔ اس کے AI ماڈل کو مزید تقویت بخشنے کے لیے، دھوکہ دہی کا پتہ لگانے کی شرح کو بہتر بنانے کے ساتھ ساتھ جھوٹے مثبتات کو کم کرنا۔
کسٹمر مارکیٹنگ
ڈیٹا گمنامی کی تکنیک کسٹمر کی ترجیحات کا اندازہ لگانے میں مدد کرتی ہے۔ تنظیمیں ٹارگٹڈ مارکیٹنگ کی حکمت عملیوں کو بہتر بنانے اور صارف کے تجربے کو ذاتی بنانے کے لیے اپنے کاروباری شراکت داروں کے ساتھ غیر شناخت شدہ طرز عمل ڈیٹاسیٹ کا اشتراک کرتی ہیں۔
حقیقی معاملات:
- Syntho کے ڈیٹا کی گمنامی کے پلیٹ فارم نے مصنوعی ڈیٹا کا استعمال کرتے ہوئے کسٹمر کے منتھن کی درست پیش گوئی کی 56,000 کالموں کے ساتھ 128 سے زیادہ صارفین کے ڈیٹا سیٹ سے تیار کیا گیا۔
عوامی ڈیٹا پبلشنگ
ایجنسیاں اور سرکاری ادارے مختلف عوامی اقدامات کے لیے شفاف طریقے سے عوامی معلومات کو شیئر کرنے اور اس پر کارروائی کرنے کے لیے ڈیٹا کی گمنامی کا استعمال کرتے ہیں۔ ان میں سوشل نیٹ ورکس اور مجرمانہ ریکارڈ کے ڈیٹا کی بنیاد پر جرائم کی پیشین گوئیاں، آبادیاتی اور عوامی نقل و حمل کے راستوں پر مبنی شہری منصوبہ بندی، یا بیماریوں کے نمونوں کی بنیاد پر خطوں میں صحت کی دیکھ بھال کی ضروریات شامل ہیں۔
حقیقی معاملات:
- انڈیانا یونیورسٹی نے تقریباً 10,000 پولیس افسران کا گمنام سمارٹ فون ڈیٹا استعمال کیا۔ 21 امریکی شہروں میں سماجی و اقتصادی عوامل کی بنیاد پر پڑوس کے گشت کے تضادات کو ظاہر کرنے کے لیے۔
یہ صرف چند مثالیں ہیں جن کا ہم انتخاب کرتے ہیں۔ دی گمنام سافٹ ویئر دستیاب ڈیٹا سے زیادہ سے زیادہ فائدہ اٹھانے کے لیے تمام صنعتوں میں استعمال کیا جاتا ہے۔
ڈیٹا گمنامی کے بہترین ٹولز کا انتخاب کریں۔
تمام کمپنیاں استعمال کرتی ہیں۔ ڈیٹا بیس گمنام سافٹ ویئر رازداری کے ضوابط کی تعمیل کرنے کے لیے۔ جب ذاتی معلومات سے چھین لیا جاتا ہے، ڈیٹا سیٹس کو جرمانے یا بیوروکریٹک عمل کے خطرات کے بغیر استعمال اور شیئر کیا جا سکتا ہے۔
گمنامی کے پرانے طریقے جیسے ڈیٹا کی تبدیلی، ماسکنگ اور ریڈیکشن کافی محفوظ نہیں ہیں۔ ڈیٹا کی شناخت ایک امکان رہتا ہے، جو اسے غیر تعمیل یا خطرناک بنا دیتا ہے۔ اس کے علاوہ، ماضی کی نسل گمنام سافٹ ویئر اکثر ڈیٹا کے معیار کو گرا دیتا ہے، خاص طور پر بڑے ڈیٹاسیٹس. ادارے جدید تجزیات کے لیے اس طرح کے ڈیٹا پر انحصار نہیں کر سکتے۔
آپ کو اس کا انتخاب کرنا چاہئے۔ بہترین ڈیٹا گمنامی سافٹ ویئر بہت سے کاروبار Syntho پلیٹ فارم کو اس کی اعلی درجے کی PII شناخت، ماسکنگ، اور مصنوعی ڈیٹا تیار کرنے کی صلاحیتوں کے لیے منتخب کرتے ہیں۔
کیا آپ مزید جاننے میں دلچسپی رکھتے ہیں؟ ہماری مصنوعات کی دستاویزات یا دریافت کرنے کے لیے آزاد محسوس کریں۔ مظاہرے کے لیے ہم سے رابطہ کریں۔.
مصنف کے بارے میں

کاروباری ترقی مینیجر
اولیانا کرینسکا، Syntho میں بزنس ڈویلپمنٹ ایگزیکٹو، سافٹ ویئر ڈویلپمنٹ اور SaaS انڈسٹری میں بین الاقوامی تجربے کے ساتھ، VU Amsterdam سے ڈیجیٹل بزنس اور انوویشن میں ماسٹر کی ڈگری حاصل کی ہے۔
پچھلے پانچ سالوں کے دوران، Uliana نے AI کی صلاحیتوں کو تلاش کرنے اور AI پروجیکٹ کے نفاذ کے لیے اسٹریٹجک کاروباری مشاورت فراہم کرنے کے لیے ثابت قدمی کا مظاہرہ کیا ہے۔

اپنے مصنوعی ڈیٹا گائیڈ کو ابھی محفوظ کریں!
- مصنوعی ڈیٹا کیا ہے؟
- تنظیمیں اسے کیوں استعمال کرتی ہیں؟
- مصنوعی ڈیٹا کلائنٹ کیسز کو ویلیو ایڈ کرنا
- آغاز کیسے کیا جائے
