


Syntho کے ذریعہ تیار کردہ مصنوعی ڈیٹا کا SAS کے ڈیٹا ماہرین کے ذریعہ بیرونی اور معروضی نقطہ نظر سے جائزہ لیا جاتا ہے، اس کی تصدیق کی جاتی ہے اور اسے منظور کیا جاتا ہے۔
اگرچہ Syntho کو اپنے صارفین کو ایک اعلی درجے کی کوالٹی ایشورنس رپورٹ پیش کرنے پر فخر ہے، لیکن ہم صنعت کے رہنماؤں سے اپنے مصنوعی ڈیٹا کی بیرونی اور معروضی جانچ کی اہمیت کو بھی سمجھتے ہیں۔ اسی لیے ہم اپنے مصنوعی ڈیٹا کا اندازہ لگانے کے لیے SAS، تجزیات میں رہنما، کے ساتھ تعاون کرتے ہیں۔
SAS اصل ڈیٹا کے مقابلے میں Syntho کے AI سے تیار کردہ مصنوعی ڈیٹا کے ڈیٹا کی درستگی، رازداری کے تحفظ، اور استعمال کے بارے میں مختلف مکمل جائزے کرتا ہے۔ نتیجہ کے طور پر، SAS نے Syntho کے مصنوعی ڈیٹا کو اصل ڈیٹا کے مقابلے میں درست، محفوظ اور قابل استعمال ہونے کے طور پر جانچا اور اس کی منظوری دی۔
ہم نے ٹیلی کام ڈیٹا کا استعمال کیا جو ٹارگٹ ڈیٹا کے بطور "منتھن" پیشین گوئی کے لیے استعمال ہوتا ہے۔ تشخیص کا مقصد مصنوعی اعداد و شمار کو استعمال کرنے کے لیے مختلف منتھنی پیشین گوئی کے ماڈلز کو تربیت دینا اور ہر ماڈل کی کارکردگی کا جائزہ لینا تھا۔ چونکہ منتھن کی پیشن گوئی ایک درجہ بندی کا کام ہے، SAS نے پیشین گوئیاں کرنے کے لیے مقبول درجہ بندی کے ماڈلز کا انتخاب کیا، بشمول:
مصنوعی ڈیٹا تیار کرنے سے پہلے، SAS نے ٹیلی کام ڈیٹاسیٹ کو تصادفی طور پر ٹرین سیٹ (ماڈل کی تربیت کے لیے) اور ایک ہول آؤٹ سیٹ (ماڈلز کو اسکور کرنے کے لیے) میں تقسیم کیا۔ اسکورنگ کے لیے علیحدہ ہولڈ آؤٹ سیٹ ہونے سے یہ غیرجانبدارانہ اندازہ لگایا جا سکتا ہے کہ نئے ڈیٹا پر لاگو ہونے پر درجہ بندی کا ماڈل کتنا اچھا کام کر سکتا ہے۔
ٹرین سیٹ کو بطور ان پٹ استعمال کرتے ہوئے، Syntho نے اپنے Syntho Engine کو مصنوعی ڈیٹا سیٹ بنانے کے لیے استعمال کیا۔ بینچ مارکنگ کے لیے، SAS نے ایک مخصوص حد تک پہنچنے کے لیے گمنامی کی مختلف تکنیکوں کو استعمال کرنے کے بعد ٹرین سیٹ کا ایک گمنام ورژن بھی بنایا۔ سابقہ اقدامات کے نتیجے میں چار ڈیٹاسیٹ بنے:
ڈیٹا سیٹس 1، 3 اور 4 کو ہر درجہ بندی کے ماڈل کو تربیت دینے کے لیے استعمال کیا گیا تھا، جس کے نتیجے میں 12 (3 x 4) تربیت یافتہ ماڈل تھے۔ ایس اے ایس نے بعد میں ہولڈ آؤٹ ڈیٹاسیٹ کا استعمال کیا تاکہ کسٹمر کرن کی پیشین گوئی میں ہر ماڈل کی درستگی کی پیمائش کی جا سکے۔
SAS اصل ڈیٹا کے مقابلے میں Syntho کے AI سے تیار کردہ مصنوعی ڈیٹا کے ڈیٹا کی درستگی، رازداری کے تحفظ، اور استعمال کے بارے میں مختلف مکمل جائزے کرتا ہے۔ نتیجہ کے طور پر، SAS نے Syntho کے مصنوعی ڈیٹا کو اصل ڈیٹا کے مقابلے میں درست، محفوظ اور قابل استعمال ہونے کے طور پر جانچا اور اس کی منظوری دی۔
Syntho کا مصنوعی ڈیٹا نہ صرف بنیادی نمونوں کے لیے رکھتا ہے، بلکہ یہ اعلی درجے کے تجزیاتی کاموں کے لیے درکار گہرے 'پوشیدہ' شماریاتی نمونوں کو بھی حاصل کرتا ہے۔ مؤخر الذکر کو بار چارٹ میں دکھایا گیا ہے، جس سے ظاہر ہوتا ہے کہ مصنوعی ڈیٹا پر تربیت یافتہ ماڈلز کی درستگی بمقابلہ اصل ڈیٹا پر تربیت یافتہ ماڈلز ایک جیسے ہیں۔ لہذا، مصنوعی ڈیٹا کو ماڈلز کی اصل تربیت کے لیے استعمال کیا جا سکتا ہے۔ اصل اعداد و شمار کے مقابلے مصنوعی ڈیٹا پر الگورتھم کے ذریعہ منتخب کردہ ان پٹ اور متغیر اہمیت بہت ملتے جلتے تھے۔ لہذا، یہ نتیجہ اخذ کیا گیا ہے کہ ماڈلنگ کا عمل مصنوعی ڈیٹا پر کیا جا سکتا ہے، حقیقی حساس ڈیٹا کو استعمال کرنے کے متبادل کے طور پر۔
کلاسیکی گمنامی کی تکنیکوں میں مشترک ہے کہ وہ لوگوں کو ٹریس کرنے میں رکاوٹ ڈالنے کے لیے اصل ڈیٹا میں ہیرا پھیری کرتے ہیں۔ وہ ڈیٹا میں ہیرا پھیری کرتے ہیں اور اس طرح اس عمل میں ڈیٹا کو تباہ کرتے ہیں۔ آپ جتنا زیادہ گمنام کریں گے، اتنا ہی بہتر آپ کا ڈیٹا محفوظ رہے گا، بلکہ آپ کا ڈیٹا اتنا ہی زیادہ تباہ ہوگا۔ یہ خاص طور پر AI اور ماڈلنگ کے کاموں کے لیے تباہ کن ہے جہاں "پیش گوئی کرنے والی طاقت" ضروری ہے، کیونکہ خراب کوالٹی ڈیٹا کے نتیجے میں AI ماڈل کی خراب بصیرت ہوگی۔ SAS نے اس کا مظاہرہ، منحنی خطوط (AUC*) کے نیچے 0.5 کے قریب کے ساتھ کیا، یہ ظاہر کرتے ہوئے کہ گمنام ڈیٹا پر تربیت یافتہ ماڈلز اب تک کی بدترین کارکردگی کا مظاہرہ کرتے ہیں۔
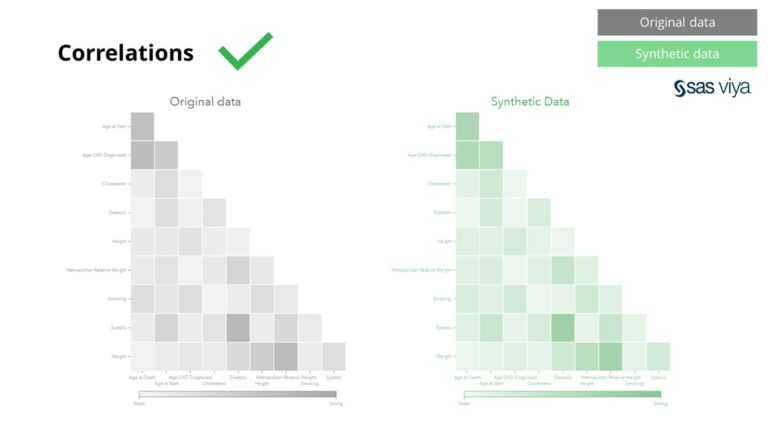
متغیرات کے درمیان ارتباط اور تعلقات کو مصنوعی ڈیٹا میں درست طریقے سے محفوظ کیا گیا تھا۔
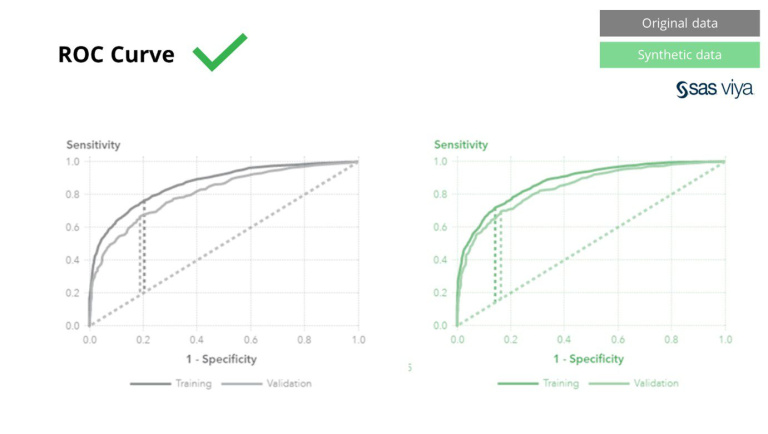
Area Under the Curve (AUC)، ماڈل کی کارکردگی کی پیمائش کے لیے ایک میٹرک، مستقل رہا۔
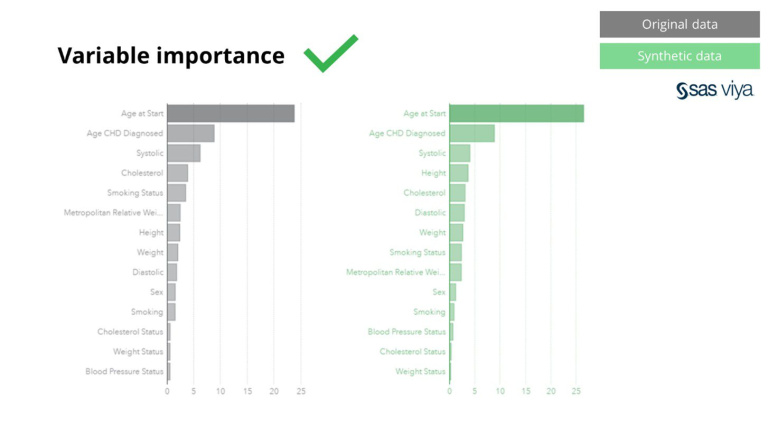
مزید برآں، متغیر کی اہمیت، جو کہ ایک ماڈل میں متغیر کی پیشین گوئی کی طاقت کی نشاندہی کرتی ہے، مصنوعی ڈیٹا کا اصل ڈیٹاسیٹ سے موازنہ کرتے وقت برقرار ہے۔
SAS کے ان مشاہدات کی بنیاد پر اور SAS Viya کا استعمال کرتے ہوئے، ہم اعتماد کے ساتھ یہ نتیجہ اخذ کر سکتے ہیں کہ Syntho Engine کے ذریعے تیار کردہ مصنوعی ڈیٹا واقعی معیار کے لحاظ سے حقیقی ڈیٹا کے برابر ہے۔ یہ ماڈل کی ترقی کے لیے مصنوعی ڈیٹا کے استعمال کی توثیق کرتا ہے، جس سے مصنوعی ڈیٹا کے ساتھ جدید تجزیات کی راہ ہموار ہوتی ہے۔
