AI سے تیار کردہ مصنوعی ڈیٹا، اعلیٰ معیار کے ڈیٹا تک آسان اور تیز رسائی؟
AI نے عملی طور پر مصنوعی ڈیٹا تیار کیا۔
سنتھو، جو AI سے تیار کردہ مصنوعی ڈیٹا میں ماہر ہے، کا مقصد موڑنا ہے۔ privacy by design AI سے تیار کردہ مصنوعی ڈیٹا کے ساتھ مسابقتی فائدہ حاصل کرنا۔ وہ اعلیٰ معیار کے ڈیٹا تک آسان اور تیز رسائی کے ساتھ مضبوط ڈیٹا فاؤنڈیشن بنانے میں تنظیموں کی مدد کرتے ہیں اور حال ہی میں فلپس انوویشن ایوارڈ جیتا ہے۔
تاہم، AI کے ساتھ مصنوعی ڈیٹا جنریشن ایک نسبتاً نیا حل ہے جو عام طور پر اکثر پوچھے جانے والے سوالات کو متعارف کرواتا ہے۔ ان کا جواب دینے کے لیے، Syntho نے SAS، Advanced Analytics اور AI سافٹ ویئر میں مارکیٹ لیڈر کے ساتھ مل کر کیس اسٹڈی شروع کی۔
ڈچ AI کولیشن (NL AIC) کے ساتھ مل کر، انہوں نے ڈیٹا کے معیار، قانونی اعتبار اور استعمال کے بارے میں مختلف جائزوں کے ذریعے Syntho Engine کے ذریعے تیار کردہ AI سے تیار کردہ مصنوعی ڈیٹا کا اصل ڈیٹا کے ساتھ موازنہ کر کے مصنوعی ڈیٹا کی قدر کی چھان بین کی۔
کیا ڈیٹا کی گمنامی ایک حل نہیں ہے؟
کلاسیکی گمنامی کی تکنیکیں مشترک ہیں کہ وہ اصل ڈیٹا میں ہیرا پھیری کرتے ہیں تاکہ لوگوں کو ٹریس کرنے میں رکاوٹ بنیں۔ مثالیں عام کرنا، دبانا، مسح کرنا، تخلص، ڈیٹا ماسکنگ، اور قطاروں اور کالموں کی شفلنگ ہیں۔ آپ کو نیچے دیے گئے جدول میں مثالیں مل سکتی ہیں۔
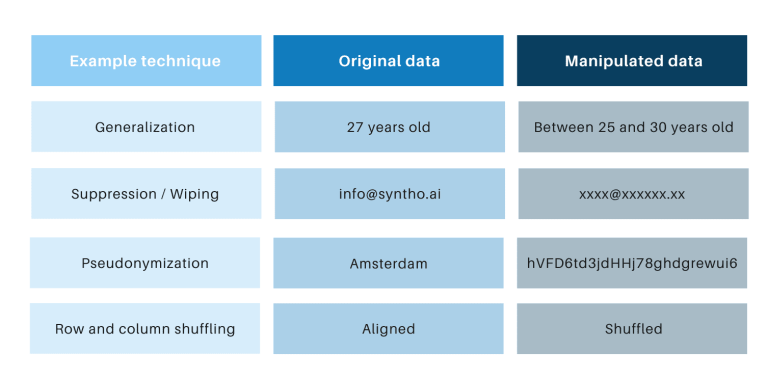
وہ تکنیکیں 3 کلیدی چیلنجوں کا تعارف کرتی ہیں:
- وہ فی ڈیٹا ٹائپ اور فی ڈیٹاسیٹ مختلف طریقے سے کام کرتے ہیں، جس کی وجہ سے انہیں پیمانہ کرنا مشکل ہو جاتا ہے۔ مزید برآں، چونکہ وہ مختلف طریقے سے کام کرتے ہیں، اس لیے ہمیشہ اس بارے میں بحث ہوتی رہے گی کہ کون سے طریقوں کو لاگو کرنا ہے اور تکنیک کے کون سے امتزاج کی ضرورت ہے۔
- اصل ڈیٹا کے ساتھ ہمیشہ ون ٹو ون رشتہ ہوتا ہے۔ اس کا مطلب یہ ہے کہ رازداری کا خطرہ ہمیشہ رہے گا، خاص طور پر تمام کھلے ڈیٹا سیٹس اور ان ڈیٹاسیٹس کو لنک کرنے کے لیے دستیاب تکنیکوں کی وجہ سے۔
- وہ ڈیٹا میں ہیرا پھیری کرتے ہیں اور اس طرح اس عمل میں ڈیٹا کو تباہ کرتے ہیں۔ یہ خاص طور پر AI کاموں کے لیے تباہ کن ہے جہاں "پیش گوئی کرنے والی طاقت" ضروری ہے، کیونکہ خراب کوالٹی ڈیٹا کے نتیجے میں AI ماڈل کی خراب بصیرت ہوگی (کوڑا کرکٹ کے نتیجے میں کوڑے کو باہر نکالا جائے گا)۔
اس کیس اسٹڈی کے ذریعے ان نکات کا بھی اندازہ لگایا گیا ہے۔
کیس اسٹڈی کا تعارف
کیس اسٹڈی کے لیے، ہدف ڈیٹا سیٹ ایک ٹیلی کام ڈیٹاسیٹ تھا جو SAS کے ذریعے فراہم کیا گیا تھا جس میں 56.600 صارفین کا ڈیٹا تھا۔ ڈیٹاسیٹ میں 128 کالم شامل ہیں، بشمول ایک کالم یہ بتاتا ہے کہ آیا کسی صارف نے کمپنی چھوڑ دی ہے (یعنی 'منتھنی') یا نہیں۔ کیس اسٹڈی کا مقصد کچھ ماڈلز کو تربیت دینے کے لیے مصنوعی ڈیٹا کا استعمال کرنا تھا تاکہ گاہک کی منتھنی کی پیشن گوئی کی جا سکے اور ان تربیت یافتہ ماڈلز کی کارکردگی کا جائزہ لیا جا سکے۔ جیسا کہ منتھن کی پیشن گوئی ایک درجہ بندی کا کام ہے، SAS نے پیشین گوئیاں کرنے کے لیے چار مقبول درجہ بندی کے ماڈلز کا انتخاب کیا، بشمول:
- بے ترتیب جنگل
- گریڈینٹ کو بڑھانا
- لاجسٹک رجعت
- نیند نیٹ ورک
مصنوعی ڈیٹا تیار کرنے سے پہلے، SAS نے ٹیلی کام ڈیٹاسیٹ کو تصادفی طور پر ٹرین سیٹ (ماڈل کی تربیت کے لیے) اور ایک ہول آؤٹ سیٹ (ماڈلز کو اسکور کرنے کے لیے) میں تقسیم کیا۔ اسکورنگ کے لیے علیحدہ ہولڈ آؤٹ سیٹ ہونے سے یہ غیرجانبدارانہ اندازہ لگایا جا سکتا ہے کہ نئے ڈیٹا پر لاگو ہونے پر درجہ بندی کا ماڈل کتنی اچھی کارکردگی کا مظاہرہ کر سکتا ہے۔
ٹرین سیٹ کو بطور ان پٹ استعمال کرتے ہوئے، Syntho نے اپنے Syntho Engine کو مصنوعی ڈیٹا سیٹ بنانے کے لیے استعمال کیا۔ بینچ مارکنگ کے لیے، SAS نے ایک مخصوص حد تک پہنچنے کے لیے گمنامی کی مختلف تکنیکوں کو لاگو کرنے کے بعد ٹرین سیٹ کا ایک ہیرا پھیری ورژن بھی بنایا۔ سابقہ اقدامات کے نتیجے میں چار ڈیٹاسیٹ بنے:
- ٹرین ڈیٹاسیٹ (یعنی اصل ڈیٹاسیٹ مائنس ہولڈ آؤٹ ڈیٹاسیٹ)
- ایک ہولڈ آؤٹ ڈیٹاسیٹ (یعنی اصل ڈیٹاسیٹ کا سب سیٹ)
- ایک گمنام ڈیٹاسیٹ (ٹرین ڈیٹاسیٹ پر مبنی)
- ایک مصنوعی ڈیٹاسیٹ (ٹرین ڈیٹاسیٹ پر مبنی)
ڈیٹا سیٹس 1، 3 اور 4 کو ہر درجہ بندی کے ماڈل کو تربیت دینے کے لیے استعمال کیا گیا تھا، جس کے نتیجے میں 12 (3 x 4) تربیت یافتہ ماڈل تھے۔ SAS نے بعد میں ہولڈ آؤٹ ڈیٹاسیٹ کا استعمال اس درستگی کی پیمائش کے لیے کیا جس کے ساتھ ہر ماڈل گاہک کے منڈلانے کی پیش گوئی کرتا ہے۔ کچھ بنیادی اعدادوشمار سے شروع کرتے ہوئے نتائج ذیل میں پیش کیے گئے ہیں۔
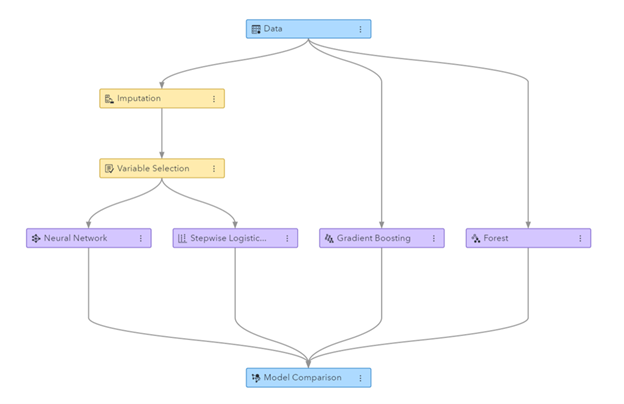
تصویر: ایس اے ایس ویژول ڈیٹا مائننگ اور مشین لرننگ میں تیار کردہ مشین لرننگ پائپ لائن
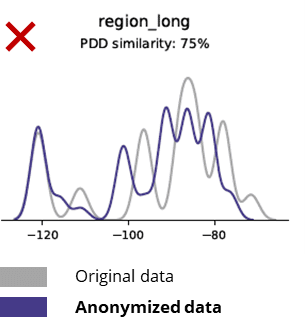
گمنام ڈیٹا کا اصل ڈیٹا سے موازنہ کرتے وقت بنیادی اعدادوشمار
گمنامی کی تکنیک بنیادی نمونوں، کاروباری منطق، تعلقات اور اعدادوشمار کو بھی تباہ کر دیتی ہے (جیسا کہ نیچے دی گئی مثال میں)۔ بنیادی تجزیات کے لیے گمنام ڈیٹا کا استعمال اس طرح ناقابل اعتماد نتائج پیدا کرتا ہے۔ درحقیقت، گمنام ڈیٹا کے خراب معیار نے اسے جدید تجزیاتی کاموں (جیسے AI/ML ماڈلنگ اور ڈیش بورڈنگ) کے لیے استعمال کرنا تقریباً ناممکن بنا دیا۔
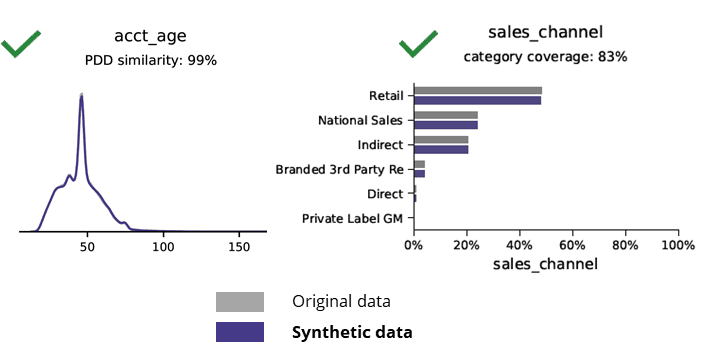
اصل اعداد و شمار کے ساتھ مصنوعی ڈیٹا کا موازنہ کرتے وقت بنیادی اعدادوشمار
AI کے ساتھ مصنوعی ڈیٹا جنریشن بنیادی نمونوں، کاروباری منطق، تعلقات اور اعدادوشمار کو محفوظ رکھتی ہے (جیسا کہ نیچے دی گئی مثال میں)۔ بنیادی تجزیات کے لیے مصنوعی ڈیٹا کا استعمال اس طرح قابل اعتماد نتائج پیدا کرتا ہے۔ اہم سوال، کیا مصنوعی ڈیٹا جدید تجزیاتی کاموں (جیسے AI/ML ماڈلنگ اور ڈیش بورڈنگ) کے لیے رکھتا ہے؟
AI سے تیار کردہ مصنوعی ڈیٹا اور جدید تجزیات
مصنوعی ڈیٹا نہ صرف بنیادی نمونوں کے لیے رکھتا ہے (جیسا کہ سابقہ پلاٹوں میں دکھایا گیا ہے)، یہ جدید تجزیاتی کاموں کے لیے درکار گہرے 'پوشیدہ' شماریاتی نمونوں کو بھی حاصل کرتا ہے۔ مؤخر الذکر کو ذیل میں بار چارٹ میں دکھایا گیا ہے، جس سے ظاہر ہوتا ہے کہ مصنوعی ڈیٹا پر تربیت یافتہ ماڈلز کی درستگی بمقابلہ اصل ڈیٹا پر تربیت یافتہ ماڈلز ایک جیسے ہیں۔ مزید برآں، منحنی خطوط (AUC*) کے نیچے 0.5 کے قریب ہونے کے ساتھ، گمنام ڈیٹا پر تربیت یافتہ ماڈلز کی کارکردگی انتہائی خراب ہے۔ اصل ڈیٹا کے مقابلے مصنوعی ڈیٹا پر تمام جدید تجزیاتی جائزوں کے ساتھ مکمل رپورٹ درخواست پر دستیاب ہے۔
*AUC: وکر کے نیچے کا رقبہ درست مثبت، جھوٹے مثبت، غلط منفی اور حقیقی منفی کو مدنظر رکھتے ہوئے، جدید تجزیاتی ماڈلز کی درستگی کا ایک پیمانہ ہے۔ 0,5 کا مطلب ہے کہ ایک ماڈل تصادفی طور پر پیشین گوئی کرتا ہے اور اس میں کوئی پیشین گوئی کی طاقت نہیں ہے اور 1 کا مطلب ہے کہ ماڈل ہمیشہ درست ہوتا ہے اور اس میں پوری پیشین گوئی کی طاقت ہوتی ہے۔
مزید برآں، اس مصنوعی ڈیٹا کو ڈیٹا کی خصوصیات اور ماڈلز کی حقیقی تربیت کے لیے درکار اہم متغیرات کو سمجھنے کے لیے استعمال کیا جا سکتا ہے۔ اصل ڈیٹا کے مقابلے مصنوعی ڈیٹا پر الگورتھم کے ذریعے منتخب کردہ ان پٹ بہت ملتے جلتے تھے۔ لہذا، ماڈلنگ کا عمل اس مصنوعی ورژن پر کیا جا سکتا ہے، جس سے ڈیٹا کی خلاف ورزی کا خطرہ کم ہو جاتا ہے۔ تاہم، جب انفرادی ریکارڈ کا اندازہ لگاتے ہیں (مثلاً ٹیلکو کسٹمر) اصل ڈیٹا پر دوبارہ تربیت دینے کی سفارش کی جاتی ہے تاکہ وضاحت کی جا سکے، قبولیت میں اضافہ ہو یا صرف ضابطے کی وجہ سے۔
AUC بذریعہ الگورتھم گروپ کردہ طریقہ کے لحاظ سے
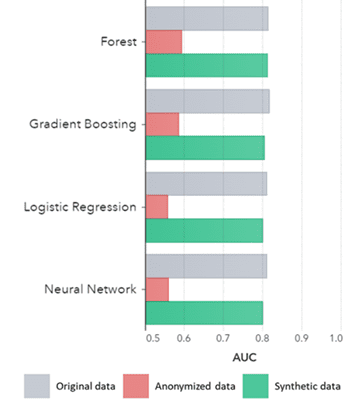
نتائج:
- اصل ڈیٹا پر تربیت یافتہ ماڈلز کے مقابلے مصنوعی ڈیٹا پر تربیت یافتہ ماڈلز انتہائی مماثل کارکردگی دکھاتے ہیں۔
- 'کلاسک گمنامی کی تکنیک' کے ساتھ گمنام ڈیٹا پر تربیت یافتہ ماڈل اصل ڈیٹا یا مصنوعی ڈیٹا پر تربیت یافتہ ماڈلز کے مقابلے کمتر کارکردگی دکھاتے ہیں۔
- مصنوعی ڈیٹا جنریشن آسان اور تیز ہے کیونکہ تکنیک فی ڈیٹا سیٹ اور فی ڈیٹا ٹائپ بالکل یکساں کام کرتی ہے۔
ویلیو ایڈڈنگ مصنوعی ڈیٹا کے استعمال کے معاملات
کیس 1 استعمال کریں: ماڈل کی ترقی اور جدید تجزیات کے لیے مصنوعی ڈیٹا
قابل استعمال، اعلیٰ معیار کے ڈیٹا تک آسان اور تیز رسائی کے ساتھ مضبوط ڈیٹا فاؤنڈیشن کا ہونا ماڈلز (مثلاً ڈیش بورڈز [BI] اور جدید تجزیات [AI & ML]) تیار کرنے کے لیے ضروری ہے۔ تاہم، بہت سی تنظیمیں ذیلی بہترین ڈیٹا فاؤنڈیشن کا شکار ہیں جس کے نتیجے میں 3 اہم چیلنجز ہیں:
- ڈیٹا تک رسائی حاصل کرنے میں (پرائیویسی) قواعد و ضوابط ، اندرونی عمل یا ڈیٹا سائلس کی وجہ سے عمر لگتی ہے۔
- کلاسیکی گمنامی کی تکنیک ڈیٹا کو تباہ کر دیتی ہے، جس سے ڈیٹا مزید تجزیہ اور جدید تجزیات کے لیے موزوں نہیں رہتا ہے (کوڑا اِن = کچرا باہر)
- موجودہ حل توسیع پذیر نہیں ہیں کیونکہ وہ فی ڈیٹاسیٹ اور فی ڈیٹا ٹائپ مختلف طریقے سے کام کرتے ہیں اور بڑے ملٹی ٹیبل ڈیٹا بیس کو ہینڈل نہیں کرسکتے ہیں۔
مصنوعی ڈیٹا اپروچ: اصلی مصنوعی ڈیٹا کے ساتھ ماڈل تیار کریں:
- اپنے ڈویلپرز کو روکنے کے بغیر ، اصل ڈیٹا کے استعمال کو کم سے کم کریں۔
- ذاتی ڈیٹا کو غیر مقفل کریں اور مزید ڈیٹا تک رسائی حاصل کریں جو پہلے محدود تھا (جیسے رازداری کی وجہ سے)
- متعلقہ ڈیٹا تک آسان اور تیز ڈیٹا تک رسائی۔
- توسیع پذیر حل جو ہر ڈیٹاسیٹ ، ڈیٹا ٹائپ اور بڑے پیمانے پر ڈیٹا بیس کے لیے یکساں کام کرتا ہے۔
یہ تنظیم کو ڈیٹا کو غیر مقفل کرنے اور ڈیٹا کے مواقع سے فائدہ اٹھانے کے لیے قابل استعمال، اعلیٰ معیار کے ڈیٹا تک آسان اور تیز رسائی کے ساتھ مضبوط ڈیٹا فاؤنڈیشن بنانے کی اجازت دیتا ہے۔
کیس 2 استعمال کریں: سافٹ ویئر ٹیسٹنگ، ڈیولپمنٹ اور ڈیلیوری کے لیے سمارٹ مصنوعی ٹیسٹ ڈیٹا
جدید ترین سافٹ ویئر حل فراہم کرنے کے لیے اعلیٰ معیار کے ٹیسٹ ڈیٹا کے ساتھ جانچ اور ترقی ضروری ہے۔ اصل پروڈکشن ڈیٹا کا استعمال واضح معلوم ہوتا ہے، لیکن (رازداری) کے ضوابط کی وجہ سے اس کی اجازت نہیں ہے۔ متبادل Test Data Management (TDM) ٹولز متعارف کراتے ہیں "legacy-by-design"ٹیسٹ ڈیٹا کو صحیح طریقے سے حاصل کرنے میں:
- پیداواری ڈیٹا کی عکاسی نہ کریں اور کاروباری منطق اور حوالہ جاتی سالمیت محفوظ نہیں ہے۔
- سست اور وقت طلب کام کریں۔
- دستی کام کی ضرورت ہے۔
مصنوعی ڈیٹا اپروچ: جدید ترین سافٹ ویئر حل فراہم کرنے کے لیے AI سے تیار کردہ مصنوعی ٹیسٹ ڈیٹا کے ساتھ جانچ اور تیار کریں:
- محفوظ کاروباری منطق اور حوالہ جاتی سالمیت کے ساتھ پیداوار جیسا ڈیٹا
- جدید ترین AI کے ساتھ آسان اور تیز ڈیٹا جنریشن۔
- رازداری بہ ڈیزائن
- آسان، تیز اور agile
یہ تنظیم کو جدید ترین سافٹ ویئر حل فراہم کرنے کے لیے اگلے درجے کے ٹیسٹ ڈیٹا کے ساتھ جانچ اور تیار کرنے کی اجازت دیتا ہے!
مزید معلومات
دلچسپی؟ مصنوعی ڈیٹا کے بارے میں مزید معلومات کے لیے، سنتھو کی ویب سائٹ ملاحظہ کریں یا Wim Kees Janssen سے رابطہ کریں۔ SAS کے بارے میں مزید معلومات کے لیے، ملاحظہ کریں۔ www.sas.com یا kees@syntho.ai پر رابطہ کریں۔
اس استعمال کے معاملے میں، Syntho، SAS اور NL AIC مطلوبہ نتائج حاصل کرنے کے لیے مل کر کام کرتے ہیں۔ Syntho AI سے تیار کردہ مصنوعی ڈیٹا کا ماہر ہے اور SAS تجزیات میں مارکیٹ لیڈر ہے اور ڈیٹا کو تلاش کرنے، تجزیہ کرنے اور دیکھنے کے لیے سافٹ ویئر پیش کرتا ہے۔
* پیشین گوئیاں 2021 - حکومت کرنے، اسکیل کرنے اور ڈیجیٹل کاروبار کو تبدیل کرنے کے لیے ڈیٹا اور تجزیات کی حکمت عملی، گارٹنر، 2020۔

اپنے مصنوعی ڈیٹا گائیڈ کو ابھی محفوظ کریں!
- مصنوعی ڈیٹا کیا ہے؟
- تنظیمیں اسے کیوں استعمال کرتی ہیں؟
- مصنوعی ڈیٹا کلائنٹ کیسز کو ویلیو ایڈ کرنا
- آغاز کیسے کیا جائے
