اندازہ لگائیں کون؟ 5 مثالیں کیوں نام ہٹانا آپشن نہیں ہے۔



اندازہ لگائیں کون؟ اگرچہ مجھے یقین ہے کہ آپ میں سے بیشتر اس کھیل کو پچھلے دنوں سے جانتے ہیں ، یہاں ایک مختصر جائزہ ہے۔ کھیل کا مقصد: 'ہاں' اور 'نہیں' سوالات پوچھ کر اپنے مخالف کے منتخب کردہ کارٹون کردار کا نام دریافت کریں ، جیسے 'کیا کوئی شخص ٹوپی پہنتا ہے؟' یا 'کیا شخص شیشے پہنتا ہے'؟ کھلاڑی حریف کے جواب کی بنیاد پر امیدواروں کو ختم کرتے ہیں اور ایسی خصوصیات سیکھتے ہیں جو ان کے مخالف کے اسرار کردار سے متعلق ہوتی ہیں۔ پہلا کھلاڑی جو دوسرے کھلاڑی کے اسرار کردار کا پتہ لگاتا ہے وہ گیم جیتتا ہے۔
تم اسے سمجھ گئے. کسی فرد کو ڈیٹاسیٹ سے صرف متعلقہ اوصاف تک رسائی حاصل کرکے شناخت کرنی چاہیے۔ درحقیقت ، ہم باقاعدگی سے اندازہ لگاتے ہیں کہ کس نے عملی طور پر اس کا اطلاق کیا ہے ، لیکن اس کے بعد قطاروں اور کالموں کے ساتھ فارمیٹ شدہ ڈیٹاسیٹس پر کام کیا گیا ہے جس میں حقیقی لوگوں کی خصوصیات ہیں۔ اعداد و شمار کے ساتھ کام کرتے وقت بنیادی فرق یہ ہے کہ لوگ اس آسانی کو کم سمجھتے ہیں جس کے ذریعے حقیقی افراد کو صرف چند صفات تک رسائی حاصل کرکے بے نقاب کیا جاسکتا ہے۔
جیسا کہ Guess Who گیم واضح کرتا ہے ، کوئی شخص صرف چند صفات تک رسائی حاصل کرکے افراد کی شناخت کرسکتا ہے۔ یہ ایک سادہ مثال کے طور پر کام کرتا ہے کہ آپ کے ڈیٹاسیٹ سے صرف 'نام' (یا دیگر براہ راست شناخت کنندگان) کو ہٹانا گمنامی کی تکنیک کے طور پر ناکام کیوں ہوتا ہے۔ اس بلاگ میں ، ہم ڈیٹا کو گمنام کرنے کے ذرائع کے طور پر کالموں کو ہٹانے سے وابستہ رازداری کے خطرات کے بارے میں آپ کو آگاہ کرنے کے لیے چار عملی معاملات فراہم کرتے ہیں۔
تعلق کے حملوں کا خطرہ سب سے اہم وجہ ہے کہ صرف ناموں کو حذف کرنا (اب) گمنامی کے طریقہ کار کے طور پر کام نہیں کرتا ہے۔ لنکیج اٹیک کے ساتھ ، حملہ آور اصل ڈیٹا کو دوسرے قابل رسائی ڈیٹا سورسز کے ساتھ جوڑتا ہے تاکہ انفرادی طور پر کسی فرد کی شناخت کی جا سکے اور اس شخص کے بارے میں (اکثر حساس) معلومات سیکھیں۔
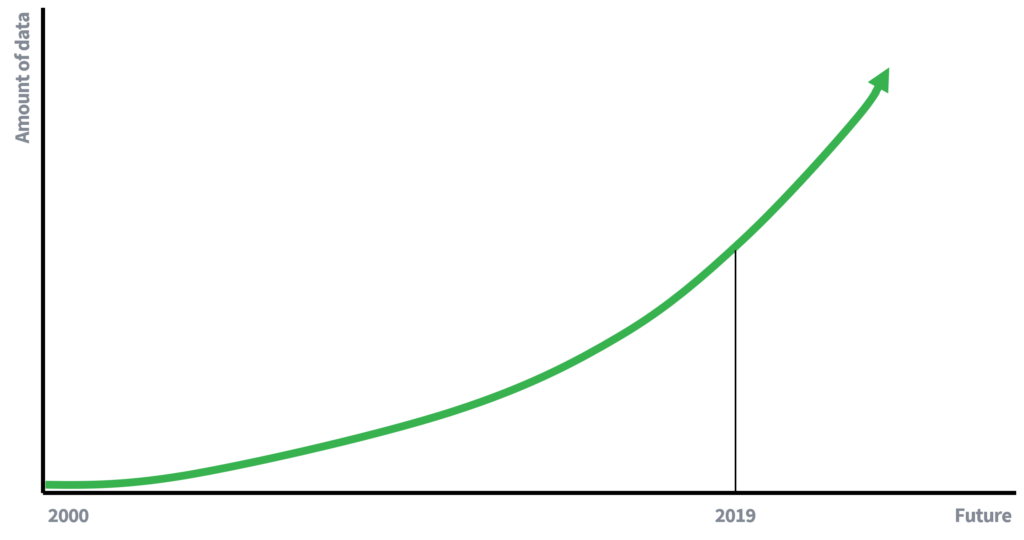
یہاں اہم ڈیٹا کے دیگر وسائل کی دستیابی ہے جو اب موجود ہیں ، یا مستقبل میں موجود ہو سکتے ہیں۔ اپنے بارے میں سوچو۔ فیس بک ، انسٹاگرام یا لنکڈ ان پر آپ کا کتنا ذاتی ڈیٹا پایا جا سکتا ہے جو ممکنہ طور پر لنک ایج حملے کے لیے غلط استعمال ہو سکتا ہے؟
پہلے دنوں میں ، ڈیٹا کی دستیابی بہت زیادہ محدود تھی ، جو جزوی طور پر وضاحت کرتی ہے کہ ناموں کو حذف کرنا افراد کی رازداری کو محفوظ رکھنے کے لیے کافی کیوں تھا۔ کم دستیاب ڈیٹا کا مطلب ہے ڈیٹا کو جوڑنے کے کم مواقع۔ تاہم ، اب ہم ڈیٹا سے چلنے والی معیشت میں (فعال) شرکاء ہیں ، جہاں ڈیٹا کی مقدار تیزی سے بڑھ رہی ہے۔ مزید اعداد و شمار ، اور ڈیٹا اکٹھا کرنے کے لیے ٹیکنالوجی کو بہتر بنانے سے تعلق کے حملوں کے امکانات بڑھ جائیں گے۔ 10 سالوں میں ایک تعلق کے حملے کے خطرے کے بارے میں کیا لکھیں گے؟
مثال 1۔
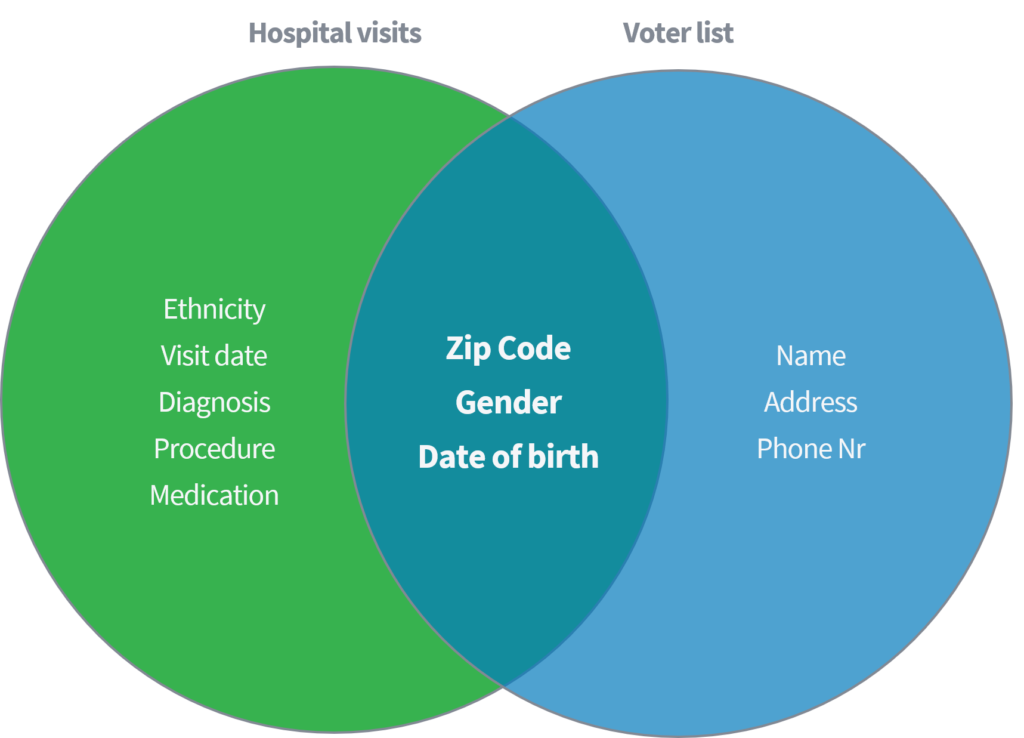
سوینی (2002) نے ایک تعلیمی مقالے میں دکھایا کہ وہ کس طرح امریکہ میں عوامی طور پر دستیاب ووٹنگ رجسٹرار سے 'ہسپتال کے دوروں' کے عوامی دستیاب ڈیٹا سیٹ کو جوڑنے کی بنیاد پر افراد سے حساس طبی ڈیٹا کی شناخت اور بازیافت کرنے میں کامیاب رہی۔ دونوں ڈیٹاسیٹ جہاں ناموں اور دیگر براہ راست شناخت کنندگان کو حذف کرنے کے ذریعے مناسب طریقے سے گمنام ہونے کا گمان کیا جاتا ہے۔
مثال 2۔
صرف تین پیرامیٹرز (1) زپ کوڈ ، (2) صنف اور (3) تاریخ پیدائش کی بنیاد پر ، اس نے دکھایا کہ پوری امریکی آبادی کا 87 فیصد دونوں ڈیٹاسیٹس کی مذکورہ بالا خصوصیات سے مل کر دوبارہ شناخت کیا جا سکتا ہے۔ سوینی نے پھر 'زپ کوڈ' کے متبادل کے طور پر 'کنٹری' رکھنے کے ساتھ اپنا کام دہرایا۔ مزید برآں ، اس نے یہ ظاہر کیا کہ پوری امریکی آبادی کا 18 could صرف ایک ڈیٹاسیٹ تک رسائی حاصل کرنے کے ذریعے شناخت کیا جاسکتا ہے جس میں (1) آبائی ملک ، (2) جنس اور (3) تاریخ پیدائش کے بارے میں معلومات ہوں۔ مذکورہ بالا عوامی ذرائع ، جیسے فیس بک ، لنکڈ ان یا انسٹاگرام کے بارے میں سوچیں۔ کیا آپ کا ملک ، جنس اور تاریخ پیدائش دکھائی دے رہی ہے ، یا دوسرے صارفین اسے کاٹ سکتے ہیں؟
مثال 3۔
| نیم شناخت کرنے والے۔ | امریکی آبادی کی unique منفرد شناخت (248 ملین) |
| 5 عددی زپ ، جنس ، تاریخ پیدائش | 87٪ |
| جگہ، جنس ، تاریخ پیدائش۔ | 53٪ |
| ملک، جنس ، تاریخ پیدائش۔ | 18٪ |
یہ مثال ظاہر کرتی ہے کہ بظاہر گمنام ڈیٹا میں افراد کا نام گمنام کرنا قابل ذکر آسان ہے۔ سب سے پہلے ، یہ مطالعہ خطرے کی ایک بڑی شدت کی نشاندہی کرتا ہے ، جیسا کہ۔ امریکی آبادی کا 87٪ استعمال کرتے ہوئے آسانی سے پہچانا جا سکتا ہے۔ چند خصوصیات. دوسرا ، اس مطالعے میں سامنے آنے والا طبی ڈیٹا انتہائی حساس تھا۔ ہسپتال کے وزٹ ڈیٹاسیٹ سے بے نقاب افراد کے ڈیٹا کی مثالوں میں نسل ، تشخیص اور ادویات شامل ہیں۔ وہ صفات جو کہ کوئی شخص خفیہ رکھ سکتا ہے ، مثال کے طور پر انشورنس کمپنیوں سے۔
صرف براہ راست شناخت کنندگان کو ہٹانے کا ایک اور خطرہ ، جیسے نام ، اس وقت پیدا ہوتا ہے جب باخبر افراد کو ڈیٹا سیٹ میں مخصوص افراد کے خصائل یا رویے کے بارے میں اعلیٰ معلومات یا معلومات ہو. ان کے علم کی بنیاد پر ، حملہ آور مخصوص ڈیٹا ریکارڈ کو حقیقی لوگوں سے جوڑ سکتا ہے۔
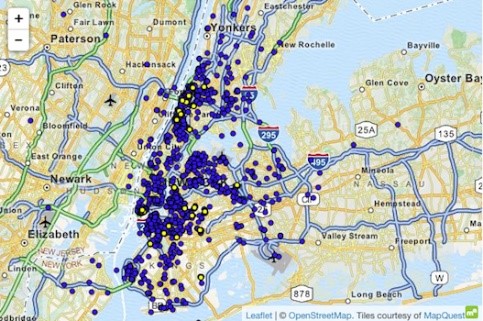
اعلی معلومات کا استعمال کرتے ہوئے ڈیٹاسیٹ پر حملے کی ایک مثال نیو یارک ٹیکسی کیس ہے ، جہاں اٹوکر (2014) مخصوص افراد کو بے نقاب کرنے کے قابل تھا۔ ایمپلائیڈ ڈیٹاسیٹ میں نیو یارک کے تمام ٹیکسی سفر شامل تھے ، جو بنیادی صفات جیسے کہ اسٹارٹ کوآرڈینیٹس ، اینڈ کوآرڈینیٹس ، سواری کی قیمت اور ٹپ سے مالا مال تھے۔
ایک باخبر فرد جو جانتا ہے کہ نیو یارک بالغ کلب 'ہسلر' کے لیے ٹیکسی کے دورے کر سکتا ہے۔ 'اختتامی مقام' کو فلٹر کرکے ، اس نے شروع کے عین مطابق پتے نکالے اور اس طرح مختلف بار بار آنے والوں کی شناخت کی۔ اسی طرح ، جب کوئی فرد کے گھر کا پتہ معلوم ہوتا تو ٹیکسی کی سواریوں کا اندازہ لگایا جا سکتا تھا۔ گپ شپ سائٹس پر کئی مشہور فلمی ستاروں کا وقت اور مقام دریافت کیا گیا۔ اس معلومات کو NYC ٹیکسی ڈیٹا سے جوڑنے کے بعد ، ان کی ٹیکسی کی سواریوں ، ان کی ادائیگی کی گئی رقم ، اور چاہے انہوں نے ٹپ دی ہو ، حاصل کرنا آسان تھا۔
مثال 4۔
ڈراپ آف کوآرڈینیٹس ہسلر۔
بریڈلی کوپر
جیسکا البا
دلیل کی ایک عام لکیر یہ ہے کہ 'یہ ڈیٹا بیکار ہے' یا 'کوئی بھی اس ڈیٹا کے ساتھ کچھ نہیں کر سکتا'۔ یہ اکثر غلط فہمی ہوتی ہے۔ یہاں تک کہ انتہائی معصوم ڈیٹا بھی ایک منفرد 'فنگر پرنٹ' تشکیل دے سکتا ہے اور افراد کی دوبارہ شناخت کے لیے استعمال کیا جا سکتا ہے۔ یہ خطرہ ہے کہ اس یقین سے حاصل کیا گیا کہ ڈیٹا خود ہی بیکار ہے ، جبکہ ایسا نہیں ہے۔
ڈیٹا ، AI ، اور دیگر ٹولز اور الگورتھم کے اضافے سے شناخت کا خطرہ بڑھ جائے گا جو ڈیٹا میں پیچیدہ تعلقات کو ننگا کرنے کے قابل بناتا ہے۔ اس کے نتیجے میں ، یہاں تک کہ اگر آپ کا ڈیٹاسیٹ اب بے نقاب نہیں کیا جا سکتا ، اور غالبا today آج غیر مجاز افراد کے لیے بیکار ہے ، یہ کل نہیں ہو سکتا۔
ایک عمدہ مثال وہ صورت ہے جہاں نیٹ فلکس نے اپنے آر اینڈ ڈی ڈیپارٹمنٹ کو اپنے فلم کی سفارش کے نظام کو بہتر بنانے کے لیے ایک کھلا نیٹ فلکس مقابلہ متعارف کروا کر کراوڈ سورس کرنا چاہا۔ 'جو فلموں کے لیے صارف کی درجہ بندی کی پیش گوئی کرنے کے لیے باہمی تعاون سے فلٹرنگ الگورتھم کو بہتر بناتا ہے وہ ایک لاکھ امریکی ڈالر کا انعام جیتتا ہے'۔ ہجوم کو سپورٹ کرنے کے لیے ، نیٹ فلکس نے ایک ڈیٹاسیٹ شائع کیا جس میں صرف درج ذیل بنیادی صفات ہیں: یوزر آئی ڈی ، مووی ، گریڈ اور گریڈ کی تاریخ (لہذا صارف یا فلم کے بارے میں مزید معلومات نہیں)۔
مثال 5۔
| صارف کی شناخت | مووی | گریڈ کی تاریخ | گریڈ |
| 123456789 | ناممکن مشن | 10-12-2008 | 4 |
تنہائی میں ، ڈیٹا بیکار دکھائی دیا۔ یہ سوال پوچھتے وقت کہ 'کیا ڈیٹاسیٹ میں کسٹمر کی کوئی ایسی معلومات ہے جسے نجی رکھا جائے؟' ، جواب یہ تھا:
'نہیں ، تمام گاہکوں کی شناخت کرنے والی معلومات کو ہٹا دیا گیا ہے باقی سب ریٹنگ اور تاریخیں ہیں۔ یہ ہماری پرائیویسی پالیسی کی پیروی کرتا ہے… '
تاہم ، آسٹن میں ٹیکساس یونیورسٹی سے نارائنن (2008) دوسری صورت میں ثابت ہوا۔ گریڈ ، گریڈ کی تاریخ اور کسی فرد کی فلم کا مجموعہ ایک منفرد مووی فنگر پرنٹ بناتا ہے۔ اپنے نیٹ فلکس کے رویے کے بارے میں سوچیں۔ آپ کے خیال میں کتنے لوگوں نے ایک ہی فلم کا سیٹ دیکھا؟ کتنے لوگوں نے ایک ہی وقت میں ایک ہی فلم کا سیٹ دیکھا؟
اہم سوال ، اس فنگر پرنٹ کو کیسے ملایا جائے؟ یہ کافی سادہ تھا۔ معروف مووی ریٹنگ ویب سائٹ آئی ایم ڈی بی (انٹرنیٹ مووی ڈیٹا بیس) کی معلومات کی بنیاد پر ، اسی طرح کا فنگر پرنٹ تشکیل دیا جا سکتا ہے۔ اس کے نتیجے میں ، افراد کی دوبارہ شناخت کی جاسکتی ہے۔
اگرچہ فلم دیکھنے کے رویے کو حساس معلومات کے طور پر نہیں سمجھا جا سکتا ، اپنے رویے کے بارے میں سوچیں-اگر یہ عام ہو گیا تو کیا آپ کو برا لگے گا؟ نارائنن نے اپنے مقالے میں جو مثالیں دی ہیں وہ ہیں سیاسی ترجیحات ('جیسس آف ناصری' اور 'انجیل آف جان' پر درجہ بندی) اور جنسی ترجیحات ('بینٹ' اور 'کوئیر بطور لوک') جو آسانی سے ڈسٹل کی جا سکتی ہیں۔
جی ڈی پی آر شاید انتہائی دلچسپ نہ ہو ، اور نہ ہی بلاگ کے موضوعات میں چاندی کی گولی۔ پھر بھی ، ذاتی ڈیٹا پر کارروائی کرتے وقت تعریفیں حاصل کرنا مددگار ہے۔ چونکہ یہ بلاگ ڈیٹا کو گمنام کرنے اور آپ کو ڈیٹا پروسیسر کے طور پر تعلیم دینے کے طریقے کے طور پر کالموں کو ہٹانے کی عام غلط فہمی کے بارے میں ہے ، آئیے جی ڈی پی آر کے مطابق گمنامی کی تعریف کی تلاش شروع کرتے ہیں۔
جی ڈی پی آر کی تلاوت 26 کے مطابق ، گمنام معلومات کی وضاحت اس طرح کی گئی ہے:
'ایسی معلومات جو کسی شناخت یا پہچاننے والے قدرتی شخص یا ذاتی ڈیٹا سے متعلق نہیں ہے اس طرح گمنام کیا گیا ہے کہ ڈیٹا کا موضوع اب شناخت کے قابل نہیں ہے۔
چونکہ کوئی ذاتی ڈیٹا پر کارروائی کرتا ہے جو قدرتی شخص سے متعلق ہے ، لہذا تعریف کا صرف حصہ 2 متعلقہ ہے۔ تعریف پر عمل کرنے کے لیے ، کسی کو یہ یقینی بنانا ہوگا کہ ڈیٹا کا موضوع (انفرادی) نہیں ہے یا اب قابل شناخت نہیں ہے۔ جیسا کہ اس بلاگ میں اشارہ کیا گیا ہے ، تاہم ، چند صفات کی بنیاد پر افراد کی شناخت کرنا انتہائی آسان ہے۔ لہذا ، ڈیٹاسیٹ سے نام ہٹانا نام ظاہر نہ کرنے کی جی ڈی پی آر کی تعریف کے مطابق نہیں ہے۔
ہم نے ایک عام طور پر سمجھے جانے والے کو چیلنج کیا اور ، بدقسمتی سے ، اب بھی ڈیٹا کو گمنام کرنے کا اکثر استعمال کیا جاتا ہے: ناموں کو حذف کرنا۔ Guess Who گیم اور چار دیگر مثالوں میں:
یہ دکھایا گیا تھا کہ ناموں کو ہٹانا گمنامی کے طور پر ناکام ہوجاتا ہے۔ اگرچہ مثالیں حیرت انگیز معاملات ہیں ، ہر ایک دوبارہ شناخت کی سادگی کو ظاہر کرتی ہے۔ اور افراد کی رازداری پر ممکنہ منفی اثرات۔
آخر میں ، آپ کے ڈیٹاسیٹ سے ناموں کو حذف کرنے کا نتیجہ گمنام ڈیٹا نہیں ہوتا ہے۔ لہذا ، ہم دونوں اصطلاحات کو ایک دوسرے کے ساتھ استعمال کرنے سے گریز کرتے ہیں۔ مجھے پوری امید ہے کہ آپ گمنامی کے لیے یہ طریقہ استعمال نہیں کریں گے۔ اور ، اگر آپ اب بھی کرتے ہیں تو ، یقینی بنائیں کہ آپ اور آپ کی ٹیم رازداری کے خطرات کو پوری طرح سمجھتی ہے ، اور متاثرہ افراد کی جانب سے ان خطرات کو قبول کرنے کی اجازت ہے۔
سنتو سے رابطہ کریں۔ اور ہمارے ماہرین میں سے ایک مصنوعی ڈیٹا کی قدر کو دریافت کرنے کے لیے روشنی کی رفتار سے آپ سے رابطہ کرے گا!