

Що таке синтетичні дані?
Відповідь відносно проста. У той час як оригінальні дані збираються під час усіх ваших взаємодій з реальними особами (наприклад, клієнтами, пацієнтами, співробітниками тощо), а за допомогою всіх ваших внутрішніх процесів, синтетичні дані генеруються за допомогою комп’ютерного алгоритму. Цей комп’ютерний алгоритм генерує абсолютно нові штучні точки даних.
Вирішіть проблеми з конфіденційністю даних
Синтетично згенеровані дані складаються з абсолютно нових і штучних точок даних без зв’язків один до одного з вихідними даними. Таким чином, жодна з синтетичних точок даних не може бути простежена назад або звернена до вихідних даних. Як наслідок, синтетичні дані звільняються від правил конфіденційності, таких як GDPR, і служать рішенням для вирішення та подолання проблем конфіденційності даних.
Доповнюйте та моделюйте
Генеративний аспект генерації синтетичних даних дозволяє доповнювати та моделювати абсолютно нові дані. Це функціонує як рішення, коли у вас недостатньо даних (дефіцит даних), ви хочете збільшити вибірку граничних випадків або коли у вас ще немає даних.
Тут у центрі уваги Syntho - структуровані дані (дані, відформатовані в таблицях, що містять рядки та стовпці, як ви бачите на аркушах Excel), але ми завжди любимо ілюструвати концепцію синтетичних даних за допомогою зображень, оскільки вони більш привабливі.
Три типи синтетичних даних дійсно існують у зоні синтетичних даних. Цими 3 типами синтетичних даних є: фіктивні дані, синтетичні дані, згенеровані на основі правил, і синтетичні дані, згенеровані штучним інтелектом (ШІ). Ми коротко пояснимо, що таке 3 різні типи синтетичних даних.
Фіктивні дані – це дані, згенеровані випадковим чином (наприклад, за допомогою фіктивного генератора даних).
Отже, характеристики, зв’язки та статистичні закономірності, які є в вихідних даних, не зберігаються, не вловлюються та не відтворюються у згенерованих фіктивних даних. Отже, репрезентативність фіктивних даних / імітаційних даних мінімальна в порівнянні з вихідними даними.
Синтетичні дані, згенеровані на основі правил, — це синтетичні дані, створені попередньо визначеним набором правил. Прикладами цих попередньо визначених правил можуть бути те, що ви хотіли б мати синтетичні дані з певним мінімальним значенням, максимальним значенням або середнім значенням. Будь-які характеристики, зв’язки та статистичні моделі, які ви хотіли б відтворити в синтетичних даних, створених на основі правил, мають бути попередньо визначені.
Отже, якість даних буде такою ж високою, як і попередньо визначений набір правил. Це призводить до проблем, коли важлива висока якість даних. По-перше, можна визначити лише обмежений набір правил, які будуть фіксуватися в синтетичних даних. Крім того, встановлення кількох правил, як правило, призводить до накладання та конфлікту між правилами. Більше того, ви ніколи не зможете повністю охопити всі відповідні правила. Крім того, можуть бути відповідні правила, про які ви навіть не знаєте. І, нарешті (і не забувайте), це забере у вас багато часу та енергії, що призведе до неефективного рішення.
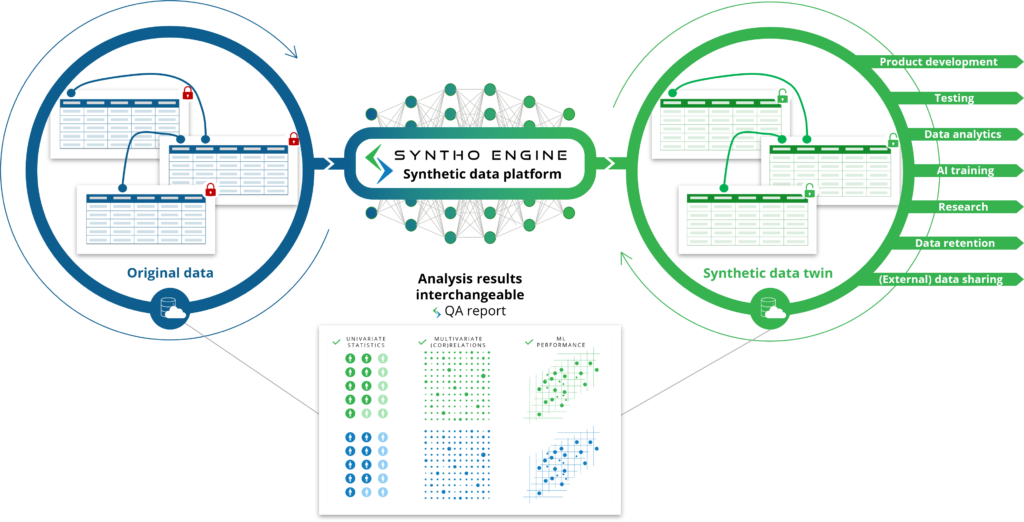
Як ви і очікували з назви, синтетичні дані, згенеровані штучним інтелектом (ШІ), є синтетичними даними, згенерованими за допомогою алгоритму штучного інтелекту (ШІ). Модель AI навчається на вихідних даних, щоб вивчити всі характеристики, відносини та статистичні моделі. Після цього цей алгоритм ШІ здатний генерувати абсолютно нові точки даних і моделювати ці нові точки даних таким чином, що він відтворює характеристики, відносини та статистичні моделі з вихідного набору даних. Це те, що ми називаємо синтетичним близнюком даних.
Модель AI імітує вихідні дані для створення синтетичних близнюків даних, які можна використовувати як оригінальні дані. Це відкриває різні випадки використання, коли синтетичні дані, згенеровані штучним інтелектом, можуть використовуватися як альтернатива для використання оригінальних (чутливих) даних, наприклад використання синтетичних даних, згенерованих AI, як тестові, демонстраційні дані або для аналітики.
Порівняно зі згенерованими на основі правил синтетичними даними: замість того, щоб ви вивчати та визначати відповідні правила, алгоритм ШІ робить це автоматично за вас. Тут будуть охоплені не лише характеристики, зв’язки та статистичні моделі, про які ви знаєте, а й характеристики, зв’язки та статистичні моделі, про які ви навіть не знаєте.
Залежно від вашого варіанту використання, рекомендується комбінувати фіктивні дані / імітаційні дані, синтетичні дані, згенеровані на основі правил, або синтетичні дані, згенеровані штучним інтелектом (ШІ). Цей огляд дає вам першу вказівку на те, який тип синтетичних даних використовувати. Оскільки Syntho підтримує всі з них, не соромтеся зв’язатися з нашими експертами, щоб вони з нами глибоко занурилися у ваш варіант використання.
