

Звіт про забезпечення якості Syntho оцінює створені синтетичні дані та демонструє точність, конфіденційність і швидкість синтетичних даних порівняно з вихідними даними.
У Syntho ми розуміємо важливість надійних і точних синтетичних даних. Ось чому ми надаємо вичерпний звіт про гарантію якості для кожного запуску синтетичних даних. Наш звіт про якість містить різні показники, такі як розподіли, кореляції, багатофакторні розподіли, показники конфіденційності тощо. Таким чином ви можете легко оцінити, що синтетичні дані, які ми надаємо, мають найвищу якість і можуть використовуватися з тим самим рівнем точності та надійності, що й ваші вихідні дані.
Коротке уявлення: цей розділ ілюструє основні моменти з нашого звіту про якість синтетичних даних. Наші оцінки порівнюють синтетичні дані з реальними даними за різними параметрами.
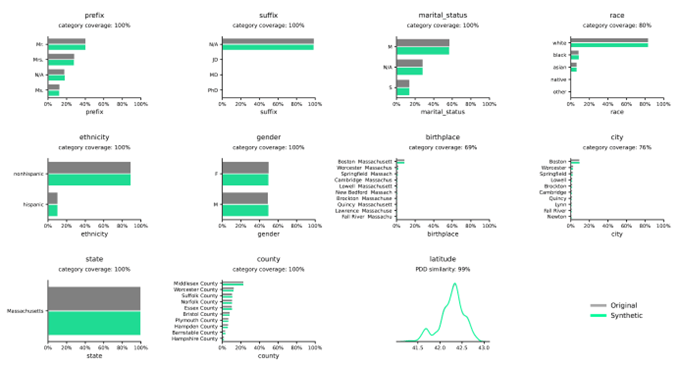
Розподіл синтетичних даних у порівнянні з реальними даними
Розподіл ілюструє частоту змінних у заданих категоріях або значеннях і точно фіксується движком Syntho.
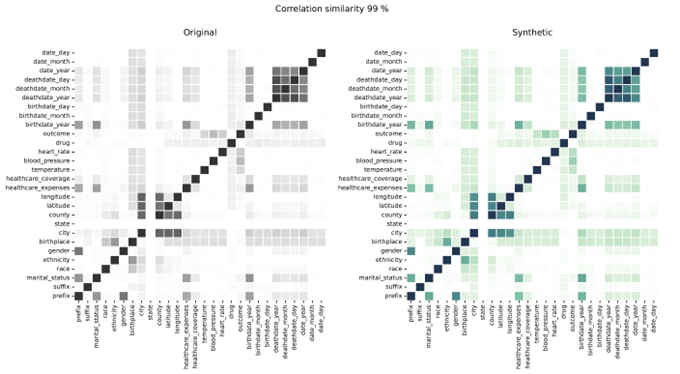
Кореляції синтетичних даних у порівнянні з реальними даними
Кореляції показують зв’язок між змінними, ілюструючи ступінь зв’язку між змінними. Syntho Engine точно фіксує ці зв’язки.
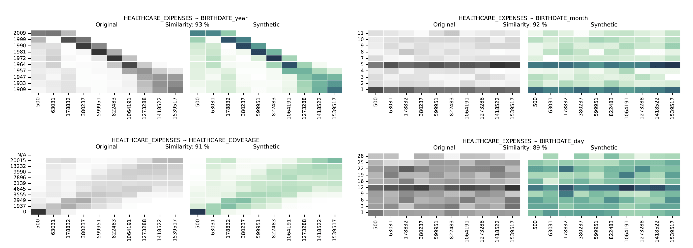
Багатофакторні розподіли синтетичних даних у порівнянні з реальними даними
Багатовимірні розподіли та багатовимірні кореляції виводять нас за межі одиничних вимірів, надаючи комплексне уявлення про те, як багато змінних пов’язані між собою. Syntho Engine враховує ці відносини.
Генерація синтетичних даних складна, і підводні камені існують, і їх потрібно контролювати. З алгоритмами AI переобладнання є ризиком, і це також стосується генерації синтетичних даних за допомогою AI. Отже, слід контролювати ризик переобладнання під час генерації синтетичних даних. Ризик переобладнання контролюється в Syntho Engine. Крім того, звіт про забезпечення якості (QA) Syntho дозволяє організаціям продемонструвати, що синтетичні дані не перевищують вихідних даних. Ми також оцінюємо аспекти, пов’язані з конфіденційністю, якими часто користуються внутрішні аудитори.
Тест на «точні збіги» з ідентичним співвідношенням збігів (IMR)
Демонстрація того, що відношення записів синтетичних даних, які збігаються з реальним записом вихідних даних, не значно перевищує відношення, яке можна очікувати під час аналізу даних поїзда.
Тест на «Схожі матчі» з відстанню до найближчого запису (DCR)
Демонстрація того, що нормалізована відстань для записів синтетичних даних до їх найближчого фактичного запису в межах вихідних даних не є значно ближчою, ніж відстань, яку можна очікувати під час аналізу даних поїзда.
Тест на «Викиди» з Коефіцієнт відстані найближчого сусіда (NNDR)
Демонстрація того, що відношення відстані між найближчим і другим найближчим синтетичним записом до їх найближчого запису в оригінальних даних не є значно ближчим, ніж відношення, яке слід очікувати для даних поїзда.
Це лише короткий знімок, який підсумовує суть нашого дослідження якості синтетичних даних і звіту про забезпечення якості. Він пропонує детальне розуміння розподілу, кореляції та багатовимірного розподілу як частини синтетичних даних, зібраних розширеними можливостями Syntho Engine. Додаткову інформацію про наш звіт про забезпечення якості можна отримати за запитом.