


Синтетичні дані, створені Syntho, оцінюються, перевіряються та затверджуються з зовнішньої та об’єктивної точки зору експертами з даних SAS.
Хоча Syntho з гордістю пропонує своїм користувачам розширений звіт про забезпечення якості, ми також розуміємо важливість зовнішньої та об’єктивної оцінки наших синтетичних даних від лідерів галузі. Ось чому ми співпрацюємо з SAS, лідером у сфері аналітики, щоб оцінити наші синтетичні дані.
SAS проводить різні ретельні оцінки точності даних, захисту конфіденційності та зручності використання синтетичних даних, згенерованих штучним інтелектом Syntho, у порівнянні з вихідними даними. У підсумку SAS оцінила та схвалила синтетичні дані Syntho як точні, безпечні та придатні для використання порівняно з вихідними даними.
Ми використали телекомунікаційні дані, які використовуються для прогнозування «відтоку», як цільові дані. Метою оцінки було використання синтетичних даних для навчання різних моделей прогнозування відтоку та оцінки ефективності кожної моделі. Оскільки прогнозування відтоку є завданням класифікації, SAS вибрала популярні моделі класифікації, щоб зробити прогнози, зокрема:
Перш ніж генерувати синтетичні дані, SAS випадковим чином розбиває набір телекомунікаційних даних на набір поїздів (для навчання моделей) і набір затримки (для оцінки моделей). Наявність окремого набору утримування для оцінки дозволяє неупереджено оцінити, наскільки добре модель класифікації може бути застосована до нових даних.
Використовуючи набір поїздів як вхідні дані, Syntho використовував свій Syntho Engine для створення синтетичного набору даних. Для порівняльного аналізу SAS також створила анонімну версію набору після застосування різних методів анонімізації для досягнення певного порогу (k-анонімності). Попередні кроки призвели до чотирьох наборів даних:
Набори даних 1, 3 і 4 використовувалися для навчання кожної моделі класифікації, в результаті чого було отримано 12 (3 x 4) навчених моделей. Згодом SAS використовував набір даних про утримання, щоб виміряти точність кожної моделі в прогнозуванні відтоку клієнтів.
SAS проводить різні ретельні оцінки точності даних, захисту конфіденційності та зручності використання синтетичних даних, згенерованих штучним інтелектом Syntho, у порівнянні з вихідними даними. У підсумку SAS оцінила та схвалила синтетичні дані Syntho як точні, безпечні та придатні для використання порівняно з вихідними даними.
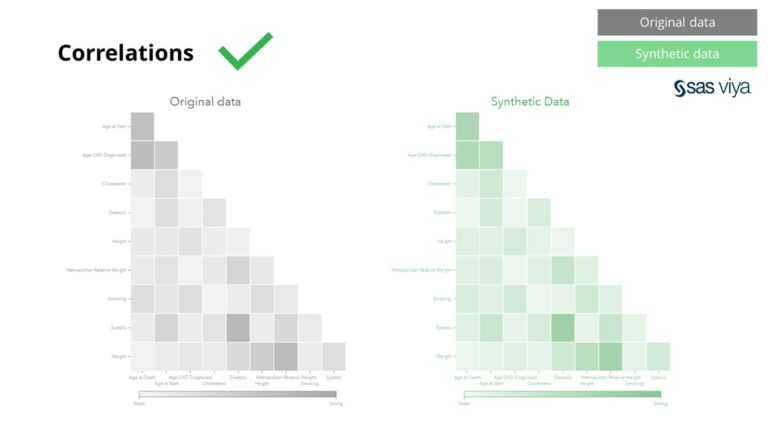
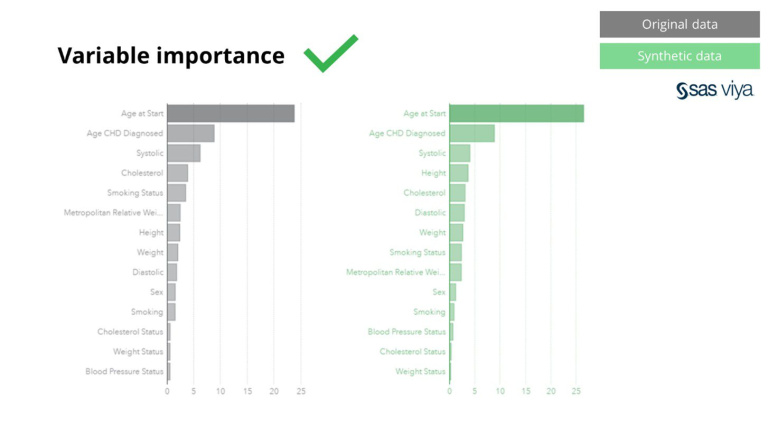
Синтетичні дані від Syntho зберігають не лише базові шаблони, вони також фіксують глибокі «приховані» статистичні шаблони, необхідні для розширених аналітичних завдань. Останнє показано на гістограмі, яка вказує на те, що точність моделей, навчених на синтетичних даних, порівняно з моделями, навченими на вихідних даних, однакова. Отже, синтетичні дані можуть бути використані для реального навчання моделей. Вхідні дані та важливість змінної, вибрані алгоритмами на синтетичних даних, порівняно з оригінальними даними, були дуже схожими. Таким чином, можна зробити висновок, що процес моделювання можна виконувати на синтетичних даних, як альтернативу використанню реальних конфіденційних даних.
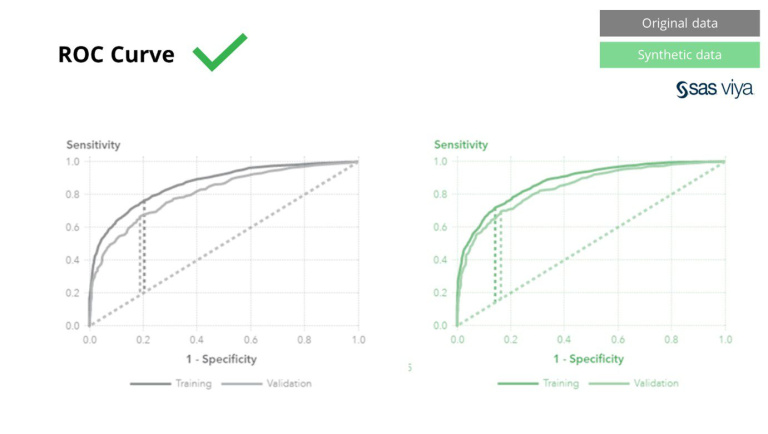
Спільним для класичних методів анонімізації є те, що вони маніпулюють вихідними даними, щоб перешкодити відстеженню осіб. Вони маніпулюють даними і тим самим знищують дані в процесі. Чим більше ви анонімізуєте, тим краще ваші дані захищені, але також тим більше ваші дані знищуються. Це особливо руйнівно для задач штучного інтелекту та моделювання, де «передбачувальна здатність» є важливою, оскільки дані поганої якості призведуть до поганої інформації від моделі ШІ. SAS продемонструвала це з площею під кривою (AUC*), близькою до 0.5, демонструючи, що моделі, навчені на анонімних даних, працюють найгірше.
Кореляції та зв’язки між змінними були точно збережені в синтетичних даних.
Площа під кривою (AUC), метрика для вимірювання ефективності моделі, залишалася незмінною.
Крім того, важливість змінної, яка вказувала на прогностичну силу змінних у моделі, залишалася незмінною під час порівняння синтетичних даних із вихідним набором даних.
На основі цих спостережень SAS і використання SAS Viya ми можемо впевнено зробити висновок, що синтетичні дані, згенеровані Syntho Engine, справді відповідають реальним даним щодо якості. Це підтверджує використання синтетичних даних для розробки моделей, прокладаючи шлях до розширеної аналітики за допомогою синтетичних даних.
