Сканер ідентифікаційної інформації
ідентифікувати прямі ідентифікатори (наприклад PII і PHI) автоматично за допомогою нашого сканера ідентифікаційної інформації на основі штучного інтелекту
Про сканер ідентифікаційної інформації
Сканер стовпців ідентифікаційної інформації
Зменшити ручну роботу та використовувати наша ідентифікаційна інформація колонка сканер до ідентифікувати стовпців у вашій базі даних що містить прямий ідентифікатори (PII/PHI) з потужністю ШІ.
Сканер тексту ідентифікаційної інформації
Зменшити ручну роботу та використовувати наша ідентифікаційна інформація текст сканер до iідентифікувати прямі ідентифікатори (PII/PHI) всередині безкоштовно текстові поля з потужністю ШІ.
Представляємо сканер стовпців ідентифікаційної інформації
Leverage our Можливість Сканер ідентифікаційної інформації для автоматичного виявлення стовпців і екземпляри у вашій базі даних що містить прямий ідентифікатори, такі як Інформація, що дозволяє ідентифікувати особу (PII) та Захищена медична інформація (PHI). один раз стовпців що містить PII визнані, наша платформа полегшує методи деідентифікації, такі як видалення, заміна фіктивними даними або синтез, зміцнюючи конфіденційність бази даних.

Ключові переваги сканера стовпців ідентифікаційної інформації на основі штучного інтелекту
Eавтоматично ідентифікувати ідентифікаційну інформацію за допомогою ШІ
1. Посилений dата pнеприватність: Сканер PII на основі штучного інтелекту автоматично забезпечує підвищену конфіденційність даних ідентифікує і позначення особистої ідентифікаційної інформації (PII) у наборах даних
2. Відповідність з rнормативні акти: Швидко і точно ідентифікує Елементи ідентифікаційної інформації, сканер на основі штучного інтелекту допомагає організаціям дотримуватися нормативних вимог, таких як GDPR, HIPAA та CCPA
3. Час і cost sавінги: Автоматизація процесу виявлення ідентифікаційної інформації значно скорочує час і ресурси вимагається для перевірки даних вручну, що дозволяє організаціям досягати відповідності більш ефективно та економічно.
Як користуватися сканером стовпців ідентифікаційної інформації
Як я можу використовувати сканер ідентифікаційної інформації?
Сканер ідентифікаційної інформації можна легко налаштувати через наш інтерфейс користувача на вкладці «Ідентифікаційна інформація». Ця функція має два варіанти сканування: (1) поверхневе сканування (лише метадані, включаючи назви стовпців) і (2) глибоке сканування (метадані + і самі дані). Усі стовпці, визначені як ідентифікаційна інформація, відображаються в списку ідентифікаційних сутностей на вкладці ідентифікаційна інформація та позначені як ідентифікаційна інформація в заголовку стовпця на вкладці «Параметри роботи».
Автоматично застосовуйте насмішки до ідентифікаційної інформації
Окрім автоматичної ідентифікації ідентифікаційної інформації, наша платформа також автоматично пропонує правильний мокер для кожної особи ідентифікаційної інформації, заощаджуючи час і зусилля користувача. Використовуючи цю функцію, користувачі можуть переконатися, що конфіденційна оригінальна ідентифікаційна інформація захищена та замінена репрезентативними фіктивними даними зі збереженням посилальної цілісності для багатотабличних баз даних за допомогою нашої функції узгодженого зіставлення.

Чи можу я також ідентифікувати ідентифікаційну інформацію вручну?
Так, користувачі також можуть ідентифікувати ідентифікаційні сутності вручну як альтернативу сканеру ідентифікаційної інформації. Користувачі також можуть застосовувати мокери вручну як альтернативу автоматичним запропонованим мокерам. Однак ми оптимізували нашу платформу таким чином, щоб штучний інтелект виконував роботу за вас, щоб зменшити ручну роботу та мати можливість швидко обробляти великі обсяги даних.
Ознайомтеся з нашим документом сканера ідентифікаційної інформації
Дізнайтеся, як ШІ полегшує обфускацію даних
Представляємо текстовий сканер ідентифікаційної інформації
Запустіть текстовий сканер ідентифікаційної інформації
Використовуйте текстовий сканер ідентифікаційної інформації, щоб виконати поглиблений аналіз ваших даних, виявляючи будь-яку особисту інформацію (PII), наявну в поля, що містять вільний текст.
Скористайтесь наші синтетичні макетні дані техніки для заміни PII з насмішниками.
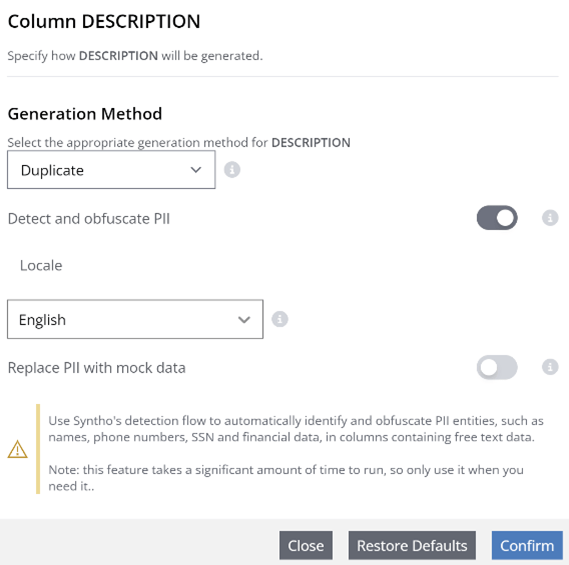
Як користуватися текстовим сканером ідентифікаційної інформації?
1 – видалити ідентифіковану ідентифікаційну інформацію
Syntho Engine дозволяє користувачам видаляти ідентифікаційну інформацію. Після видалення ідентифікаційної інформації її буде просто видалено з даних або замінено значенням за замовчуванням, наприклад «*» або «PII». Це дозволяє організаціям захищати інформацію.
Приклад: вихідний текст із ідентифікованою ідентифікаційною інформацією:
"Джон Сміт звернувся за позикою в розмірі $10,000 з нашим банком 03/01/2023. Він надав свій номер соціального страхування (123-45-6789), дата народження (01/01/1985), а також відомості про роботу (Синто). Наш кредитний спеціаліст провів кредитну перевірку та підтвердив його інформацію. Виходячи з його кредитної історії та трудової історії, він отримав дозвіл на позику, і кошти були перераховані на його рахунок 03/03/2023».
2 – замінити ідентифікаційну інформацію на сутність
Syntho Engine дозволяє користувачам замінювати ідентифікаційну інформацію об’єктом. Сутність – це заповнювач, який замінює певну ідентифікаційну інформацію для захисту конфіденційності особи.
Коли ідентифікаційна інформація замінюється сутностями, конфіденційна інформація, як-от імена чи дати, замінюється заповнювачами, наприклад « » або « ”. Це дозволяє організаціям підтримувати структуру своїх даних, одночасно захищаючи конфіденційну інформацію, що міститься в них.
Текст із ідентифікаційною інформацією, заміненою об’єктами:
" звернувся за позикою в розмірі з нашим банком . Вони надали свій номер соціального страхування (), дата народження (), а також відомості про роботу (). Наш кредитний спеціаліст провів кредитну перевірку та підтвердив їхню інформацію. На підставі їхнього кредитного рейтингу та трудової історії вони отримали схвалення на позику, і кошти були перераховані на їхній рахунок ».
3 - замінювати ідентифікував ідентифікаційну інформацію з насмішником
Подібним чином Syntho Engine дозволяє користувачам замінювати ідентифікаційну інформацію на мокер. Мокер — це фіктивне значення, яке використовується для заміни конкретної ідентифікаційної інформації. Значення мокерів не є реальними та не мають відношення до вихідних даних, але вони зберігають той самий формат, що й вихідні дані, щоб зберегти їх зручність використання.
Коли ідентифікаційна інформація замінюється насмішниками, конфіденційна інформація замінюється фіктивними даними. У цьому випадку конфіденційна інформація, як-от імена чи дати, замінюється фіктивними іменами, наприклад «Вім Кіз», або фіктивними датами, наприклад «03-05-2023». Це дозволяє організаціям підтримувати свою структуру та мати репрезентативну макетну цінність як альтернативу, одночасно захищаючи конфіденційну інформацію, що міститься в ній.
Текст із ідентифікаційною інформацією, заміненою насмішками:
"Джейк Браун звернувся за позикою в розмірі $23,340 з нашим банком 12/11/2023. Вони надали свій номер соціального страхування (987-65-4321), дата народження (04/02/1989), а також відомості про роботу (Компанія XYZ). Наш кредитний спеціаліст провів кредитну перевірку та підтвердив їхню інформацію. На підставі їхнього кредитного рейтингу та трудової історії вони отримали схвалення на позику, і кошти були перераховані на їхній рахунок 13/12/2023».
Текст із ідентифікаційною інформацією, заміненою значенням за замовчуванням "PII":
"PII звернувся за позикою в розмірі PII з нашим банком PII. Вони надали свій номер соціального страхування (PII), дата народження (PII), а також відомості про роботу (PII). Наш кредитний спеціаліст провів кредитну перевірку та підтвердив їхню інформацію. На підставі їхнього кредитного рейтингу та трудової історії вони отримали схвалення на позику, і кошти були перераховані на їхній рахунок PII».
Що таке PII?
Визначення ідентифікаційної інформації
PII стенди для Особиста ідентифікаційна інформація. Ідентифікаційна інформація є унікальною для кожної людини, і лише одна особа має таку саму рису. Дізнайтеся більше про визначення ідентифікаційної інформації тут.
Чому організації використовують сканер стовпців ідентифікаційної інформації?
Щоб ініціювати деідентифікацію, важливо ідентифікувати стовпці, що містять персональну інформацію (PII). Однак це часто вимагає від розробників багато часу та ручних зусиль.
Наше рішення спрощує цей процес за допомогою автоматизованого сканера ідентифікаційної інформації, що дозволяє клієнтам ефективно ідентифікувати та деідентифікувати ідентифікаційну інформацію за допомогою нашого сканера ідентифікаційної інформації на основі штучного інтелекту. Наше передове рішення на основі штучного інтелекту усуває ручні зусилля, підвищуючи ефективність і забезпечуючи повну автоматичну ідентифікацію конфіденційних даних.
Чи можу я також ідентифікувати ідентифікаційну інформацію вручну?
Так, користувачі також можуть ідентифікувати ідентифікаційні сутності вручну як альтернативу сканеру ідентифікаційної інформації. Користувачі також можуть застосовувати мокери вручну як альтернативу автоматичним запропонованим мокерам. Однак ми оптимізували нашу платформу таким чином, щоб штучний інтелект виконував роботу за вас, щоб зменшити ручну роботу та мати можливість швидко обробляти великі обсяги даних.

Ознайомтеся з документом про сканер ідентифікаційної інформації
- Що таке PII?
- Чому ідентифікаційна інформація важлива?
- Як працює сканер ідентифікаційної інформації?
- Сканування ідентифікаційної інформації та синтетичні дані, створені штучним інтелектом
