


Замініть конфіденційні ідентифікаційні дані, PHI та інші ідентифікатори репрезентативними синтетичними фіктивними даними, які відповідають бізнес-логіці та шаблонам.
PII означає Personal Identifiable Information. PHI розшифровується як Personal Health Information і є розширеною версією ідентифікаційної інформації, призначеної для інформації про здоров’я. І PII, і PHI є ідентифікаторами та стосуються будь-якої інформації, яка може бути використана для безпосереднього розрізнення або відстеження особистості людини. Тут з ідентифікаторами лише одна особа поділяє цю рису.
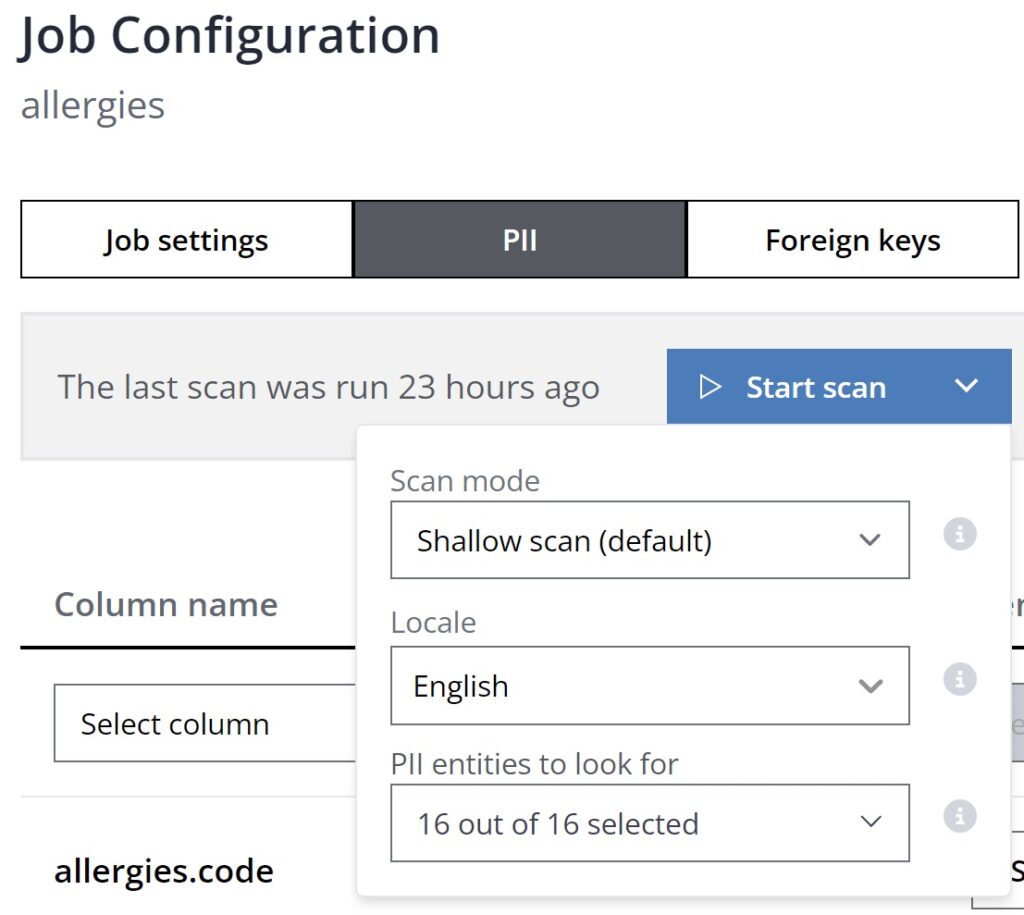
Ідентифікаційна інформація, PHI та інші прямі ідентифікатори є чутливими, і їх можна виявити вручну або автоматично за допомогою нашого сканера ідентифікаційної інформації, щоб заощадити час і мінімізувати ручну роботу. Потім можна застосувати Mockers, щоб замінити реальні значення фіктивними значеннями, щоб деідентифікувати дані та підвищити конфіденційність.
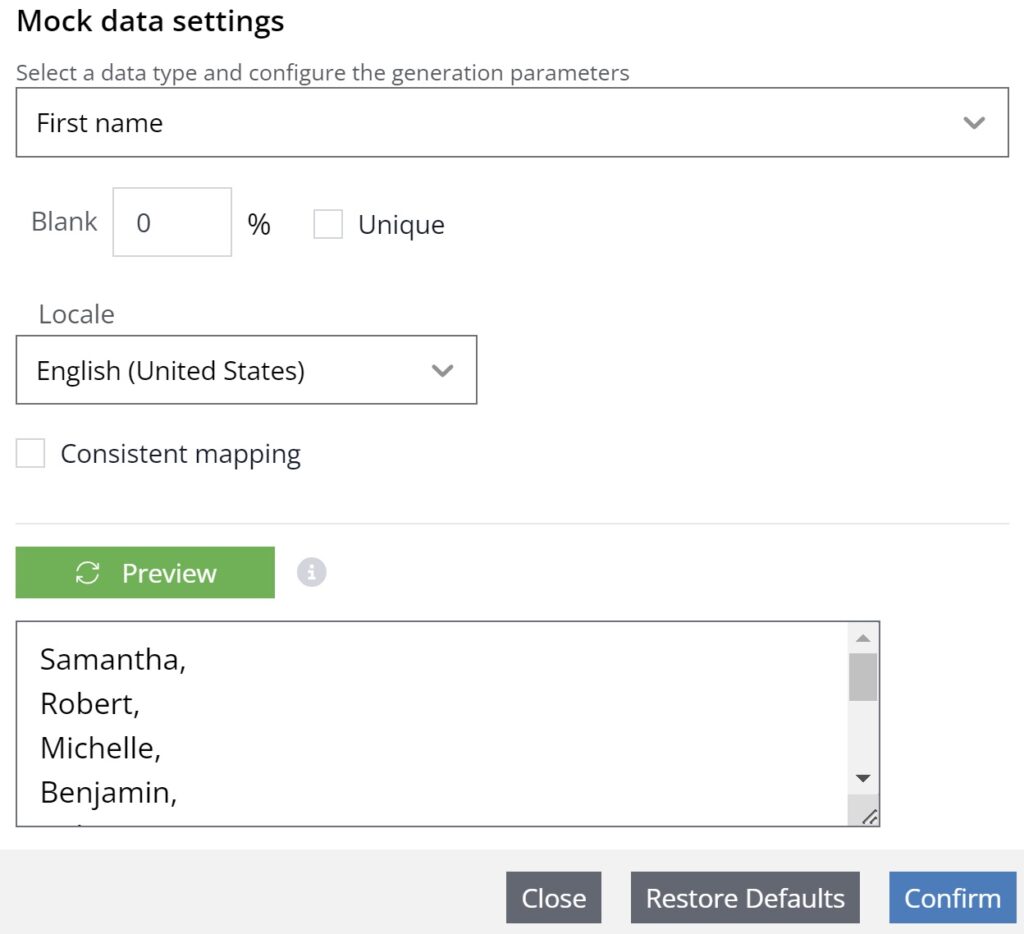
Syntho підтримує +150 різних мокерів, які також доступні різними мовами та алфавітами. Syntho підтримує типові мокери, такі як ім’я, прізвище, номери телефонів, а також більш просунуті мокери для створення імітаційних даних, які можуть відповідати вашим визначеним бізнес-правилам.
Наша платформа надає широкий спектр просунутих мокерів, здатних створювати синтетичні дані з нуля або дотримуючись попередньо визначених правил. Ці розширені мокери пропонують параметри налаштування, що дозволяє адаптувати їх до конкретних випадків використання або сценаріїв, що робить їх універсальними та потужними для синтетичних даних, створених на основі правил. Це розумне рішення для генерації значних наборів автентичних даних, що ідеально підходить для тестування та розробки.
Ви можете легко застосувати мокери за допомогою нашої зручної платформи. На нашій платформі ми маємо два різні способи застосування мокерів: на вкладці «Налаштування роботи» або на вкладці «Ідентифікаційна інформація».
Скануйте ідентифікаційну інформацію автоматично за допомогою нашого сканера ідентифікаційної інформації на базі штучного інтелекту або визначте стовпці, які ви хотіли б імітувати.
Виберіть запропонований насмішник нашим сканером ідентифікаційної інформації або налаштувати мокери на рівні стовпців.
Підтвердьте застосування вибраного мокера до стовпця на вкладці ідентифікаційної інформації або конфігурації завдання.
