Невидимий винуватець штучного інтелекту: розгадка внутрішнього упередження
Серія блогів Bias: частина 1
Вступ
У нашому світі все більш штучних форм інтелекту машини, яким доручено приймати складні рішення, стають все більш поширеними. Зростає кількість літератури, яка вказує на використання штучного інтелекту в різних сферах, наприклад у бізнесі, прийнятті важливих рішень, а за останні кілька років – у медичному секторі. Однак із зростаючою поширеністю люди помітили тривожні тенденції у зазначених системах; Тобто, незважаючи на те, що вони за своєю суттю створені для суто слідування шаблонам у даних, вони демонструють ознаки упередженого ставлення, у тому сенсі, що можна спостерігати різну сексистську та дискримінаційну поведінку. Останні Європейський закон про штучний інтелект, також досить широко висвітлює питання таких упереджень і закладає основу для вирішення пов’язаних з ними проблем.
Протягом багатьох років технічної документації люди, як правило, використовували термін «упередженість», щоб описати цей викривлений тип поведінки щодо певних демографічних груп; слово, значення якого змінюється, викликаючи плутанину та ускладнюючи завдання звернення до нього.
Ця стаття є першою в серії публікацій блогу, присвячених темі упередженості. У цій серії ми постараємося дати вам чітке, доступне розуміння упередженості в ШІ. Ми представимо способи вимірювання та мінімізації упередженості та дослідимо роль синтетичних даних на цьому шляху до більш справедливих систем. Ми також розповімо вам, як Syntho, провідний гравець у генерації синтетичних даних, може зробити свій внесок у цю роботу. Отже, незалежно від того, чи ви практик, який шукає практичну інформацію, чи просто цікавитеся цією темою, ви в потрібному місці.
Упередженість у дії: реальний приклад
Ви можете запитати: «Ця упередженість ШІ важлива, але що це означає для мене, для звичайних людей?» Правда полягає в тому, що вплив далекосяжний, часто непомітний, але потужний. Упередження в штучному інтелекті – це не просто академічна концепція; це реальна проблема з серйозними наслідками.
Візьмемо як приклад голландський скандал із соціальною допомогою. Автоматизована система, нібито інструмент, створений для отримання чесних і ефективних результатів з мінімальним людським втручанням, була упередженою. Він помилково позначив тисячі батьків за шахрайство на основі недостовірних даних і припущень. Результат? Сім’ї, які потрапили в безлад, особиста репутація зіпсована та фінансові труднощі, усе через упередженість у системі ШІ. Саме такі приклади підкреслюють нагальність усунення упередженості в ШІ.

Джерело: «Compensatie ouders toeslagenaffaire kan zomaar tot 2030 duren”, 2023. США
Але давайте не зупинятися на досягнутому. Цей інцидент не є поодиноким випадком упередженості, що сіє хаос. Вплив упередженості ШІ поширюється на всі сфери нашого життя. Від того, кого наймають на роботу, хто отримує схвалення на позику, до того, хто отримує яке лікування – упереджені системи ШІ можуть увічнити існуючу нерівність і створити нову.
Подумайте про це: система штучного інтелекту, навчена на упереджених історичних даних, може відмовити висококваліфікованому кандидату в роботі просто через його стать або етнічну приналежність. Або упереджена система штучного інтелекту може відмовити в позиці гідному кандидату через його поштовий індекс. Це не просто гіпотетичні сценарії; вони відбуваються прямо зараз.
Конкретні типи упереджень, такі як історичне упередження та упередження вимірювання, призводять до таких помилкових рішень. Вони притаманні даним, глибоко вкорінені в суспільних упередженнях і відображені в нерівних результатах для різних демографічних груп. Вони можуть спотворити рішення прогнозних моделей і призвести до несправедливого ставлення.
У великій схемі речей упередженість у ШІ може діяти як мовчазний впливовий фактор, непомітно формуючи наше суспільство та наше життя, часто таким чином, що ми навіть не усвідомлюємо. Усі ці вищезазначені моменти можуть наштовхнути вас на запитання, чому не було вжито заходів для зупинки та чи можливо це взагалі.
Дійсно, з новими технологічними досягненнями вирішення такої проблеми стає дедалі доступнішим. Першим кроком до вирішення цієї проблеми, однак, є розуміння та визнання її існування та впливу. Наразі визнання його існування створено, залишаючи питання «розуміння» все ще досить розпливчастим.
Розуміння упередженості
Хоча оригінальне визначення упередженості, представлене в Кембриджський словник не віддаляється надто далеко від головної мети слова, оскільки воно стосується штучного інтелекту, потрібно багато різних тлумачень навіть цього єдиного визначення. Таксономії, наприклад, представлені такими дослідниками, як Хеллстрьом та інші (2020) та Клігр (2021), надають глибше розуміння визначення упередженості. Однак простий погляд на ці документи покаже, що для ефективного вирішення проблеми потрібне значне звуження визначення терміну.
Хоча це зміна подій, щоб оптимально визначити та передати значення упередженості, можна краще визначити протилежне, тобто справедливість.
Визначення справедливості
Як це визначено в різноманітній новітній літературі, наприклад Кастельново та ін. (2022), справедливість може бути детально викладена, якщо зрозуміти термін потенційний простір. По суті, потенціальний простір (ПС) відноситься до обсягу можливостей і знань індивіда незалежно від його приналежності до певної демографічної групи. Враховуючи таке визначення поняття PS, можна легко визначити справедливість як рівність ставлення до двох осіб з однаковими PS, незалежно від їхніх спостережуваних і прихованих відмінностей у параметрах, що викликають упередження (таких як раса, вік або стать). Будь-яке відхилення від цього визначення, яке також називають рівністю можливостей, є явним свідченням упередженості та заслуговує на подальше дослідження.
Практики серед читачів можуть помітити, що досягнення чогось, як тут визначено, може бути абсолютно неможливим з огляду на властиві упередження, які існують у нашому світі. Це правда! Світ, у якому ми живемо, разом із усіма даними, зібраними з подій у цьому світі, піддається значній історичній та статистичній упередженості. Це справді зменшує впевненість у тому, що одного дня ми зможемо повністю пом’якшити вплив упередженості на прогнозні моделі, навчені на таких «упереджених» даних. Однак, використовуючи різні методи, можна спробувати мінімізувати вплив упередженості. У цьому випадку термінологія, яка використовується в решті публікацій блогу, зміниться в бік мінімізації впливу упередженості, а не повного його пом’якшення.
Гаразд! Отже, тепер, коли виникла ідея про те, що таке упередженість і як можна потенційно оцінити її існування; Проте, якщо ми хочемо правильно вирішити проблему, нам потрібно знати, звідки походять усі ці упередження.
Розуміння джерел і типів
Існуючі дослідження дають цінну інформацію про різні типи упереджень у машинному навчанні. як Мехрабі та ін. al. (2019) продовжили розділяти упередження в машинному навчанні, можна розділити упередження на 3 основні категорії. А саме:
- Дані до алгоритму: категорія, що охоплює упередження, які походять від самих даних. Це може бути спричинено поганим збором даних, властивими упередженнями, які існують у світі, тощо.
- Алгоритм для користувача: категорія, зосереджена на упередженнях, які випливають із дизайну та функціональності алгоритмів. Він включає в себе те, як алгоритми можуть інтерпретувати, зважувати або враховувати певні точки даних порівняно з іншими, що може призвести до необ’єктивних результатів.
- Від користувача до даних: стосується упереджень, які виникають у результаті взаємодії користувача з системою. Спосіб, у який користувачі вводять дані, їхні притаманні упередження або навіть їхня довіра до вихідних даних системи можуть впливати на результати.
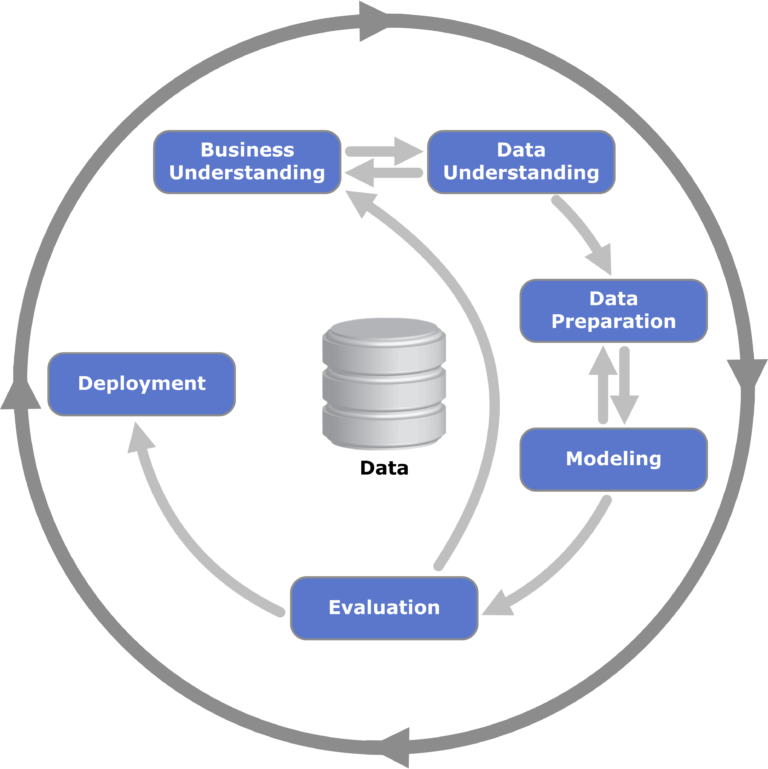
Рисунок 1: Візуалізація структури CRISP-DM для аналізу даних; зазвичай використовується в інтелектуальному аналізі даних і має відношення до процесу визначення етапів, на яких може виникнути зміщення.
Хоча назви вказують на форму упередженості, все одно можуть виникнути запитання щодо типів упереджень, які можна класифікувати під цими загальними термінами. Для ентузіастів серед наших читачів ми надали посилання на деяку літературу, пов’язану з цією термінологією та класифікацією. Заради простоти в цій публікації блогу ми розглянемо кілька вибраних упереджень, які стосуються ситуації (майже всі з них належать до категорії даних для алгоритму). Нижче наведено конкретні типи упереджень:
- Історичне упередження: тип упередженості, властивий даним, викликаний природними упередженнями, які існують у світі в різних соціальних групах і суспільстві загалом. Саме через властивість цих даних у світі їх неможливо пом’якшити за допомогою різних засобів вибірки та відбору ознак.
- Упередження вимірювання та упередження представлення: ці два тісно пов’язані упередження виникають, коли різні підгрупи набору даних містять неоднакову кількість «сприятливих» результатів. Таким чином, цей тип упередження може спотворити результати прогнозних моделей
- Алгоритмічний зсув: зсув, пов’язаний виключно з використовуваним алгоритмом. Як також спостерігалося в проведених тестах (докладніше про це йдеться далі в публікації), цей тип упередженості може мати величезний вплив на справедливість певного алгоритму.
Ці базові уявлення про упередженість у машинному навчанні будуть використані для більш ефективного вирішення проблеми в наступних публікаціях.
Заключні думки
У цьому дослідженні упередженості штучного інтелекту ми висвітлили глибокі наслідки, які він має для нашого світу, який дедалі більше керується ШІ. Починаючи з реальних прикладів, таких як голландський скандал із благополуччям дітей, і закінчуючи складними нюансами категорій і типів упередженості, очевидно, що визнання та розуміння упередженості має першочергове значення.
Хоча проблеми, пов’язані з упередженнями — історичними, алгоритмічними чи спричиненими користувачами — значні, вони не є непереборними. Маючи тверде розуміння походження та проявів упередженості, ми краще підготовлені для їх вирішення. Однак визнання та розуміння – це лише відправна точка.
У міру того, як ми просуваємось у цій серії, наша наступна увага буде зосереджена на матеріальних інструментах і структурах, які є в нашому розпорядженні. Як ми вимірюємо ступінь упередженості в моделях ШІ? І що важливіше, як ми мінімізуємо його вплив? Це нагальні питання, які ми розглянемо далі, гарантуючи, що штучний інтелект продовжує розвиватися в напрямку, який є справедливим і продуктивним.

Дані синтетичні, але наша команда справжня!
Зверніться до компанії Syntho і один з наших експертів зв’яжеться з вами зі швидкістю світла, щоб вивчити цінність синтетичних даних!