

कृत्रिम डेटा म्हणजे काय?
उत्तर तुलनेने सोपे आहे. वास्तविक डेटा (उदा. क्लायंट, रुग्ण, कर्मचारी इ.) आणि तुमच्या सर्व अंतर्गत प्रक्रियांद्वारे तुमच्या सर्व संवादांमध्ये मूळ डेटा गोळा केला जातो, तर संगणक अल्गोरिदमद्वारे कृत्रिम डेटा तयार केला जातो. हा संगणक अल्गोरिदम पूर्णपणे नवीन आणि कृत्रिम डेटापॉइंट्स तयार करतो.
डेटा गोपनीयता आव्हाने सोडवा
सिंथेटिकरीत्या व्युत्पन्न केलेल्या डेटामध्ये पूर्णपणे नवीन आणि कृत्रिम डेटापॉइंट्स असतात ज्यात मूळ डेटाशी एक-टू-वन संबंध नसतात. म्हणून, कोणतेही सिंथेटिक डेटापॉईंट शोधले जाऊ शकत नाहीत किंवा मूळ डेटावर इंजिनियर केले जाऊ शकत नाहीत. परिणामी, सिंथेटिक डेटा GDPR सारख्या गोपनीयतेच्या नियमांपासून मुक्त आहे आणि डेटा-गोपनीयतेची आव्हाने सोडवण्यासाठी आणि त्यावर मात करण्यासाठी उपाय म्हणून काम करतो.
वाढवा आणि अनुकरण करा
सिंथेटिक डेटा निर्मितीचे जनरेटिव्ह पैलू पूर्णपणे नवीन डेटा वाढविण्यास आणि अनुकरण करण्यास अनुमती देते. जेव्हा तुमच्याकडे पुरेसा डेटा नसतो (डेटा टंचाई), नमुना एज-केस अप-सॅम्पल करू इच्छितो किंवा तुमच्याकडे डेटा नसतो तेव्हा हे उपाय म्हणून कार्य करते.
येथे, सिंथोचा फोकस स्ट्रक्चर्ड डेटा आहे (पंक्ती आणि स्तंभ असलेल्या सारण्यांमध्ये डेटा स्वरूपित, जसे आपण एक्सेल शीटमध्ये पाहता), परंतु आम्हाला नेहमीच प्रतिमांद्वारे सिंथेटिक डेटाची संकल्पना स्पष्ट करणे आवडते, कारण ते अधिक आकर्षक आहे.
सिंथेटिक डेटा अंब्रेलामध्ये तीन प्रकारचे सिंथेटिक डेटा अस्तित्त्वात आहे. ते 3 प्रकारचे सिंथेटिक डेटा आहेत: डमी डेटा, नियम-आधारित व्युत्पन्न सिंथेटिक डेटा आणि कृत्रिम बुद्धिमत्ता (AI) द्वारे व्युत्पन्न केलेला कृत्रिम डेटा. सिंथेटिक डेटाचे 3 विविध प्रकार काय आहेत हे आम्ही लवकरच स्पष्ट करतो.
डमी डेटा यादृच्छिकपणे व्युत्पन्न केलेला डेटा असतो (उदा. मॉक डेटा जनरेटरद्वारे).
परिणामी, मूळ डेटामध्ये असलेली वैशिष्ट्ये, नातेसंबंध आणि सांख्यिकीय नमुने व्युत्पन्न केलेल्या डमी डेटामध्ये जतन, कॅप्चर आणि पुनरुत्पादित केले जात नाहीत. म्हणून, मूळ डेटाच्या तुलनेत डमी डेटा / मॉक डेटाचे प्रतिनिधीत्व कमी आहे.
नियम-आधारित व्युत्पन्न सिंथेटिक डेटा हा पूर्व-परिभाषित नियमांच्या संचाद्वारे व्युत्पन्न केलेला कृत्रिम डेटा आहे. त्या पूर्व-परिभाषित नियमांची उदाहरणे अशी असू शकतात की तुम्हाला विशिष्ट किमान मूल्य, कमाल मूल्य किंवा सरासरी मूल्यासह सिंथेटिक डेटा हवा आहे. तुम्ही नियम-आधारित व्युत्पन्न केलेल्या सिंथेटिक डेटामध्ये पुनरुत्पादित करू इच्छित असलेली कोणतीही वैशिष्ट्ये, नातेसंबंध आणि सांख्यिकीय नमुने, पूर्व-परिभाषित करणे आवश्यक आहे.
परिणामी, डेटा गुणवत्ता पूर्व-परिभाषित नियमांप्रमाणेच चांगली असेल. उच्च डेटा गुणवत्तेचे सार असताना यामुळे आव्हाने येतात. प्रथम, सिंथेटिक डेटामध्ये कॅप्चर करण्यासाठी केवळ मर्यादित नियमांची व्याख्या करता येते. याव्यतिरिक्त, एकाधिक नियम सेट केल्याने सामान्यतः आच्छादित आणि विरोधाभासी नियम होतात. शिवाय, तुम्ही कधीही सर्व संबंधित नियम पूर्णपणे कव्हर करणार नाही. शिवाय, असे संबंधित नियम असू शकतात ज्यांची तुम्हाला माहितीही नसते. आणि शेवटी (आणि विसरू नका), हे तुम्हाला खूप वेळ आणि ऊर्जा घेईल परिणामी एक अकार्यक्षम समाधान मिळेल.
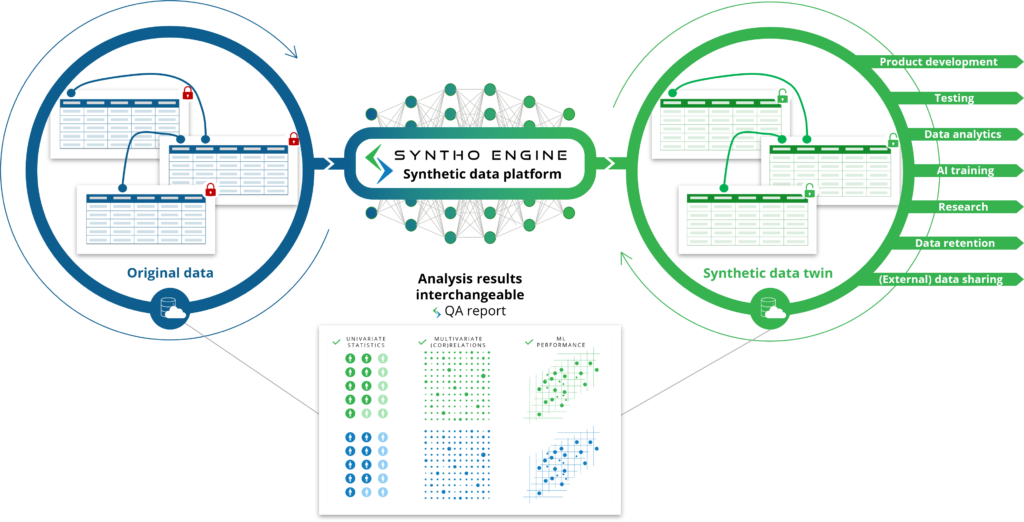
तुम्हाला नावावरून अपेक्षित आहे, कृत्रिम बुद्धिमत्ता (AI) द्वारे व्युत्पन्न केलेला कृत्रिम डेटा हा कृत्रिम बुद्धिमत्ता (AI) अल्गोरिदमद्वारे व्युत्पन्न केलेला सिंथेटिक डेटा आहे. सर्व वैशिष्ट्ये, नातेसंबंध आणि सांख्यिकीय नमुने जाणून घेण्यासाठी AI मॉडेलला मूळ डेटावर प्रशिक्षण दिले जाते. त्यानंतर, हे AI अल्गोरिदम पूर्णपणे नवीन डेटापॉइंट्स तयार करण्यास आणि त्या नवीन डेटापॉइंट्सचे मॉडेल अशा प्रकारे तयार करण्यास सक्षम आहे की ते मूळ डेटासेटमधील वैशिष्ट्ये, नातेसंबंध आणि सांख्यिकीय नमुन्यांची पुनरुत्पादन करते. यालाच आपण सिंथेटिक डेटा ट्विन म्हणतो.
AI मॉडेल सिंथेटिक डेटा ट्विन्स व्युत्पन्न करण्यासाठी मूळ डेटाची नक्कल करते जी मूळ डेटा असल्यास वापरली जाऊ शकते. हे विविध वापर प्रकरणे अनलॉक करते जेथे AI व्युत्पन्न सिंथेटिक डेटा मूळ (संवेदनशील) डेटा वापरण्यासाठी पर्यायी म्हणून वापरला जाऊ शकतो, जसे की चाचणी डेटा, डेमो डेटा किंवा विश्लेषणासाठी AI व्युत्पन्न सिंथेटिक डेटाचा वापर.
नियम-आधारित व्युत्पन्न केलेल्या सिंथेटिक डेटाच्या तुलनेत: तुम्ही संबंधित नियमांचा अभ्यास आणि व्याख्या करण्याऐवजी, AI अल्गोरिदम तुमच्यासाठी हे आपोआप करते. येथे, केवळ वैशिष्ट्ये, नातेसंबंध आणि सांख्यिकीय नमुन्यांचीच कव्हर केली जाईल ज्यांची तुम्हाला माहिती आहे, तर तुम्हाला माहिती नसलेली वैशिष्ट्ये, नातेसंबंध आणि सांख्यिकीय नमुने देखील कव्हर केले जातील.
तुमच्या वापराच्या बाबतीत, डमी डेटा / मॉक डेटा, नियम-आधारित व्युत्पन्न सिंथेटिक डेटा किंवा कृत्रिम बुद्धिमत्ता (AI) द्वारे व्युत्पन्न सिंथेटिक डेटाचे संयोजन सल्ला दिला जातो. हे विहंगावलोकन तुम्हाला कोणत्या प्रकारचा सिंथेटिक डेटा वापरायचा याचे प्रथम संकेत प्रदान करते. सिंथो या सर्वांना सपोर्ट करत असल्याने, तुमचा वापर-प्रकरण आमच्याकडे जाणून घेण्यासाठी आमच्या तज्ञांशी मोकळ्या मनाने संपर्क साधा.
