


सिंथो द्वारे व्युत्पन्न केलेल्या कृत्रिम डेटाचे SAS च्या डेटा तज्ञांद्वारे बाह्य आणि वस्तुनिष्ठ दृष्टिकोनातून मूल्यांकन, प्रमाणीकरण आणि मंजूरी दिली जाते.
जरी सिंथोला त्याच्या वापरकर्त्यांना प्रगत गुणवत्ता हमी अहवाल देण्याचा अभिमान वाटत असला तरी, आम्ही उद्योगातील नेत्यांकडून आमच्या कृत्रिम डेटाचे बाह्य आणि वस्तुनिष्ठ मूल्यमापन करण्याचे महत्त्व देखील समजतो. म्हणूनच आम्ही आमच्या सिंथेटिक डेटाचे मूल्यमापन करण्यासाठी SAS, विश्लेषणातील अग्रेसर, सह सहयोग करतो.
SAS डेटा-अचूकता, गोपनीयता संरक्षण आणि Syntho च्या AI-व्युत्पन्न सिंथेटिक डेटाची मूळ डेटाच्या तुलनेत उपयोगिता यावर विविध सखोल मूल्यमापन करते. निष्कर्षाप्रमाणे, SAS ने मूळ डेटाच्या तुलनेत सिंथोचा सिंथेटिक डेटा अचूक, सुरक्षित आणि वापरण्यायोग्य असल्याचे मूल्यांकन केले आणि मंजूर केले.
आम्ही दूरसंचार डेटा वापरला जो लक्ष्य डेटा म्हणून "मंथन" अंदाजासाठी वापरला जातो. विविध मंथन प्रेडिक्शन मॉडेल्सना प्रशिक्षित करण्यासाठी आणि प्रत्येक मॉडेलच्या कार्यक्षमतेचे मूल्यांकन करण्यासाठी सिंथेटिक डेटा वापरणे हे मूल्यांकनाचे उद्दिष्ट होते. मंथन अंदाज हे वर्गीकरण कार्य असल्याने, SAS ने अंदाज बांधण्यासाठी लोकप्रिय वर्गीकरण मॉडेल निवडले, ज्यात खालील गोष्टींचा समावेश आहे:
सिंथेटिक डेटा व्युत्पन्न करण्यापूर्वी, SAS ने यादृच्छिकपणे टेलिकॉम डेटासेटला ट्रेन सेटमध्ये (मॉडेलच्या प्रशिक्षणासाठी) आणि होल्डआउट सेटमध्ये (मॉडेल स्कोअर करण्यासाठी) विभाजित केले. स्कोअरिंगसाठी स्वतंत्र होल्डआउट सेट केल्याने नवीन डेटावर लागू केल्यावर वर्गीकरण मॉडेल किती चांगले करू शकते याचे निःपक्षपाती मूल्यांकन करण्यास अनुमती देते.
इनपुट म्हणून ट्रेन सेट वापरून, सिंथोने सिंथेटिक डेटासेट तयार करण्यासाठी त्याचे सिंथो इंजिन वापरले. बेंचमार्किंगसाठी, SAS ने एका विशिष्ट थ्रेशोल्डवर (k-अनामितीचे) पोहोचण्यासाठी विविध अनामिकरण तंत्रे लागू केल्यानंतर ट्रेन सेटची एक अनामित आवृत्ती देखील तयार केली. पूर्वीच्या चरणांचा परिणाम चार डेटासेटमध्ये झाला:
प्रत्येक वर्गीकरण मॉडेलला प्रशिक्षित करण्यासाठी डेटासेट 1, 3 आणि 4 वापरले गेले, परिणामी 12 (3 x 4) प्रशिक्षित मॉडेल तयार झाले. SAS ने त्यानंतर ग्राहक मंथनाच्या अंदाजामध्ये प्रत्येक मॉडेलची अचूकता मोजण्यासाठी होल्डआउट डेटासेटचा वापर केला.
SAS डेटा-अचूकता, गोपनीयता संरक्षण आणि Syntho च्या AI-व्युत्पन्न सिंथेटिक डेटाची मूळ डेटाच्या तुलनेत उपयोगिता यावर विविध सखोल मूल्यमापन करते. निष्कर्षाप्रमाणे, SAS ने मूळ डेटाच्या तुलनेत सिंथोचा सिंथेटिक डेटा अचूक, सुरक्षित आणि वापरण्यायोग्य असल्याचे मूल्यांकन केले आणि मंजूर केले.
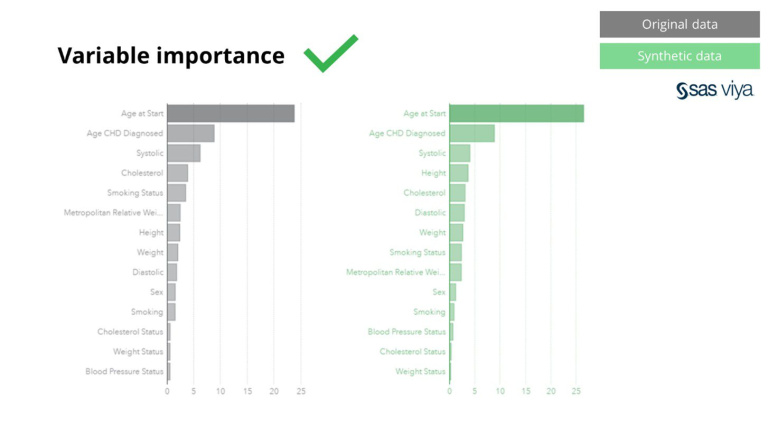
सिंथोमधील सिंथेटिक डेटा केवळ मूलभूत नमुन्यांसाठीच नाही तर प्रगत विश्लेषणात्मक कार्यांसाठी आवश्यक असलेले खोल 'लपलेले' सांख्यिकीय नमुने देखील कॅप्चर करतो. नंतरचे बार चार्टमध्ये प्रदर्शित केले आहे, जे दर्शविते की सिंथेटिक डेटावर प्रशिक्षित मॉडेल्सची अचूकता विरुद्ध मूळ डेटावर प्रशिक्षित मॉडेल समान आहेत. म्हणून, मॉडेल्सच्या वास्तविक प्रशिक्षणासाठी कृत्रिम डेटा वापरला जाऊ शकतो. मूळ डेटाच्या तुलनेत सिंथेटिक डेटावरील अल्गोरिदमद्वारे निवडलेले इनपुट आणि व्हेरिएबल महत्त्व खूप समान होते. म्हणूनच, वास्तविक संवेदनशील डेटा वापरण्यासाठी पर्याय म्हणून मॉडेलिंग प्रक्रिया सिंथेटिक डेटावर केली जाऊ शकते असा निष्कर्ष काढला जातो.
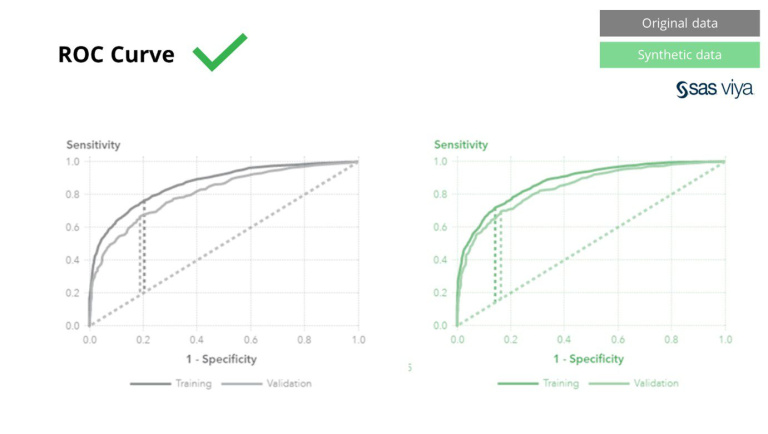
क्लासिक अनामिकरण तंत्रांमध्ये साम्य आहे की ते व्यक्तींचा माग काढण्यात अडथळा आणण्यासाठी मूळ डेटामध्ये फेरफार करतात. ते डेटा हाताळतात आणि त्याद्वारे प्रक्रियेत डेटा नष्ट करतात. तुम्ही जितके जास्त निनावी कराल, तितका तुमचा डेटा अधिक चांगला संरक्षित केला जाईल, परंतु तुमचा डेटा अधिक नष्ट होईल. हे विशेषतः AI आणि मॉडेलिंग कार्यांसाठी विनाशकारी आहे जेथे "अंदाज सांगणारी शक्ती" आवश्यक आहे, कारण खराब गुणवत्तेचा डेटा AI मॉडेलमधून खराब अंतर्दृष्टी देईल. SAS ने हे दाखवून दिले, वक्राखालील क्षेत्र (AUC*) 0.5 च्या जवळ आहे, हे दाखवून दिले की अनामित डेटावर प्रशिक्षित मॉडेल्स सर्वात वाईट कामगिरी करतात.
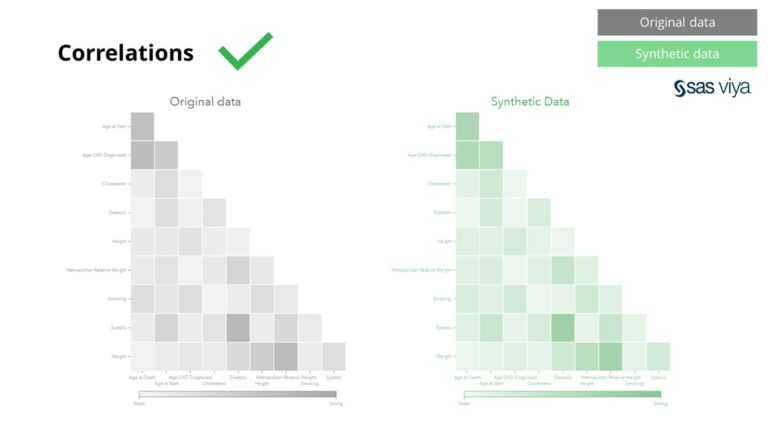
व्हेरिएबल्समधील परस्परसंबंध आणि संबंध सिंथेटिक डेटामध्ये अचूकपणे जतन केले गेले.
वक्र अंतर्गत क्षेत्र (AUC), मॉडेल कामगिरी मोजण्यासाठी एक मेट्रिक, सुसंगत राहिले.
शिवाय, मूळ डेटासेटशी सिंथेटिक डेटाची तुलना करताना व्हेरिएबल महत्त्व, जे मॉडेलमधील व्हेरिएबल्सची पूर्वानुमानित शक्ती दर्शवते, ते अबाधित राहिले.
SAS च्या या निरीक्षणांच्या आधारे आणि SAS Viya वापरून, आम्ही आत्मविश्वासाने असा निष्कर्ष काढू शकतो की सिंथो इंजिनद्वारे व्युत्पन्न केलेला कृत्रिम डेटा गुणवत्तेच्या बाबतीत वास्तविक डेटाच्या बरोबरीचा आहे. हे मॉडेल डेव्हलपमेंटसाठी सिंथेटिक डेटाचा वापर प्रमाणित करते, सिंथेटिक डेटासह प्रगत विश्लेषणासाठी मार्ग मोकळा करते.
