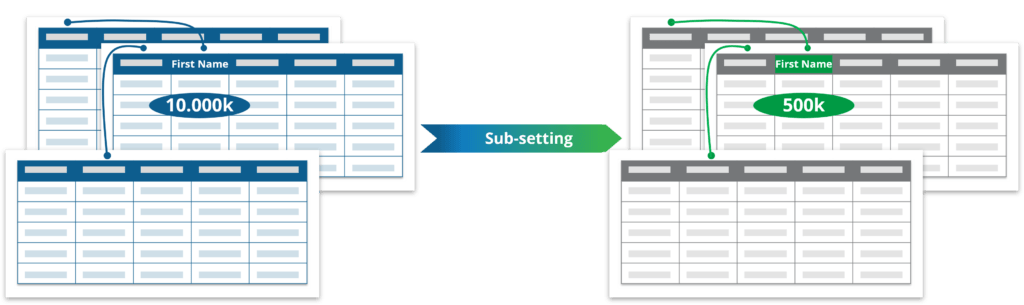

संरक्षित संदर्भीय अखंडतेसह रिलेशनल डेटाबेसचा एक छोटा प्रतिनिधी उपसंच तयार करण्यासाठी रेकॉर्डची संख्या कमी करा
बऱ्याच संस्थांमध्ये मोठ्या प्रमाणात डेटा असलेले उत्पादन वातावरण असते आणि त्यांना उत्पादन नसलेल्या चाचणी वातावरणात मोठ्या प्रमाणात डेटा नको असतो. म्हणून, डेटाबेस सबसेटिंगचा वापर संरक्षित संदर्भात्मक अखंडतेसह मोठ्या रिलेशनल डेटाबेसचा एक छोटा, प्रतिनिधी उपसंच तयार करण्यासाठी केला जातो. संस्था खर्च कमी करण्यासाठी, ते व्यवस्थापित करण्यायोग्य बनवण्यासाठी आणि जलद सेटअप आणि देखभाल करण्यासाठी चाचणी डेटासाठी उप-सेटिंगचा वापर करतात.
अत्यधिक डेटा व्हॉल्यूममुळे उच्च पायाभूत सुविधा आणि गणना खर्च होऊ शकतात, जे उत्पादन नसलेल्या वातावरणात चाचणी डेटासाठी अनावश्यक आहेत. सबसेटिंग क्षमतांसह, तुमचा खर्च कमी करण्यासाठी तुम्ही तुमच्या डेटाचे छोटे उपसंच सहजपणे तयार करू शकता.
गैर-उत्पादन वातावरणात प्रचंड डेटा व्हॉल्यूम व्यवस्थापित करणे परीक्षक आणि विकासकांसाठी आव्हाने आहेत. लहान आणि त्याद्वारे अधिक आटोपशीर चाचणी डेटा, चाचणी आणि विकास प्रक्रिया लक्षणीयरीत्या सुव्यवस्थित करते, शेवटी संपूर्ण चक्र वेळ आणि संसाधनांच्या दृष्टीने अनुकूल करते.
लहान डेटा व्हॉल्यूम जलद आणि अधिक सरळ सेटअप आणि गैर-उत्पादन चाचणी वातावरणाची देखभाल सुलभ करतात. हे विशेषतः जटिल IT लँडस्केपमध्ये संबंधित आहे आणि जेव्हा डेटा स्ट्रक्चर्समध्ये वारंवार बदल होत असतात तेव्हा चाचणी डेटाचे प्रतिनिधीत्व सुनिश्चित करण्यासाठी नियमित अद्यतने आणि रीफ्रेशची आवश्यकता असते.
रेफरेंशियल इंटिग्रिटी ही डेटाबेस मॅनेजमेंटमधील एक संकल्पना आहे जी रिलेशनल डेटाबेसमधील टेबल्समधील सातत्य आणि अचूकता सुनिश्चित करते. रेफरेंशियल इंटिग्रिटी हे सुनिश्चित करेल की “टेबल 1” मधील “व्यक्ती 1” शी संबंधित असलेले प्रत्येक मूल्य “टेबल 1” मधील “व्यक्ती 2” च्या योग्य मूल्याशी आणि इतर कोणत्याही लिंक केलेल्या सारणीशी संबंधित आहे.
नॉन-प्रॉडक्शन वातावरणाचा भाग म्हणून रिलेशनल डेटाबेसमध्ये चाचणी डेटाची विश्वासार्हता राखण्यासाठी संदर्भात्मक अखंडतेची अंमलबजावणी करणे महत्त्वपूर्ण आहे. हे डेटाच्या विसंगतींना प्रतिबंधित करते आणि योग्य चाचणी आणि सॉफ्टवेअर विकासासाठी सारण्यांमधील संबंध अर्थपूर्ण आणि विश्वासार्ह असल्याची खात्री करते.
रिलेशनल डेटाबेस वातावरणात चाचणी डेटा वापरण्यायोग्य होण्यासाठी संदर्भात्मक अखंडता जपली पाहिजे. चाचणी आणि सॉफ्टवेअर डेव्हलपमेंटसाठी वापरल्या जाणाऱ्या गैर-उत्पादन वातावरणात संदर्भात्मक अखंडता राखणे अनेक कारणांसाठी महत्त्वाचे आहे:
सबसेटिंग हे फक्त डेटा हटवण्याइतके सोपे नाही, कारण सर्व डाउनस्ट्रीम आणि अपस्ट्रीमशी संबंधित लिंक केलेल्या टेबल्स रेफरेंशियल अखंडतेचे रक्षण करण्यासाठी प्रमाणानुसार सबसेटिंग करणे आवश्यक आहे. सबसेटिंग हे सुनिश्चित करते की केवळ लक्ष्य सारणीमधील डेटा हटविला जात नाही, तर लक्ष्य सारणीमधून हटविलेल्या डेटाशी संबंधित इतर कोणत्याही लिंक केलेल्या सारणीतील डेटा हटविला जातो. हे सुनिश्चित करते की डेटा हटविण्याचा भाग म्हणून सारण्या, डेटाबेस आणि सिस्टममधील संदर्भात्मक अखंडता जतन केली जाते.
“Table Y” मधून “Person X” काढून डेटा व्हॉल्यूम कमी करणे, "टेबल Y" मधील "व्यक्ती X" शी संबंधित सर्व रेकॉर्ड हटवल्या जाव्यात, परंतु इतर कोणत्याही अपस्ट्रीम किंवा डाउनस्ट्रीम संबंधित सारणी (टेबल A, B, C इ.) मधील "व्यक्ती X" शी संबंधित सर्व रेकॉर्ड देखील हटवल्या पाहिजेत.
“ग्राहक” टेबलमधून “रिचर्ड” काढून डेटा व्हॉल्यूम कमी करणे, "ग्राहक" सारणीतील "रिचर्ड" शी संबंधित सर्व नोंदी हटवल्या पाहिजेत, परंतु इतर कोणत्याही अपस्ट्रीम किंवा डाउनस्ट्रीम संबंधित टेबलमधील "रिचर्ड" शी संबंधित सर्व रेकॉर्ड देखील (पेमेंट टेबल, घटना सारणी, विमा कव्हरेज टेबल इ.) देखील हटवल्या पाहिजेत. हटवले.
सबसेटिंग टेबलवर कार्य करते
सबसेटिंग डेटाबेसमध्ये कार्य करते
सबसेटिंग सिस्टमवर कार्य करते
रिलेशनल डेटाबेस सबसेट करण्यासाठी आणि "लक्ष्य सारणी" वर आधारित सर्व "लिंक केलेले टेबल्स" सबसेट केले आहेत याची खात्री करण्यासाठी तुम्ही सिंथो इंजिन कॉन्फिगर करू शकता.
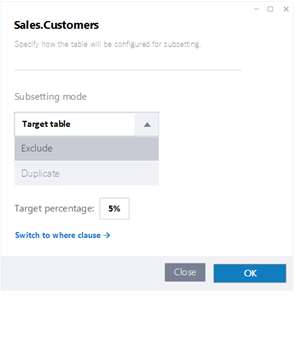
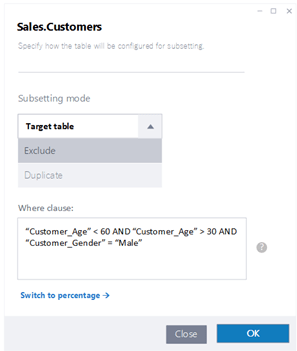
आनुपातिक सबसेटिंग व्यतिरिक्त, जिथे तुम्ही डेटा एक्सट्रॅक्शनसाठी टक्केवारी निर्दिष्ट करता, आमच्या प्रगत क्षमता तुम्हाला सबसेटिंगसाठी लक्ष्य गट अचूकपणे परिभाषित करण्यास अनुमती देतात. उदाहरणार्थ, डेटा काढण्याच्या प्रक्रियेवर अधिक लवचिकता आणि नियंत्रण प्रदान करून, विशिष्ट उपसंच समाविष्ट करण्यासाठी किंवा वगळण्यासाठी तुम्ही निकष निर्दिष्ट करू शकता.
