गोपनीयता संरक्षण अनुपालनासाठी सर्वोत्तम डेटा अनामिकरण साधने
संस्था काढण्यासाठी डेटा अनामिकरण साधने वापरतात वैयक्तिकरित्या ओळखण्यायोग्य माहिती त्यांच्या डेटासेटवरून. पालन न केल्यास नियामक संस्थांकडून मोठा दंड होऊ शकतो आणि डेटा उल्लंघन. विना अनामित डेटा, तुम्ही डेटासेटचा पुरेपूर वापर किंवा शेअर करू शकत नाही.
अनेक अनामिकरण साधने पूर्ण पालनाची हमी देऊ शकत नाही. भूतकाळातील जनन पद्धतींमुळे वैयक्तिक माहिती दुर्भावनापूर्ण अभिनेत्यांद्वारे डी-ओळखण्यासाठी असुरक्षित राहू शकते. काही सांख्यिकीय अनामिकरण पद्धती डेटासेटची गुणवत्ता एका बिंदूपर्यंत कमी करा जेव्हा ती अविश्वसनीय असेल डेटा ticsनालिटिक्स.
आम्ही सिंथो तुम्हाला निनावीकरण पद्धती आणि पास्ट-जेन आणि नेक्स्ट-जेन टूल्समधील मुख्य फरकांची ओळख करून देईल. आम्ही तुम्हाला सर्वोत्तम डेटा निनावी साधनांबद्दल सांगू आणि ते निवडण्यासाठी प्रमुख विचार सुचवू.
अनुक्रमणिका
- सिंथेटिक डेटा म्हणजे काय
- हे कस काम करत
- संस्था का वापरतात
- कसे सुरू करावे

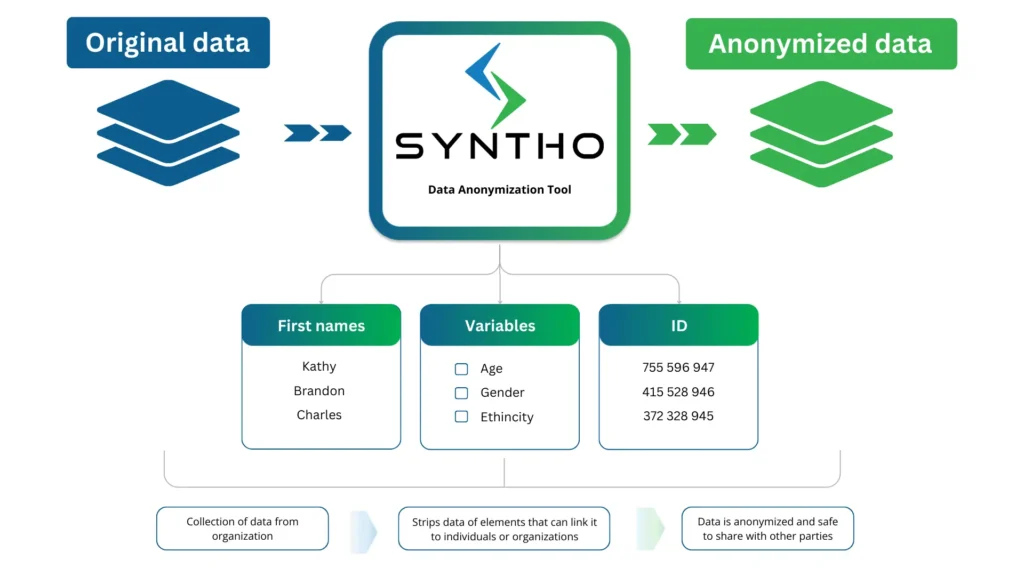
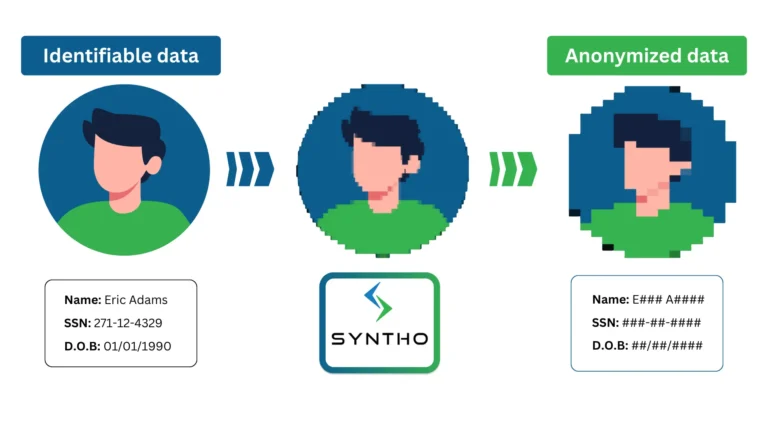
डेटा अनामिकरण साधने काय आहेत?
डेटा अनामिकरण डेटासेटमधील गोपनीय माहिती काढून टाकण्याचे किंवा बदलण्याचे तंत्र आहे. संस्था मुक्तपणे उपलब्ध डेटामध्ये प्रवेश करू शकत नाहीत, सामायिक करू शकत नाहीत आणि त्याचा वापर करू शकत नाहीत जो प्रत्यक्ष किंवा अप्रत्यक्षपणे व्यक्तींना शोधता येतो.
- जनरल डेटा प्रोटेक्शन रेगुलेशन (जीडीपीआर). EU कायदा वैयक्तिक डेटा गोपनीयतेचे संरक्षण करते, डेटा प्रक्रियेसाठी संमती अनिवार्य करते आणि व्यक्तींना डेटा ऍक्सेस अधिकार प्रदान करते. युनायटेड किंगडममध्ये UK-GDPR नावाचा समान कायदा आहे.
- कॅलिफोर्निया ग्राहक गोपनीयता कायदा (CCPA). कॅलिफोर्निया गोपनीयता कायदा संबंधित ग्राहक हक्कांवर लक्ष केंद्रित करते डेटा सामायिकरण.
- आरोग्य विमा पोर्टेबिलिटी आणि अकाउंटेबिलिटी कायदा (HIPAA). गोपनीयता नियम रुग्णाच्या आरोग्य माहितीचे संरक्षण करण्यासाठी मानके स्थापित करते.
डेटा अनामिकरण साधने कशी कार्य करतात?
डेटा अनामिकरण साधने संवेदनशील माहितीसाठी डेटासेट स्कॅन करतात आणि त्यांना कृत्रिम डेटासह बदलतात. सॉफ्टवेअरला असा डेटा टेबल आणि कॉलम, टेक्स्ट फाइल्स आणि स्कॅन केलेल्या कागदपत्रांमध्ये सापडतो.
ही प्रक्रिया घटकांचा डेटा काढून टाकते जे त्यास व्यक्ती किंवा संस्थांशी जोडू शकतात. या साधनांद्वारे अस्पष्ट केलेल्या डेटाच्या प्रकारांमध्ये हे समाविष्ट आहे:
- वैयक्तिकरित्या ओळखण्यायोग्य माहिती (PII): नावे, ओळख क्रमांक, जन्मतारीख, बिलिंग तपशील, फोन नंबर आणि ईमेल पत्ते.
- संरक्षित आरोग्य माहिती (PHI): वैद्यकीय नोंदी, आरोग्य विमा तपशील आणि वैयक्तिक आरोग्य डेटा कव्हर करते.
- आर्थिक माहिती: क्रेडिट कार्ड क्रमांक, बँक खाते तपशील, गुंतवणूक डेटा आणि कॉर्पोरेट संस्थांशी जोडले जाऊ शकणारे इतर.
उदाहरणार्थ, कर्करोग संशोधनासाठी HIPAA अनुपालन सुनिश्चित करण्यासाठी आरोग्य सेवा संस्था रुग्णांचे पत्ते आणि संपर्क तपशील निनावी करतात. एका वित्त कंपनीने GDPR कायद्यांचे पालन करण्यासाठी त्यांच्या डेटासेटमधील व्यवहाराच्या तारखा आणि स्थाने अस्पष्ट केली.
संकल्पना सारखीच असली तरी त्यासाठी अनेक भिन्न तंत्रे अस्तित्वात आहेत अनामित डेटा.
डेटा अनामिकरण तंत्र
अनामिकरण अनेक प्रकारे होते आणि सर्व पद्धती अनुपालन आणि उपयुक्ततेसाठी तितक्याच विश्वासार्ह नसतात. हा विभाग विविध प्रकारच्या पद्धतींमधील फरक वर्णन करतो.
टोपणनाव
छद्मनामकरण ही एक उलट करता येणारी डी-ओडेंटिफिकेशन प्रक्रिया आहे जिथे वैयक्तिक अभिज्ञापक छद्मनावाने बदलले जातात. हे मूळ डेटा आणि बदललेल्या डेटामध्ये मॅपिंग ठेवते, मॅपिंग टेबल स्वतंत्रपणे संग्रहित करते.
छद्मनामकरणाची नकारात्मक बाजू म्हणजे ते उलट करता येण्यासारखे आहे. अतिरिक्त माहितीसह, दुर्भावनापूर्ण अभिनेते ती व्यक्तीकडे परत शोधू शकतात. GDPR च्या नियमांनुसार, छद्म नाव असलेला डेटा अनामित डेटा मानला जात नाही. हे डेटा संरक्षण नियमांच्या अधीन राहते.
डेटा मास्किंग
डेटा मास्किंग पद्धत संवेदनशील माहितीचे संरक्षण करण्यासाठी त्यांच्या डेटाची संरचनात्मकदृष्ट्या समान परंतु बनावट आवृत्ती तयार करते. हे तंत्र सामान्य वापरासाठी समान स्वरूप ठेवून, बदललेल्या वर्णांसह वास्तविक डेटा बदलते. सिद्धांततः, हे डेटासेटची कार्यात्मक कार्यक्षमता राखण्यात मदत करते.
सरावात, मास्किंग डेटा अनेकदा कमी करते डेटा उपयुक्तता. ते जतन करण्यात अयशस्वी होऊ शकते मूळ डेटाचे वितरण किंवा वैशिष्ट्ये, विश्लेषणासाठी ते कमी उपयुक्त बनवतात. आणखी एक आव्हान म्हणजे काय मुखवटा घालायचा हे ठरवणे. चुकीच्या पद्धतीने केले असल्यास, मुखवटा घातलेला डेटा अद्याप पुन्हा ओळखला जाऊ शकतो.
सामान्यीकरण (एकत्रीकरण)
सामान्यीकरण डेटाला कमी तपशीलवार बनवून अनामित करते. हे समान डेटा एकत्रित करते आणि त्याची गुणवत्ता कमी करते, ज्यामुळे डेटाचे वैयक्तिक तुकडे वेगळे सांगणे कठीण होते. या पद्धतीमध्ये अनेकदा वैयक्तिक डेटा पॉइंट्सचे संरक्षण करण्यासाठी सरासरी किंवा एकूण करणे यासारख्या डेटा सारांश पद्धतींचा समावेश होतो.
अति-सामान्यीकरण डेटा जवळजवळ निरुपयोगी बनवू शकतो, तर अंडर-सामान्यीकरण पुरेशी गोपनीयता देऊ शकत नाही. अवशिष्ट प्रकटीकरणाचा धोका देखील आहे, कारण एकत्रित डेटासेट इतरांसह एकत्रित केल्यावर पुरेशी तपशील डी-ओळखणी प्रदान करू शकतात डेटा स्रोत.
उपद्रव
विपर्यास मूल्ये एकत्रित करून आणि यादृच्छिक आवाज जोडून मूळ डेटासेट सुधारित करते. डेटा पॉइंट सूक्ष्मपणे बदलले जातात, एकूण डेटा पॅटर्न राखून त्यांची मूळ स्थिती व्यत्यय आणतात.
गोंधळाची कमतरता म्हणजे डेटा पूर्णपणे अनामित नाही. बदल पुरेसे नसल्यास, मूळ वैशिष्ट्ये पुन्हा ओळखली जाण्याचा धोका असतो.
डेटा स्वॅपिंग
स्वॅपिंग हे एक तंत्र आहे जेथे डेटासेटमधील विशेषता मूल्यांची पुनर्रचना केली जाते. ही पद्धत अंमलात आणणे विशेषतः सोपे आहे. अंतिम डेटासेट मूळ रेकॉर्डशी संबंधित नसतात आणि त्यांच्या मूळ स्त्रोतांशी थेट शोधता येत नाहीत.
अप्रत्यक्षपणे, तथापि, डेटासेट उलट करता येण्यासारखे राहतात. अदलाबदल केलेला डेटा मर्यादित दुय्यम स्त्रोतांसह देखील प्रकट होण्यास असुरक्षित आहे. याशिवाय, काही स्विच केलेल्या डेटाची सिमेंटिक अखंडता राखणे कठीण आहे. उदाहरणार्थ, डेटाबेसमधील नावे बदलताना, सिस्टीम नर आणि मादी नावांमध्ये फरक करण्यात अयशस्वी होऊ शकते.
टोकनियझेशन
टोकनायझेशन संवेदनशील डेटा घटकांना टोकनसह बदलते — शोषणयोग्य मूल्यांशिवाय गैर-संवेदनशील समतुल्य. टोकन केलेली माहिती ही सहसा संख्या आणि वर्णांची एक यादृच्छिक स्ट्रिंग असते. या तंत्राचा उपयोग आर्थिक माहितीचे रक्षण करताना त्याचे कार्यात्मक गुणधर्म राखण्यासाठी केला जातो.
काही सॉफ्टवेअरमुळे टोकन व्हॉल्ट व्यवस्थापित करणे आणि स्केल करणे कठीण होते. ही प्रणाली सुरक्षा जोखीम देखील सादर करते: जर आक्रमणकर्त्याने एन्क्रिप्शन व्हॉल्टमधून प्रवेश केला तर संवेदनशील डेटा धोक्यात येऊ शकतो.
यादृच्छिकता
यादृच्छिक आणि मॉक डेटासह यादृच्छिकीकरण मूल्ये बदलते. हा एक सरळ दृष्टीकोन आहे जो वैयक्तिक डेटा एंट्रीची गोपनीयता टिकवून ठेवण्यास मदत करतो.
जर तुम्हाला अचूक सांख्यिकीय वितरण राखायचे असेल तर हे तंत्र कार्य करत नाही. जिओस्पेशिअल किंवा टेम्पोरल डेटा सारख्या जटिल डेटासेटसाठी वापरल्या जाणाऱ्या डेटाशी तडजोड करण्याची हमी दिली जाते. अपर्याप्त किंवा अयोग्यरित्या लागू केलेल्या यादृच्छिक पद्धती गोपनीयतेचे संरक्षण सुनिश्चित करू शकत नाहीत.
डेटा रिडेक्शन
डेटा रिडेक्शन ही डेटासेटमधून माहिती पूर्णपणे काढून टाकण्याची प्रक्रिया आहे: मजकूर आणि प्रतिमा ब्लॅक आउट करणे, ब्लँक करणे किंवा मिटवणे. हे संवेदनशील प्रवेश प्रतिबंधित करते उत्पादन डेटा आणि कायदेशीर आणि अधिकृत दस्तऐवजांमध्ये ही एक सामान्य प्रथा आहे. हे अगदी स्पष्ट आहे की ते डेटा अचूक सांख्यिकीय विश्लेषणे, मॉडेल शिक्षण आणि क्लिनिकल संशोधनासाठी अयोग्य बनवते.
स्पष्टपणे, या तंत्रांमध्ये त्रुटी आहेत ज्यामुळे दुर्भावनापूर्ण कलाकार गैरवर्तन करू शकतात. ते अनेकदा डेटासेटमधून आवश्यक घटक काढून टाकतात, ज्यामुळे त्यांची उपयोगिता मर्यादित होते. हे शेवटच्या-जनरल तंत्रांच्या बाबतीत नाही.
पुढील पिढीतील अनामिकरण साधने
आधुनिक अनामिकरण सॉफ्टवेअर पुन्हा ओळखण्याचा धोका नाकारण्यासाठी अत्याधुनिक तंत्रांचा वापर करते. ते डेटाची संरचनात्मक गुणवत्ता राखून सर्व गोपनीयता नियमांचे पालन करण्याचे मार्ग ऑफर करतात.
सिंथेटिक डेटा निर्मिती
सिंथेटिक डेटा जनरेशन डेटा युटिलिटी टिकवून ठेवताना डेटा अनामित करण्यासाठी एक स्मार्ट दृष्टीकोन ऑफर करते. हे तंत्र नवीन डेटासेट तयार करण्यासाठी अल्गोरिदम वापरते जे वास्तविक डेटाची रचना आणि गुणधर्म प्रतिबिंबित करते.
सिंथेटिक डेटा PII आणि PHI च्या जागी मॉक डेटा वापरतो जो व्यक्तींना शोधता येत नाही. हे GDPR आणि HIPAA सारख्या डेटा गोपनीयता कायद्यांचे पालन सुनिश्चित करते. सिंथेटिक डेटा जनरेशन टूल्सचा अवलंब करून, संस्था डेटा गोपनीयता सुनिश्चित करतात, डेटा उल्लंघनाचे धोके कमी करतात आणि डेटा-चालित अनुप्रयोगांच्या विकासास गती देतात.
होमोमॉर्फिक एन्क्रिप्शन
होमोमॉर्फिक एन्क्रिप्शन ("समान रचना" म्हणून भाषांतरित) डेटा बदलतो सिफर टेक्स्ट मध्ये. एनक्रिप्टेड डेटासेट मूळ डेटा सारखीच रचना ठेवतात, परिणामी चाचणीसाठी उत्कृष्ट अचूकता येते.
ही पद्धत थेट वर जटिल गणना करण्यास अनुमती देते एनक्रिप्टेड डेटा प्रथम ते डिक्रिप्ट करण्याची गरज न पडता. संस्था सुरक्षिततेशी तडजोड न करता सार्वजनिक क्लाउडमध्ये एनक्रिप्टेड फायली सुरक्षितपणे संचयित करू शकतात आणि तृतीय पक्षांना डेटा प्रोसेसिंग आउटसोर्स करू शकतात. हा डेटा देखील सुसंगत आहे, कारण गोपनीयतेचे नियम एनक्रिप्ट केलेल्या माहितीवर लागू होत नाहीत.
तथापि, जटिल अल्गोरिदमला योग्य अंमलबजावणीसाठी तज्ञांची आवश्यकता असते. याशिवाय, होमोमॉर्फिक एन्क्रिप्शन हे एनक्रिप्टेड डेटावरील ऑपरेशन्सपेक्षा हळू आहे. हे DevOps आणि क्वालिटी ॲश्युरन्स (QA) टीमसाठी इष्टतम उपाय असू शकत नाही, ज्यांना चाचणीसाठी डेटाचा त्वरित प्रवेश आवश्यक आहे.
सुरक्षित बहुपक्षीय गणना
सुरक्षित मल्टीपार्टी कंप्युटेशन (SMPC) ही अनेक सदस्यांच्या संयुक्त प्रयत्नाने डेटासेट तयार करण्याची एक क्रिप्टोग्राफिक पद्धत आहे. प्रत्येक पक्ष त्यांचे इनपुट एन्क्रिप्ट करतो, गणना करतो आणि प्रक्रिया केलेला डेटा मिळवतो. अशा प्रकारे, प्रत्येक सदस्याला त्यांचा स्वतःचा डेटा गुप्त ठेवताना आवश्यक असलेला निकाल मिळतो.
या पद्धतीसाठी अनेक पक्षांना उत्पादित डेटासेट डिक्रिप्ट करणे आवश्यक आहे, जे ते अतिरिक्त गोपनीय बनवते. तथापि, SMPC ला परिणाम निर्माण करण्यासाठी महत्त्वपूर्ण वेळ लागतो.
| मागील पिढीतील डेटा अनामिकरण तंत्र | पुढील पिढीतील अनामिकरण साधने | ||||
|---|---|---|---|---|---|
| टोपणनाव | स्वतंत्र मॅपिंग सारणी राखताना वैयक्तिक अभिज्ञापकांना छद्मनावाने पुनर्स्थित करते. | - एचआर डेटा व्यवस्थापन - ग्राहक समर्थन संवाद - संशोधन सर्वेक्षण | सिंथेटिक डेटा निर्मिती | नवीन डेटासेट तयार करण्यासाठी अल्गोरिदम वापरते जे गोपनीयता आणि अनुपालन सुनिश्चित करताना वास्तविक डेटाच्या संरचनेचे प्रतिबिंबित करते. | - डेटा-चालित अनुप्रयोग विकास - क्लिनिकल संशोधन - प्रगत मॉडेलिंग - ग्राहक विपणन |
| डेटा मास्किंग | तेच स्वरूप ठेवून, बनावट वर्णांसह वास्तविक डेटा बदलते. | - आर्थिक अहवाल - वापरकर्ता प्रशिक्षण वातावरण | होमोमॉर्फिक एन्क्रिप्शन | मूळ रचना टिकवून ठेवताना डेटाचे सिफरटेक्स्टमध्ये रूपांतर करते, कूटबद्ध डेटावर डिक्रिप्शनशिवाय गणना करण्यास अनुमती देते. | - सुरक्षित डेटा प्रोसेसिंग - डेटा गणना आउटसोर्सिंग - प्रगत डेटा विश्लेषण |
| सामान्यीकरण (एकत्रीकरण) | डेटा तपशील कमी करते, समान डेटा गटबद्ध करते. | - लोकसंख्याशास्त्रीय अभ्यास - बाजार अभ्यास | सुरक्षित बहुपक्षीय गणना | क्रिप्टोग्राफिक पद्धत जिथे एकाधिक पक्ष त्यांचे इनपुट एन्क्रिप्ट करतात, गणना करतात आणि संयुक्त परिणाम प्राप्त करतात. | - सहयोगी डेटा विश्लेषण - गोपनीय डेटा पूलिंग |
| उपद्रव | मूल्ये गोलाकार करून आणि यादृच्छिक आवाज जोडून डेटासेट सुधारित करते. | - आर्थिक डेटा विश्लेषण - वाहतूक नमुना संशोधन - विक्री डेटा विश्लेषण | |||
| डेटा स्वॅपिंग | थेट शोधता येण्यापासून रोखण्यासाठी डेटासेट विशेषता मूल्यांची पुनर्रचना करते. | - वाहतूक अभ्यास - शैक्षणिक डेटा विश्लेषण | |||
| टोकनियझेशन | संवेदनशील डेटाला गैर-संवेदनशील टोकनसह बदलते. | - पेमेंट प्रक्रिया - ग्राहक संबंध संशोधन | |||
| यादृच्छिकता | मूल्ये बदलण्यासाठी यादृच्छिक किंवा नकली डेटा जोडते. | - भौगोलिक डेटा विश्लेषण - वर्तणूक अभ्यास | |||
| डेटा रिडेक्शन | डेटासेटमधून माहिती काढून टाकते, | - कायदेशीर दस्तऐवज प्रक्रिया - रेकॉर्ड व्यवस्थापन | |||
सारणी 1. मागील- आणि पुढील-पिढीच्या निनावी तंत्रांमधील तुलना
डेटा अनामिकरणासाठी एक नवीन दृष्टीकोन म्हणून स्मार्ट डेटा डी-आयडेंटिफिकेशन
स्मार्ट डी-आयडेंटिफिकेशन AI-व्युत्पन्न वापरून डेटा अनामित करते सिंथेटिक मॉक डेटा. वैशिष्ट्यांसह प्लॅटफॉर्म संवेदनशील माहितीचे खालील प्रकारे अनुपालन, ओळखता न येणाऱ्या डेटामध्ये रूपांतरित करतात:
- डी-आयडेंटिफिकेशन सॉफ्टवेअर विद्यमान डेटासेटचे विश्लेषण करते आणि PII आणि PHI ओळखते.
- कृत्रिम माहितीसह कोणता संवेदनशील डेटा बदलायचा हे संस्था निवडू शकतात.
- हे टूल अनुरूप डेटासह नवीन डेटासेट तयार करते.
जेव्हा संस्थांना मौल्यवान डेटा सुरक्षितपणे सहयोग करणे आणि देवाणघेवाण करणे आवश्यक असते तेव्हा हे तंत्रज्ञान उपयुक्त आहे. जेव्हा डेटा अनेकांमध्ये सुसंगत करणे आवश्यक असते तेव्हा हे देखील उपयुक्त आहे रिलेशनल डेटाबेस.
स्मार्ट डी-आयडेंटिफिकेशन सातत्यपूर्ण मॅपिंगद्वारे डेटामधील संबंध अबाधित ठेवते. कंपन्या सखोल व्यवसाय विश्लेषण, मशीन लर्निंग प्रशिक्षण आणि क्लिनिकल चाचण्यांसाठी व्युत्पन्न केलेला डेटा वापरू शकतात.
बऱ्याच पद्धतींसह, निनावी साधन तुमच्यासाठी योग्य आहे की नाही हे निर्धारित करण्यासाठी तुम्हाला एक मार्ग आवश्यक आहे.
योग्य डेटा अनामिकरण साधन कसे निवडावे
- ऑपरेशनल स्केलेबिलिटी. तुमच्या ऑपरेशनल मागणीनुसार वर आणि खाली स्केलिंग करण्यास सक्षम असलेले साधन निवडा. वाढीव वर्कलोड अंतर्गत ऑपरेशनल कार्यक्षमतेची चाचणी घेण्यासाठी ताण द्या.
- एकत्रीकरण. डेटा अनामिकरण साधने आपल्या विद्यमान प्रणाली आणि विश्लेषणात्मक सॉफ्टवेअर तसेच सतत एकत्रीकरण आणि सतत उपयोजन (CI/CD) पाइपलाइनसह सहजतेने एकत्रित केली पाहिजेत. तुमच्या डेटा स्टोरेज, एनक्रिप्शन आणि प्रोसेसिंग प्लॅटफॉर्मसह सुसंगतता अखंड ऑपरेशनसाठी अत्यावश्यक आहे.
- सातत्यपूर्ण डेटा मॅपिंग. अनामित डेटा प्रिझर्व्हर्समध्ये अखंडता आणि सांख्यिकीय अचूकता आहे जी तुमच्या गरजांसाठी योग्य आहे याची खात्री करा. मागील पिढीतील अनामिकरण तंत्रे डेटासेटमधून मौल्यवान घटक मिटवतात. आधुनिक साधने, तथापि, संदर्भात्मक अखंडता राखतात, प्रगत वापर प्रकरणांसाठी डेटा पुरेसा अचूक बनवतात.
- सुरक्षा यंत्रणा. अंतर्गत आणि बाह्य धोक्यांपासून वास्तविक डेटासेट आणि अनामित परिणामांचे संरक्षण करणाऱ्या साधनांना प्राधान्य द्या. सॉफ्टवेअर सुरक्षित ग्राहक पायाभूत सुविधा, भूमिका-आधारित प्रवेश नियंत्रणे आणि द्वि-घटक प्रमाणीकरण API मध्ये तैनात केले जाणे आवश्यक आहे.
- अनुरूप पायाभूत सुविधा. GDPR, HIPAA आणि CCPA नियमांचे पालन करणारे साधन डेटासेट सुरक्षित स्टोरेजमध्ये संग्रहित करते याची खात्री करा. याव्यतिरिक्त, अनपेक्षित त्रुटींमुळे डाउनटाइमची शक्यता टाळण्यासाठी डेटा बॅकअप आणि पुनर्प्राप्ती साधनांचे समर्थन केले पाहिजे.
- पेमेंट मॉडेल. साधन तुमच्या बजेटशी जुळते की नाही हे समजून घेण्यासाठी तात्काळ आणि दीर्घकालीन खर्चाचा विचार करा. काही साधने मोठ्या उद्योगांसाठी आणि मध्यम आकाराच्या व्यवसायांसाठी डिझाइन केलेली आहेत, तर इतरांमध्ये लवचिक मॉडेल आणि वापर-आधारित योजना आहेत.
- तांत्रिक आधार. ग्राहक आणि तांत्रिक समर्थनाची गुणवत्ता आणि उपलब्धता यांचे मूल्यांकन करा. प्रदाता तुम्हाला डेटा अनामिकरण साधने एकत्रित करण्यात, कर्मचाऱ्यांना प्रशिक्षण देण्यासाठी आणि तांत्रिक समस्यांचे निराकरण करण्यात मदत करू शकतो.
7 सर्वोत्तम डेटा अनामिकरण साधने
आता तुम्हाला माहित आहे की काय शोधायचे आहे, आम्हाला सर्वात विश्वासार्ह साधने काय मानतात ते एक्सप्लोर करूया संवेदनशील माहिती मुखवटा.
1. सिंथो
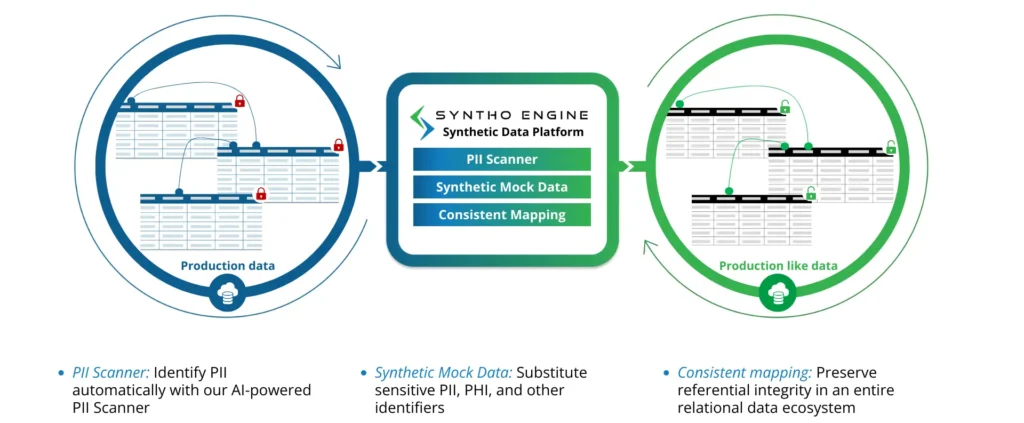
सिंथो सिंथेटिक डेटा जनरेशन सॉफ्टवेअरद्वारे समर्थित आहे जे स्मार्ट डी-आयडेंटिफिकेशनसाठी संधी प्रदान करते. प्लॅटफॉर्मचे नियम-आधारित डेटा निर्मिती बहुमुखीपणा आणते, संस्थांना त्यांच्या गरजेनुसार डेटा तयार करण्यास सक्षम करते.
एक AI-चालित स्कॅनर डेटासेट, सिस्टम आणि प्लॅटफॉर्मवर सर्व PII आणि PHI ओळखते. नियामक मानकांचे पालन करण्यासाठी कोणता डेटा काढायचा किंवा उपहास करायचा हे संस्था निवडू शकतात. दरम्यान, सबसेटिंग वैशिष्ट्य चाचणीसाठी लहान डेटासेट बनविण्यात मदत करते, स्टोरेज आणि प्रक्रिया संसाधनावरील भार कमी करते.
हे प्लॅटफॉर्म आरोग्यसेवा, पुरवठा साखळी व्यवस्थापन आणि वित्त यासह विविध क्षेत्रांमध्ये उपयुक्त आहे. संस्था नॉन-प्रॉडक्शन तयार करण्यासाठी आणि सानुकूल चाचणी परिस्थिती विकसित करण्यासाठी सिंथो प्लॅटफॉर्म वापरतात.
तुम्ही सिंथोच्या क्षमतांबद्दल अधिक जाणून घेऊ शकता डेमो शेड्यूल करत आहे.
2. K2 view
3. ब्रॉडकॉम
4. मुख्यतः AI
5. ARX
6. स्मृतिभ्रंश
7. टॉनिक.एआय
डेटा अनामिकरण साधने केसेस वापरतात
वित्त, आरोग्यसेवा, जाहिराती आणि सार्वजनिक सेवा मधील कंपन्या डेटा गोपनीयता कायद्यांचे पालन करण्यासाठी निनावी साधने वापरतात. डी-ओळखलेले डेटासेट विविध परिस्थितींसाठी वापरले जातात.
सॉफ्टवेअर विकास आणि चाचणी
अनामिकरण साधने सॉफ्टवेअर अभियंते, परीक्षक आणि QA व्यावसायिकांना PII उघड न करता वास्तववादी डेटासेटसह कार्य करण्यास सक्षम करतात. प्रगत साधने संघांना आवश्यक डेटाची स्वयं-तरतुदी करण्यात मदत करतात जे अनुपालन समस्यांशिवाय वास्तविक-जागतिक चाचणी परिस्थितीची नक्कल करतात. हे संस्थांना त्यांची सॉफ्टवेअर विकास कार्यक्षमता आणि सॉफ्टवेअर गुणवत्ता सुधारण्यास मदत करते.
वास्तविक प्रकरणे:
- सिंथोच्या सॉफ्टवेअरने अनामित चाचणी डेटा तयार केला जे वास्तविक डेटाच्या सांख्यिकीय मूल्यांचे जतन करते, विकासकांना अधिक वेगाने भिन्न परिस्थिती वापरून पाहण्यास सक्षम करते.
- Google चे BigQuery वेअरहाऊस डेटासेट अनामिकरण वैशिष्ट्य ऑफर करते गोपनीयतेचे नियम न मोडता पुरवठादारांसोबत डेटा शेअर करण्यात संस्थांना मदत करण्यासाठी.
क्लिनिकल संशोधन
वैद्यकीय संशोधक, विशेषत: फार्मास्युटिकल उद्योगातील, त्यांच्या अभ्यासासाठी गोपनीयता राखण्यासाठी डेटा अनामित करतात. संशोधक रूग्णांच्या गोपनीयतेला धोका न देता वैद्यकीय प्रगतीमध्ये योगदान देऊन ट्रेंड, रुग्ण लोकसंख्याशास्त्र आणि उपचार परिणामांचे विश्लेषण करू शकतात.
वास्तविक प्रकरणे:
- इरास्मस मेडिकल सेंटर सिंथोची अनामित AI-जनरेशन टूल्स वापरते वैद्यकीय संशोधनासाठी उच्च-गुणवत्तेचा डेटासेट तयार करणे आणि सामायिक करणे.
फसवणूक प्रतिबंध
फसवणूक प्रतिबंधामध्ये, निनावी साधने व्यवहार डेटाचे सुरक्षित विश्लेषण करण्यास, दुर्भावनायुक्त नमुने ओळखण्याची परवानगी देतात. डी-आयडेंटिफिकेशन टूल्स फसवणूक आणि जोखीम शोधणे सुधारण्यासाठी वास्तविक डेटावर एआय सॉफ्टवेअरला प्रशिक्षण देण्याची परवानगी देतात.
वास्तविक प्रकरणे:
- Brighterion मास्टरकार्डच्या अनामित व्यवहार डेटावर प्रशिक्षित आहे त्याचे AI मॉडेल समृद्ध करण्यासाठी, खोट्या सकारात्मक गोष्टी कमी करताना फसवणूक शोध दर सुधारणे.
ग्राहक विपणन
डेटा अनामिकरण तंत्र ग्राहकांच्या प्राधान्यांचे मूल्यांकन करण्यात मदत करतात. लक्ष्यित विपणन धोरणे परिष्कृत करण्यासाठी आणि वापरकर्ता अनुभव वैयक्तिकृत करण्यासाठी संस्था त्यांच्या व्यावसायिक भागीदारांसह डी-ओळखलेले वर्तन डेटासेट सामायिक करतात.
वास्तविक प्रकरणे:
- सिंथोच्या डेटा अनामिकरण प्लॅटफॉर्मने सिंथेटिक डेटा वापरून ग्राहक मंथनाचा अचूक अंदाज लावला 56,000 स्तंभांसह 128 पेक्षा जास्त ग्राहकांच्या डेटासेटमधून व्युत्पन्न केले.
सार्वजनिक डेटा प्रकाशन
एजन्सी आणि सरकारी संस्था विविध सार्वजनिक उपक्रमांसाठी पारदर्शकपणे सार्वजनिक माहिती सामायिक करण्यासाठी आणि त्यावर प्रक्रिया करण्यासाठी डेटा अनामिकरण वापरतात. त्यामध्ये सोशल नेटवर्क्स आणि गुन्हेगारी नोंदी, लोकसंख्याशास्त्र आणि सार्वजनिक वाहतूक मार्गांवर आधारित शहरी नियोजन किंवा रोगाच्या नमुन्यांवर आधारित प्रदेशांमधील आरोग्यसेवा गरजांवर आधारित गुन्ह्यांचे अंदाज समाविष्ट आहेत.
वास्तविक प्रकरणे:
- इंडियाना युनिव्हर्सिटीने सुमारे 10,000 पोलिस अधिकाऱ्यांचा निनावी स्मार्टफोन डेटा वापरला 21 यूएस शहरांमध्ये सामाजिक-आर्थिक घटकांवर आधारित अतिपरिचित गस्ती विसंगती उघड करण्यासाठी.
आम्ही निवडलेली ही काही उदाहरणे आहेत. द अनामिकरण सॉफ्टवेअर उपलब्ध डेटाचा जास्तीत जास्त वापर करण्याचे साधन म्हणून सर्व उद्योगांमध्ये वापरले जाते.
सर्वोत्तम डेटा अनामिकरण साधने निवडा
सर्व कंपन्या वापरतात डेटाबेस अनामिकरण सॉफ्टवेअर गोपनीयता नियमांचे पालन करण्यासाठी. जेव्हा वैयक्तिक माहिती काढून टाकली जाते, तेव्हा दंड किंवा नोकरशाही प्रक्रियेच्या जोखमीशिवाय डेटासेट वापरला आणि सामायिक केला जाऊ शकतो.
डेटा स्वॅपिंग, मास्किंग आणि रिडेक्शन यासारख्या जुन्या अनामिकरण पद्धती पुरेशा सुरक्षित नाहीत. डेटा डी-आयडेंटिफिकेशन एक शक्यता राहते, ज्यामुळे ते गैर-अनुपालक किंवा धोकादायक बनते. याव्यतिरिक्त, मागील-जनरल अनामिक सॉफ्टवेअर अनेकदा डेटाची गुणवत्ता खालावते, विशेषतः मध्ये मोठा डेटासेट. प्रगत विश्लेषणासाठी संस्था अशा डेटावर अवलंबून राहू शकत नाहीत.
आपण ची निवड करावी सर्वोत्तम डेटा अनामिकरण सॉफ्टवेअर. अनेक व्यवसाय सिंथो प्लॅटफॉर्म त्याच्या उच्च दर्जाच्या PII ओळख, मुखवटा आणि कृत्रिम डेटा निर्मिती क्षमतांसाठी निवडतात.
तुम्हाला अधिक जाणून घेण्यात स्वारस्य आहे का? आमचे उत्पादन दस्तऐवजीकरण किंवा एक्सप्लोर करण्यास मोकळ्या मनाने प्रात्यक्षिकासाठी आमच्याशी संपर्क साधा.
लेखक बद्दल

व्यवसाय विकास व्यवस्थापक
उलियाना क्रेनस्का, सॉफ्टवेअर डेव्हलपमेंट आणि SaaS उद्योगातील आंतरराष्ट्रीय अनुभवासह सिंथो येथील व्यवसाय विकास कार्यकारी, VU ॲमस्टरडॅम येथून डिजिटल व्यवसाय आणि नवोपक्रमात पदव्युत्तर पदवी प्राप्त केली आहे.
गेल्या पाच वर्षांत, उलियानाने AI क्षमतांचा शोध घेण्यासाठी आणि AI प्रकल्पाच्या अंमलबजावणीसाठी धोरणात्मक व्यवसाय सल्लामसलत प्रदान करण्यासाठी दृढ वचनबद्धता दर्शविली आहे.

तुमचा सिंथेटिक डेटा मार्गदर्शक आता जतन करा!
- कृत्रिम डेटा म्हणजे काय?
- संस्था का वापरतात?
- सिंथेटिक डेटा क्लायंट केसेसचे मूल्य जोडणे
- कसे सुरू करावे
