एआयचा न दिसणारा अपराधी: पूर्वाग्रह उलगडणे
बायस ब्लॉग मालिका: भाग १
परिचय
आपल्या बुद्धिमत्तेच्या वाढत्या कृत्रिम स्वरूपाच्या जगात, क्लिष्ट निर्णय घेण्याचे काम सोपवलेल्या मशीन्स अधिकाधिक प्रचलित होत आहेत. व्यवसाय, उच्च-स्टेक निर्णय घेणे आणि वैद्यकीय क्षेत्रात गेल्या काही वर्षांमध्ये AI चा वापर दर्शवणारे साहित्याचा एक मोठा भाग आहे. या वाढत्या प्रसारामुळे, तथापि, लोकांनी त्या प्रणालींमधील प्रवृत्तींबद्दल लक्षात घेतले आहे; म्हणजेच, डेटामधील नमुन्यांचे पूर्णपणे अनुसरण करण्यासाठी मूळतः डिझाइन केलेले असताना, त्यांनी पूर्वग्रहाची चिन्हे दर्शविली आहेत, या अर्थाने विविध लिंगवादी आणि भेदभावपूर्ण वर्तन पाहिले जाऊ शकते. अलीकडील युरोपियन एआय कायदा, अशा पूर्वग्रहाच्या प्रकरणाचा ऐवजी विस्तृतपणे कव्हर करते आणि त्याच्याशी संबंधित समस्या हाताळण्यासाठी एक पाया सेट करते.
तांत्रिक दस्तऐवजीकरणाच्या अनेक वर्षांमध्ये, काही लोकसंख्याशास्त्राप्रती या विकृत वर्तनाचे वर्णन करण्यासाठी लोक "बायस" हा शब्द वापरतात; एक शब्द ज्याचा अर्थ बदलतो, गोंधळ निर्माण करतो आणि त्यास संबोधित करण्याचे कार्य गुंतागुंतीत करतो.
हा लेख पक्षपाती विषयावर आधारित ब्लॉग पोस्टच्या मालिकेतील पहिला आहे. या मालिकेत, आम्ही तुम्हाला AI मध्ये पक्षपातीपणाची स्पष्ट, पचनीय समज देण्याचे उद्दिष्ट ठेवू. आम्ही पूर्वाग्रह मोजण्याचे आणि कमी करण्याचे मार्ग सादर करू आणि या मार्गातील सिंथेटिक डेटाची भूमिका अधिक न्याय्य प्रणालींमध्ये एक्सप्लोर करू. सिंथेटिक डेटा जनरेशनमधील आघाडीची खेळाडू, सिंथो या प्रयत्नात कसे योगदान देऊ शकते हे देखील आम्ही तुम्हाला पाहू. त्यामुळे, तुम्ही कृती करण्यायोग्य अंतर्दृष्टी शोधणारे व्यवसायी असाल किंवा या विषयाबद्दल फक्त उत्सुक असाल, तुम्ही योग्य ठिकाणी आहात.
बायस इन अॅक्शन: एक वास्तविक-जागतिक उदाहरण
तुम्ही कदाचित विचार करत असाल, "एआय मधील हा पूर्वाग्रह सर्व महत्त्वाचा आहे, परंतु माझ्यासाठी, सामान्य लोकांसाठी याचा काय अर्थ आहे?" सत्य हे आहे की, प्रभाव दूरगामी आहे, अनेकदा अदृश्य पण शक्तिशाली आहे. एआय मधील बायस ही केवळ शैक्षणिक संकल्पना नाही; ही एक वास्तविक-जगातील समस्या आहे ज्याचे गंभीर परिणाम आहेत.
डच बाल कल्याण घोटाळ्याचे उदाहरण घ्या. स्वयंचलित प्रणाली, किमान मानवी हस्तक्षेपासह निष्पक्ष आणि कार्यक्षम परिणाम निर्माण करण्यासाठी तयार करण्यात आलेले साधन, पक्षपाती होते. सदोष डेटा आणि गृहितकांवर आधारित फसवणुकीसाठी याने हजारो पालकांना चुकीच्या पद्धतीने ध्वजांकित केले. निकाल? एआय सिस्टीममधील पक्षपातीपणामुळे कुटूंब गोंधळात पडले, वैयक्तिक प्रतिष्ठा खराब झाली आणि आर्थिक अडचणी. ही अशी उदाहरणे आहेत जी AI मधील पक्षपात दूर करण्याची निकड हायलाइट करतात.

स्रोत: "2030 ड्युरेनसाठी नुकसान भरपाई द्या”, 2023. NOS
पण तिथेच थांबू नका. ही घटना पूर्वाग्रहाने कहर करणारी एक वेगळी घटना नाही. AI मधील पक्षपाताचा प्रभाव आपल्या जीवनाच्या सर्व कोपऱ्यांवर पसरतो. नोकरीसाठी कोणाला नियुक्त केले जाते, कोणाला कर्ज मंजूर केले जाते, कोणाला कोणत्या प्रकारचे वैद्यकीय उपचार मिळतात - पक्षपाती AI प्रणाली विद्यमान असमानता कायम ठेवू शकतात आणि नवीन तयार करू शकतात.
याचा विचार करा: पक्षपाती ऐतिहासिक डेटावर प्रशिक्षित एआय प्रणाली योग्य उमेदवारांना त्यांच्या लिंग किंवा जातीमुळे नोकरी नाकारू शकते. किंवा पक्षपाती AI प्रणाली एखाद्या पात्र उमेदवाराला त्यांच्या पोस्टकोडमुळे कर्ज नाकारू शकते. ही केवळ काल्पनिक परिस्थिती नाहीत; ते सध्या घडत आहेत.
विशिष्ट प्रकारचे पूर्वाग्रह, जसे की ऐतिहासिक पूर्वाग्रह आणि मापन पूर्वाग्रह, अशा सदोष निर्णयांना कारणीभूत ठरतात. ते डेटामध्ये अंतर्भूत आहेत, सामाजिक पूर्वाग्रहांमध्ये खोलवर रुजलेले आहेत आणि विविध लोकसंख्याशास्त्रीय गटांमधील असमान परिणामांमध्ये प्रतिबिंबित होतात. ते भविष्यसूचक मॉडेल्सचे निर्णय तिरस्कार करू शकतात आणि परिणामी अयोग्य वागणूक देऊ शकतात.
गोष्टींच्या भव्य योजनेत, AI मधील पक्षपात एक मूक प्रभावशाली म्हणून काम करू शकतो, सूक्ष्मपणे आपल्या समाजाला आणि आपल्या जीवनाला आकार देऊ शकतो, अनेकदा आपल्या लक्षातही येत नाही. हे सर्व उपरोक्त मुद्दे तुम्हाला प्रश्न पडू शकतात की ते थांबवण्यासाठी कृती का केली गेली नाहीत आणि ते शक्य आहे का.
खरंच, नवीन तांत्रिक प्रगतीमुळे अशा समस्येचा सामना करणे अधिकाधिक सुलभ होत आहे. तथापि, या समस्येचे निराकरण करण्याची पहिली पायरी म्हणजे त्याचे अस्तित्व आणि प्रभाव समजून घेणे आणि मान्य करणे. आत्तासाठी, त्याच्या अस्तित्वाची पोचपावती तयार केली गेली आहे, "समजून घेण्याची" बाब अजूनही अस्पष्ट आहे.
बायस समजून घेणे
द्वारे सादर केल्याप्रमाणे पूर्वाग्रहाची मूळ व्याख्या केंब्रिज शब्दकोश शब्दाच्या मुख्य उद्देशापासून खूप दूर जात नाही कारण ते AI शी संबंधित आहे, या एकवचनी व्याख्येचे अनेक भिन्न अर्थ लावले जातील. वर्गीकरण, जसे की संशोधकांनी सादर केलेले Hellström et al (2020) आणि क्लीगर (२०२१), पूर्वाग्रहाच्या व्याख्येमध्ये सखोल अंतर्दृष्टी प्रदान करा. या पेपर्सवर एक साधी नजर टाकल्यास हे दिसून येईल की, या समस्येचे प्रभावीपणे निराकरण करण्यासाठी या शब्दाच्या व्याख्येची मोठी संकुचितता आवश्यक आहे.
घटना बदलत असताना, पूर्वाग्रहाचा अर्थ चांगल्या प्रकारे परिभाषित करण्यासाठी आणि व्यक्त करण्यासाठी, एखादी व्यक्ती विरुद्धची अधिक चांगली व्याख्या करू शकते, ती म्हणजे निष्पक्षता.
निष्पक्षतेची व्याख्या
जसे की विविध अलीकडील साहित्यात परिभाषित केल्याप्रमाणे Castelnovo et al. (२०२२)संभाव्य जागा या शब्दाची समज दिल्यावर निष्पक्षता स्पष्ट केली जाऊ शकते. जसे ते अस्तित्वात आहे, संभाव्य जागा (PS) एखाद्या विशिष्ट लोकसंख्याशास्त्रीय गटाशी संबंधित असले तरीही एखाद्या व्यक्तीच्या क्षमता आणि ज्ञानाच्या व्याप्तीचा संदर्भ देते. PS च्या संकल्पनेची ही व्याख्या दिल्यास, समान PS च्या दोन व्यक्तींमधील वागणुकीची समानता म्हणून कोणीही सहजतेने परिभाषित करू शकतो, बायस इंडिकिंग पॅरामीटर्समध्ये (जसे की वंश, वय किंवा लिंग) त्यांचे निरीक्षण करण्यायोग्य आणि लपलेले फरक विचारात न घेता. या व्याख्येतील कोणतेही विचलन, ज्याला संधींची समानता देखील म्हटले जाते, हे पूर्वाग्रह आणि पुढील तपासाच्या योग्यतेचे स्पष्ट संकेत आहे.
वाचकांमधील अभ्यासकांच्या लक्षात येईल की येथे परिभाषित केल्याप्रमाणे काहीतरी साध्य करणे आपल्या जगात अस्तित्वात असलेल्या अंतर्निहित पूर्वाग्रहांमुळे पूर्णपणे अशक्य आहे. ते सत्य आहे! या जगातील घटनांमधून गोळा केलेल्या सर्व डेटासह आपण ज्या जगात राहतो, ते बरेच ऐतिहासिक आणि सांख्यिकीय पूर्वाग्रहांच्या अधीन आहे. हे, खरंच, अशा "पक्षपाती" डेटावर प्रशिक्षित भविष्यसूचक मॉडेल्सवरील पूर्वाग्रहांचे परिणाम पूर्णपणे कमी करण्याचा आत्मविश्वास कमी करते. तथापि, विविध पद्धतींचा वापर करून, पक्षपाताचे परिणाम कमी करण्याचा प्रयत्न केला जाऊ शकतो. असे असताना, या उर्वरित ब्लॉग पोस्टमध्ये वापरल्या जाणार्या शब्दावली पूर्वाग्रहाचा प्रभाव पूर्णपणे कमी करण्याऐवजी कमी करण्याच्या कल्पनेकडे वळेल.
ठीक आहे! तर आता पक्षपात म्हणजे काय आणि त्याच्या अस्तित्वाचे संभाव्य मूल्यांकन कसे करता येईल याची कल्पना पुढे आणली गेली आहे; तथापि, जर आपल्याला समस्येचा योग्य प्रकारे सामना करायचा असेल तर, आपल्याला हे माहित असणे आवश्यक आहे की हे सर्व पूर्वाग्रह कोठून उद्भवतात.
स्रोत आणि प्रकार समजून घेणे
विद्यमान संशोधन मशीन लर्निंगमधील विविध प्रकारच्या पूर्वाग्रहांबद्दल मौल्यवान अंतर्दृष्टी प्रदान करते. म्हणून मेहराबी इ. al (२०१९) मशीन लर्निंगमधील पूर्वाग्रहांची विभागणी केली आहे, कोणीही पक्षपातांना 3 प्रमुख श्रेणींमध्ये विभागू शकतो. बहुदा ते:
- डेटा टू अल्गोरिदम: डेटामधूनच उद्भवणारे पूर्वाग्रह समाविष्ट करणारी एक श्रेणी. हे खराब डेटा संकलन, जगात अस्तित्वात असलेल्या अंतर्निहित पूर्वाग्रह इत्यादींमुळे होऊ शकते.
- अल्गोरिदम ते वापरकर्ता: अल्गोरिदमच्या डिझाइन आणि कार्यक्षमतेपासून उद्भवलेल्या पूर्वाग्रहांवर लक्ष केंद्रित करणारी श्रेणी. अल्गोरिदम इतरांपेक्षा विशिष्ट डेटा पॉइंट्सचे कसे अर्थ लावू शकतात, वजन करू शकतात किंवा विचारात घेऊ शकतात, ज्यामुळे पक्षपाती परिणाम होऊ शकतात.
- वापरकर्ता डेटा: सिस्टमसह वापरकर्त्याच्या परस्परसंवादामुळे उद्भवलेल्या पूर्वाग्रहांशी संबंधित आहे. वापरकर्ते ज्या पद्धतीने डेटा इनपुट करतात, त्यांचे अंतर्निहित पूर्वाग्रह किंवा अगदी सिस्टम आउटपुटवर त्यांचा विश्वास परिणामांवर प्रभाव टाकू शकतो.
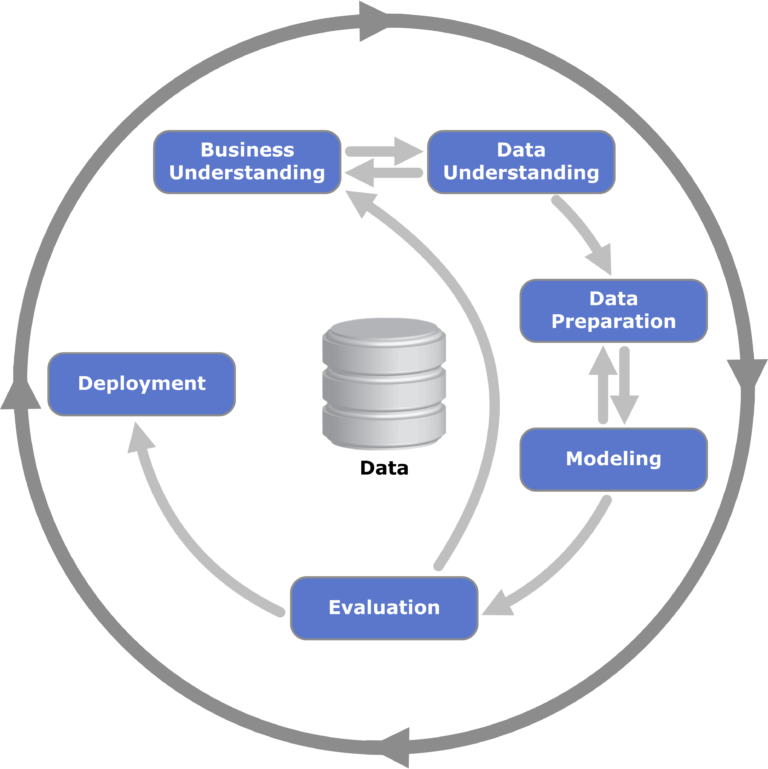
आकृती 1: डेटा मायनिंगसाठी CRISP-DM फ्रेमवर्कचे व्हिज्युअलायझेशन; डेटा मायनिंगमध्ये सामान्यतः वापरले जाते आणि पूर्वाग्रह अस्तित्वात येऊ शकतात अशा अवस्था ओळखण्याच्या प्रक्रियेशी संबंधित.
जरी नावे पूर्वाग्रहाच्या स्वरूपाचे सूचक आहेत, तरीही एखाद्याला या छत्रीच्या अटींखाली वर्गीकृत केलेल्या पूर्वाग्रहांच्या प्रकारांबद्दल प्रश्न असू शकतात. आमच्या वाचकांमधील उत्साही लोकांसाठी, आम्ही या शब्दावली आणि वर्गीकरणाशी संबंधित काही साहित्याच्या लिंक दिल्या आहेत. या ब्लॉग पोस्टमध्ये साधेपणासाठी, आम्ही परिस्थितीशी संबंधित काही निवडक पूर्वाग्रह कव्हर करू (जे जवळजवळ सर्व अल्गोरिदम श्रेणीतील डेटाचे आहेत). विशिष्ट प्रकारचे पूर्वाग्रह खालीलप्रमाणे आहेत:
- ऐतिहासिक पूर्वाग्रह: विविध सामाजिक गटांमध्ये आणि सर्वसाधारणपणे समाजामध्ये अस्तित्वात असलेल्या नैसर्गिक पूर्वाग्रहांमुळे डेटामध्ये अंतर्निहित पूर्वाग्रहाचा एक प्रकार. जगातील या डेटाच्या अंतर्भावामुळेच सॅम्पलिंग आणि वैशिष्ट्य निवडीच्या विविध माध्यमांद्वारे तो कमी केला जाऊ शकत नाही.
- मापन पूर्वाग्रह आणि प्रतिनिधित्व पूर्वाग्रह: जेव्हा डेटासेटच्या भिन्न उपसमूहांमध्ये असमान प्रमाणात "अनुकूल" परिणाम असतात तेव्हा हे दोन जवळून संबंधित पूर्वाग्रह उद्भवतात. या प्रकारचा पूर्वाग्रह त्यामुळे भविष्यसूचक मॉडेल्सच्या परिणामांवर परिणाम करू शकतो
- अल्गोरिदमिक बायस: बायस पूर्णपणे वापरात असलेल्या अल्गोरिदमशी संबंधित आहे. चाललेल्या चाचण्यांमध्ये देखील आढळून आल्याप्रमाणे (पुढील पोस्टमध्ये तपशीलवार वर्णन केले आहे), या प्रकारच्या पूर्वाग्रहाचा दिलेल्या अल्गोरिदमच्या निष्पक्षतेवर जबरदस्त परिणाम होऊ शकतो.
मशीन लर्निंगमधील पूर्वाग्रहाच्या या मूलभूत समजांचा उपयोग नंतरच्या पोस्टमध्ये अधिक प्रभावीपणे समस्येचा सामना करण्यासाठी केला जाईल.
अंतिम विचार
आर्टिफिशियल इंटेलिजन्समधील पूर्वाग्रहाच्या या अन्वेषणामध्ये, आम्ही आमच्या वाढत्या AI-चालित जगामध्ये त्याचे सखोल परिणाम स्पष्ट केले आहेत. डच बाल कल्याण घोटाळ्यासारख्या वास्तविक-जगातील उदाहरणांपासून ते पूर्वाग्रह श्रेणी आणि प्रकारांच्या गुंतागुंतीच्या बारकाव्यांपर्यंत, हे स्पष्ट आहे की पूर्वाग्रह ओळखणे आणि समजून घेणे हे सर्वोपरि आहे.
पूर्वाग्रहांमुळे निर्माण झालेली आव्हाने - मग ती ऐतिहासिक असोत, अल्गोरिदमिक असोत किंवा वापरकर्ता-प्रेरित असोत - महत्त्वाची असतात, परंतु ती अजिंक्य नाहीत. पूर्वाग्रहाची उत्पत्ती आणि अभिव्यक्ती यावर दृढ आकलन करून, आम्ही त्यांना संबोधित करण्यासाठी अधिक सुसज्ज आहोत. तथापि, ओळख आणि समजून घेणे हे फक्त प्रारंभिक बिंदू आहेत.
जसजसे आम्ही या मालिकेत पुढे जात आहोत, तसतसे आमचे पुढील लक्ष आमच्याकडे असलेल्या मूर्त साधने आणि फ्रेमवर्कवर असेल. एआय मॉडेल्समधील पक्षपाताची व्याप्ती आम्ही कशी मोजू? आणि सर्वात महत्त्वाचे म्हणजे, आपण त्याचा प्रभाव कसा कमी करू शकतो? हे महत्त्वाचे प्रश्न आहेत ज्यांचा आम्ही पुढे शोध घेणार आहोत, याची खात्री करून की AI विकसित होत राहते, ते योग्य आणि कार्यक्षम अशा दिशेने करते.

डेटा सिंथेटिक आहे, परंतु आमचा कार्यसंघ वास्तविक आहे!
सिंथोशी संपर्क साधा आणि सिंथेटिक डेटाचे मूल्य एक्सप्लोर करण्यासाठी आमचा एक विशेषज्ञ प्रकाशाच्या वेगाने तुमच्याशी संपर्क साधेल!