AI-व्युत्पन्न सिंथेटिक डेटा, उच्च गुणवत्तेच्या डेटामध्ये सहज आणि जलद प्रवेश?
एआयने सराव मध्ये कृत्रिम डेटा व्युत्पन्न केला
सिंथो, AI-व्युत्पन्न सिंथेटिक डेटामधील तज्ञ, वळण्याचे उद्दिष्ट ठेवते privacy by design AI-व्युत्पन्न सिंथेटिक डेटासह स्पर्धात्मक फायद्यासाठी. उच्च गुणवत्तेच्या डेटामध्ये सहज आणि जलद प्रवेशासह मजबूत डेटा फाउंडेशन तयार करण्यात ते संस्थांना मदत करतात आणि अलीकडेच फिलिप्स इनोव्हेशन अवॉर्ड जिंकतात.
तथापि, AI सह सिंथेटिक डेटा निर्मिती हा तुलनेने नवीन उपाय आहे जो सामान्यत: वारंवार विचारले जाणारे प्रश्न सादर करतो. याला उत्तर देण्यासाठी, सिंथोने SAS, Advanced Analytics आणि AI सॉफ्टवेअरमधील मार्केट लीडरसह केस-स्टडी सुरू केली.
डच एआय कोलिशन (NL AIC) च्या सहकार्याने, त्यांनी डेटा गुणवत्ता, कायदेशीर वैधता आणि उपयोगिता यावर विविध मूल्यांकनांद्वारे सिंथो इंजिनद्वारे व्युत्पन्न केलेल्या AI-व्युत्पन्न सिंथेटिक डेटाची मूळ डेटाशी तुलना करून सिंथेटिक डेटाच्या मूल्याची तपासणी केली.
डेटा अनामिकरण हा उपाय नाही का?
क्लासिक अनामिकरण तंत्रांमध्ये साम्य आहे की ते व्यक्तींचा माग काढण्यात अडथळा आणण्यासाठी मूळ डेटामध्ये फेरफार करतात. उदाहरणे म्हणजे सामान्यीकरण, दडपशाही, पुसणे, छद्मनामकरण, डेटा मास्किंग आणि पंक्ती आणि स्तंभांचे शफलिंग. आपण खालील सारणीमध्ये उदाहरणे शोधू शकता.
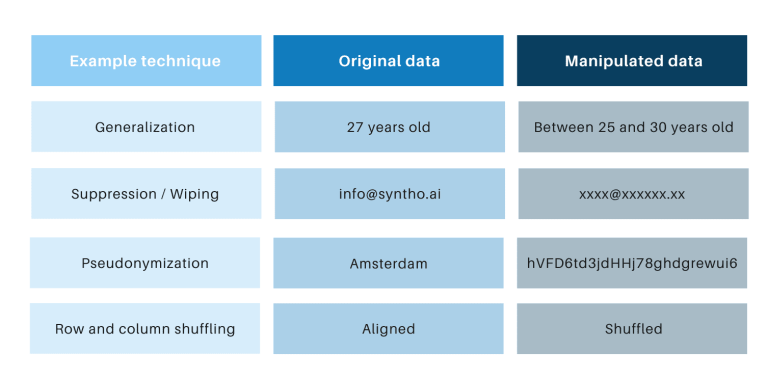
ती तंत्रे 3 प्रमुख आव्हाने सादर करतात:
- ते प्रति डेटा प्रकार आणि प्रत्येक डेटासेट वेगळ्या पद्धतीने कार्य करतात, ज्यामुळे त्यांना स्केल करणे कठीण होते. शिवाय, ते वेगळ्या पद्धतीने कार्य करत असल्याने, कोणत्या पद्धती लागू करायच्या आणि कोणत्या तंत्रांचे संयोजन आवश्यक आहे याबद्दल नेहमीच वादविवाद होईल.
- मूळ डेटाशी नेहमीच वन-टू-वन संबंध असतो. याचा अर्थ असा की गोपनीयतेचा धोका नेहमीच असेल, विशेषत: सर्व खुल्या डेटासेटमुळे आणि त्या डेटासेटशी लिंक करण्यासाठी उपलब्ध तंत्रांमुळे.
- ते डेटा हाताळतात आणि त्याद्वारे प्रक्रियेत डेटा नष्ट करतात. हे विशेषत: AI कार्यांसाठी विनाशकारी आहे जिथे "अंदाज सांगणारी शक्ती" आवश्यक आहे, कारण खराब गुणवत्तेचा डेटा AI मॉडेलमधून खराब अंतर्दृष्टी देईल (गार्बेज-इन परिणामी कचरा बाहेर येईल).
या केस स्टडीद्वारे देखील या मुद्द्यांचे मूल्यांकन केले जाते.
केस स्टडीचा परिचय
केस स्टडीसाठी, लक्ष्य डेटासेट हा SAS द्वारे प्रदान केलेला टेलिकॉम डेटासेट होता ज्यामध्ये 56.600 ग्राहकांचा डेटा होता. डेटासेटमध्ये 128 स्तंभ आहेत, ज्यामध्ये ग्राहकाने कंपनी सोडली आहे की नाही हे दर्शविणारा एक स्तंभ समाविष्ट आहे (म्हणजे 'मंथन') किंवा नाही. केस स्टडीचे उद्दिष्ट काही मॉडेल्सना ग्राहकांच्या मंथनाचा अंदाज घेण्यासाठी आणि त्या प्रशिक्षित मॉडेल्सच्या कार्यक्षमतेचे मूल्यांकन करण्यासाठी प्रशिक्षित करण्यासाठी कृत्रिम डेटा वापरणे हे होते. मंथन भविष्यवाणी हे वर्गीकरण कार्य असल्याने, SAS ने अंदाज बांधण्यासाठी चार लोकप्रिय वर्गीकरण मॉडेल निवडले, ज्यात खालील गोष्टींचा समावेश आहे:
- यादृच्छिक वन
- ग्रेडियंट बूस्टिंग
- लॉजिस्टिक प्रतिगमन
- मज्जासंस्थेसंबंधीचा नेटवर्क
सिंथेटिक डेटा व्युत्पन्न करण्यापूर्वी, SAS ने यादृच्छिकपणे टेलिकॉम डेटासेटला ट्रेन सेटमध्ये (मॉडेलच्या प्रशिक्षणासाठी) आणि होल्डआउट सेटमध्ये (मॉडेल स्कोअर करण्यासाठी) विभाजित केले. स्कोअरिंगसाठी स्वतंत्र होल्डआउट सेट केल्याने नवीन डेटावर लागू केल्यावर वर्गीकरण मॉडेल किती चांगले कार्य करू शकते याचे निःपक्षपाती मूल्यांकन करण्यास अनुमती देते.
इनपुट म्हणून ट्रेन सेट वापरून, सिंथोने सिंथेटिक डेटासेट तयार करण्यासाठी त्याचे सिंथो इंजिन वापरले. बेंचमार्किंगसाठी, SAS ने विशिष्ट थ्रेशोल्ड (के-अॅनोनिमिटी) पर्यंत पोहोचण्यासाठी विविध अनामिकरण तंत्रे लागू केल्यानंतर ट्रेन सेटची बदली आवृत्ती देखील तयार केली. पूर्वीच्या चरणांचा परिणाम चार डेटासेटमध्ये झाला:
- ट्रेन डेटासेट (म्हणजे मूळ डेटासेट वजा होल्डआउट डेटासेट)
- होल्डआउट डेटासेट (म्हणजे मूळ डेटासेटचा उपसंच)
- अनामित डेटासेट (ट्रेन डेटासेटवर आधारित)
- सिंथेटिक डेटासेट (ट्रेन डेटासेटवर आधारित)
प्रत्येक वर्गीकरण मॉडेलला प्रशिक्षित करण्यासाठी डेटासेट 1, 3 आणि 4 वापरले गेले, परिणामी 12 (3 x 4) प्रशिक्षित मॉडेल तयार झाले. SAS ने नंतर होल्डआउट डेटासेटचा वापर केला ज्याने प्रत्येक मॉडेल ग्राहक मंथनाचा अंदाज लावते त्या अचूकतेचे मोजमाप केले. काही मूलभूत आकडेवारीसह प्रारंभ करून, परिणाम खाली सादर केले आहेत.
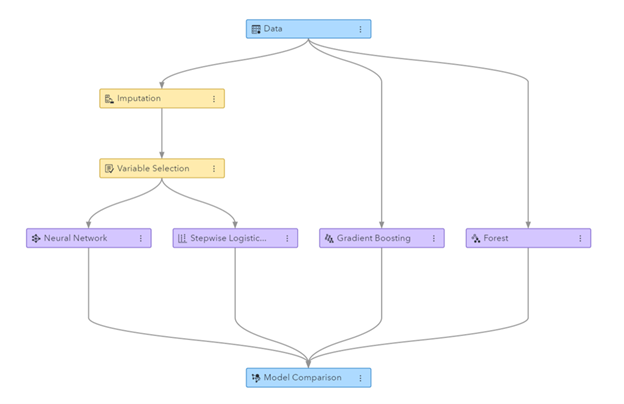
आकृती: एसएएस व्हिज्युअल डेटा मायनिंग आणि मशीन लर्निंगमध्ये मशीन लर्निंग पाइपलाइन व्युत्पन्न झाली
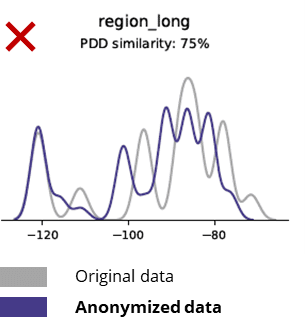
अनामित डेटाची मूळ डेटाशी तुलना करताना मूलभूत आकडेवारी
अनामिकरण तंत्र अगदी मूलभूत नमुने, व्यवसाय तर्कशास्त्र, नातेसंबंध आणि आकडेवारी (खालील उदाहरणाप्रमाणे) नष्ट करतात. मूलभूत विश्लेषणासाठी अनामित डेटा वापरणे अशा प्रकारे अविश्वसनीय परिणाम देते. खरेतर, निनावी डेटाच्या खराब गुणवत्तेमुळे प्रगत विश्लेषण कार्यांसाठी (उदा. AI/ML मॉडेलिंग आणि डॅशबोर्डिंग) वापरणे जवळजवळ अशक्य झाले आहे.
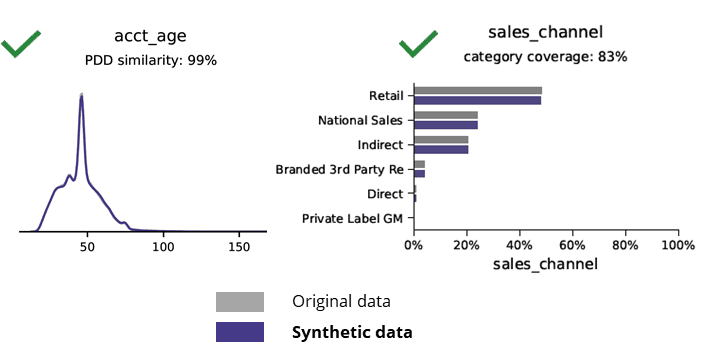
मूळ डेटाशी सिंथेटिक डेटाची तुलना करताना मूलभूत आकडेवारी
AI सह सिंथेटिक डेटा जनरेशन मूलभूत नमुने, व्यवसाय तर्कशास्त्र, नातेसंबंध आणि आकडेवारी (खालील उदाहरणाप्रमाणे) संरक्षित करते. मूलभूत विश्लेषणासाठी सिंथेटिक डेटा वापरणे अशा प्रकारे विश्वसनीय परिणाम देते. मुख्य प्रश्न, सिंथेटिक डेटा प्रगत विश्लेषण कार्यांसाठी (उदा. AI/ML मॉडेलिंग आणि डॅशबोर्डिंग) ठेवतो का?
AI-व्युत्पन्न सिंथेटिक डेटा आणि प्रगत विश्लेषणे
सिंथेटिक डेटा केवळ मूलभूत नमुन्यांसाठीच नाही (पूर्वीच्या प्लॉटमध्ये दर्शविल्याप्रमाणे), तो प्रगत विश्लेषणात्मक कार्यांसाठी आवश्यक असलेले खोल 'लपलेले' सांख्यिकीय नमुने देखील कॅप्चर करतो. नंतरचे खालील बार चार्टमध्ये दाखवले आहे, हे दर्शविते की सिंथेटिक डेटावर प्रशिक्षित मॉडेल्सची अचूकता विरुद्ध मूळ डेटावर प्रशिक्षित मॉडेल्स समान आहेत. शिवाय, वक्राखालील क्षेत्र (AUC*) 0.5 च्या जवळ असताना, अनामित डेटावर प्रशिक्षित मॉडेल्स सर्वात वाईट कामगिरी करतात. मूळ डेटाच्या तुलनेत सिंथेटिक डेटावरील सर्व प्रगत विश्लेषणात्मक मूल्यांकनांसह संपूर्ण अहवाल विनंतीवर उपलब्ध आहे.
*AUC: वक्र अंतर्गत क्षेत्र हे प्रगत विश्लेषण मॉडेल्सच्या अचूकतेसाठी एक मोजमाप आहे, खरे सकारात्मक, खोटे सकारात्मक, खोटे नकारात्मक आणि खरे नकारात्मक विचारात घेऊन. 0,5 म्हणजे मॉडेल यादृच्छिकपणे अंदाज लावतात आणि त्यात कोणतीही भविष्यसूचक शक्ती नसते आणि 1 याचा अर्थ असा की मॉडेल नेहमी बरोबर असते आणि त्यात पूर्ण भविष्यवाणी करण्याची शक्ती असते.
याव्यतिरिक्त, या कृत्रिम डेटाचा वापर डेटा वैशिष्ट्ये आणि मॉडेलच्या वास्तविक प्रशिक्षणासाठी आवश्यक असलेले मुख्य चल समजून घेण्यासाठी केला जाऊ शकतो. मूळ डेटाच्या तुलनेत सिंथेटिक डेटावरील अल्गोरिदमद्वारे निवडलेले इनपुट खूप समान होते. म्हणून, मॉडेलिंग प्रक्रिया या कृत्रिम आवृत्तीवर केली जाऊ शकते, ज्यामुळे डेटा उल्लंघनाचा धोका कमी होतो. तथापि, वैयक्तिक रेकॉर्डचा अंदाज लावताना (उदा. टेल्को ग्राहक) मूळ डेटावर पुन्हा प्रशिक्षण देण्याची शिफारस स्पष्टता, वाढीव स्वीकृती किंवा केवळ नियमनासाठी केली जाते.
पद्धतीनुसार गटबद्ध अल्गोरिदम द्वारे AUC
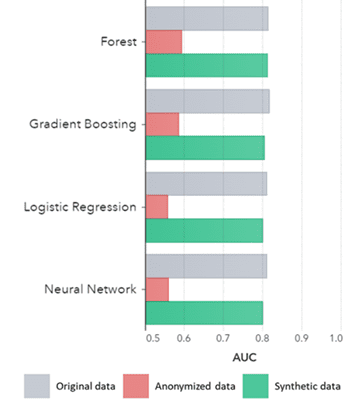
निष्कर्ष:
- मूळ डेटावर प्रशिक्षित मॉडेलच्या तुलनेत सिंथेटिक डेटावर प्रशिक्षित मॉडेल्स अत्यंत समान कामगिरी दर्शवतात
- 'क्लासिक अनामिकरण तंत्र' सह अनामित डेटावर प्रशिक्षित केलेले मॉडेल मूळ डेटा किंवा सिंथेटिक डेटावर प्रशिक्षित मॉडेलच्या तुलनेत निकृष्ट कामगिरी दाखवतात
- सिंथेटिक डेटा तयार करणे सोपे आणि जलद आहे कारण तंत्र प्रत्येक डेटासेट आणि प्रत्येक डेटा प्रकारात सारखेच कार्य करते.
मूल्यवर्धित सिंथेटिक डेटा वापर प्रकरणे
केस 1 वापरा: मॉडेल डेव्हलपमेंट आणि प्रगत विश्लेषणासाठी सिंथेटिक डेटा
मॉडेल्स (उदा. डॅशबोर्ड [BI] आणि प्रगत विश्लेषण [AI आणि ML]) विकसित करण्यासाठी वापरण्यायोग्य, उच्च दर्जाच्या डेटामध्ये सुलभ आणि जलद प्रवेशासह मजबूत डेटा पाया असणे आवश्यक आहे. तथापि, अनेक संस्थांना सबऑप्टिमल डेटा फाउंडेशनचा त्रास होतो ज्यामुळे 3 प्रमुख आव्हाने येतात:
- (गोपनीयता) नियम, अंतर्गत प्रक्रिया किंवा डेटा सायलोमुळे डेटामध्ये प्रवेश मिळवण्यासाठी अनेक वर्षे लागतात
- क्लासिक अनामिकरण तंत्र डेटा नष्ट करतात, ज्यामुळे डेटा यापुढे विश्लेषणासाठी आणि प्रगत विश्लेषणासाठी योग्य राहणार नाही (कचरा मध्ये = कचरा बाहेर)
- विद्यमान सोल्यूशन्स स्केलेबल नाहीत कारण ते प्रत्येक डेटासेट आणि डेटा प्रकारानुसार वेगळ्या पद्धतीने कार्य करतात आणि मोठ्या मल्टी-टेबल डेटाबेस हाताळू शकत नाहीत
सिंथेटिक डेटा दृष्टीकोन: यासाठी-चांगला-वास्तविक सिंथेटिक डेटा असलेले मॉडेल विकसित करा:
- तुमच्या विकासकांना अडथळा न आणता मूळ डेटाचा वापर कमी करा
- वैयक्तिक डेटा अनलॉक करा आणि पूर्वी प्रतिबंधित असलेल्या अधिक डेटामध्ये प्रवेश करा (उदा. गोपनीयतेमुळे)
- संबंधित डेटामध्ये सुलभ आणि जलद डेटा प्रवेश
- स्केलेबल सोल्यूशन जे प्रत्येक डेटासेट, डेटाटाइप आणि मोठ्या डेटाबेससाठी समान कार्य करते
हे संस्थेला डेटा अनलॉक करण्यासाठी आणि डेटा संधींचा लाभ घेण्यासाठी वापरण्यायोग्य, उच्च दर्जाच्या डेटामध्ये सुलभ आणि जलद प्रवेशासह मजबूत डेटा पाया तयार करण्यास अनुमती देते.
केस 2 वापरा: सॉफ्टवेअर चाचणी, विकास आणि वितरणासाठी स्मार्ट सिंथेटिक चाचणी डेटा
अत्याधुनिक सॉफ्टवेअर सोल्यूशन्स वितरीत करण्यासाठी उच्च दर्जाच्या चाचणी डेटासह चाचणी आणि विकास आवश्यक आहे. मूळ उत्पादन डेटा वापरणे स्पष्ट दिसते, परंतु (गोपनीयता) नियमांमुळे परवानगी नाही. पर्यायी Test Data Management (TDM) साधने सादर करतात "legacy-by-design"चाचणी डेटा बरोबर मिळवण्यासाठी:
- उत्पादन डेटा प्रतिबिंबित करू नका आणि व्यवसाय तर्क आणि संदर्भ अखंडता जतन केली जात नाही
- संथ आणि वेळ घेणारे काम करा
- हाताने काम करणे आवश्यक आहे
सिंथेटिक डेटा दृष्टिकोन: अत्याधुनिक सॉफ्टवेअर सोल्यूशन्स स्मार्ट वितरीत करण्यासाठी AI-व्युत्पन्न सिंथेटिक चाचणी डेटासह चाचणी करा आणि विकसित करा:
- संरक्षित व्यवसाय तर्क आणि संदर्भ अखंडतेसह उत्पादनासारखा डेटा
- अत्याधुनिक AI सह सुलभ आणि जलद डेटा निर्मिती
- गोपनीयतेनुसार डिझाइन
- सोपे, जलद आणि agile
हे संस्थेला अत्याधुनिक सॉफ्टवेअर सोल्यूशन्स वितरीत करण्यासाठी पुढील-स्तरीय चाचणी डेटासह चाचणी आणि विकसित करण्यास अनुमती देते!
अधिक माहिती
स्वारस्य आहे? सिंथेटिक डेटाबद्दल अधिक माहितीसाठी, सिंथो वेबसाइटला भेट द्या किंवा Wim Kees Janssen शी संपर्क साधा. SAS बद्दल अधिक माहितीसाठी, भेट द्या www.sas.com किंवा kees@syntho.ai वर संपर्क साधा.
या वापराच्या बाबतीत, अपेक्षित परिणाम साध्य करण्यासाठी Syntho, SAS आणि NL AIC एकत्र काम करतात. Syntho AI-व्युत्पन्न केलेल्या सिंथेटिक डेटामध्ये तज्ञ आहे आणि SAS विश्लेषणामध्ये मार्केट लीडर आहे आणि डेटा एक्सप्लोर, विश्लेषण आणि व्हिज्युअलाइज करण्यासाठी सॉफ्टवेअर ऑफर करते.
* 2021 ची भविष्यवाणी करते - गव्हर्न, स्केल आणि ट्रान्सफॉर्म डिजिटल बिझनेस, गार्टनर, 2020 साठी डेटा आणि विश्लेषण धोरणे.

तुमचा सिंथेटिक डेटा मार्गदर्शक आता जतन करा!
- कृत्रिम डेटा म्हणजे काय?
- संस्था का वापरतात?
- सिंथेटिक डेटा क्लायंट केसेसचे मूल्य जोडणे
- कसे सुरू करावे
