ओळख कोण? नावे काढून टाकणे हा पर्याय का नाही याची 5 उदाहरणे



ओळख कोण? जरी मला खात्री आहे की आपल्यापैकी बहुतेकांना हा खेळ पूर्वीपासून माहित असेल, येथे एक संक्षिप्त पुनरावृत्ती आहे. खेळाचे ध्येय: 'होय' आणि 'नाही' प्रश्न विचारून तुमच्या प्रतिस्पर्ध्याने निवडलेल्या व्यंगचित्र पात्राचे नाव शोधा, जसे 'व्यक्ती टोपी घालते का?' किंवा 'व्यक्ती चष्मा घालते का'? खेळाडू प्रतिस्पर्ध्याच्या प्रतिसादाच्या आधारे उमेदवार काढून टाकतात आणि त्यांच्या प्रतिस्पर्ध्याच्या गूढ चारित्र्याशी संबंधित गुणधर्म शिकतात. पहिला खेळाडू जो इतर खेळाडूचे रहस्य वर्ण ओळखतो तो गेम जिंकतो.
कळले तुला. केवळ संबंधित गुणधर्मांमध्ये प्रवेश करून एखाद्या व्यक्तीला डेटासेटमधून ओळखणे आवश्यक आहे. खरं तर, आम्ही नियमितपणे गेस हू ही संकल्पना पाहतो जो प्रत्यक्ष व्यवहारात लागू होतो, परंतु नंतर वास्तविक लोकांचे गुणधर्म असलेल्या पंक्ती आणि स्तंभांसह स्वरूपित डेटासेटवर कार्यरत असतो. डेटासह काम करताना मुख्य फरक असा आहे की लोक फक्त काही गुणधर्मांमध्ये प्रवेश करून सहज व्यक्तींना सहजपणे कमी करू शकतात.
गेस हू गेम दाखवल्याप्रमाणे, एखादी व्यक्ती फक्त काही गुणधर्मांमध्ये प्रवेश करून व्यक्ती ओळखू शकते. हे आपल्या डेटासेट मधून फक्त 'नावे' (किंवा इतर थेट अभिज्ञापक) काढून टाकणे हे अनामिकरण तंत्र म्हणून का अपयशी ठरते याचे एक साधे उदाहरण म्हणून काम करते. या ब्लॉगमध्ये, डेटा अनामितीकरणाचे साधन म्हणून स्तंभ काढून टाकण्याशी संबंधित गोपनीयता धोक्यांविषयी आपल्याला माहिती देण्यासाठी आम्ही चार व्यावहारिक प्रकरणे प्रदान करतो.
नावे काढण्याची पद्धत म्हणून केवळ नावे काढून टाकणे (यापुढे) कार्य करत नाही हे सर्वात महत्त्वाचे कारण आहे. लिंकेज अटॅकसह, हल्लेखोर मूळ डेटा इतर सुलभ डेटा स्त्रोतांशी जोडतो जेणेकरून एखाद्या व्यक्तीची विशिष्ट ओळख पटते आणि या व्यक्तीबद्दल (अनेकदा संवेदनशील) माहिती जाणून घेतली जाते.
मुख्य गोष्ट म्हणजे इतर डेटा संसाधनांची उपलब्धता जे सध्या उपस्थित आहेत, किंवा भविष्यात उपस्थित होऊ शकतात. स्वतःचा विचार करा. फेसबुक, इन्स्टाग्राम किंवा लिंक्डइनवर तुमचा स्वतःचा किती वैयक्तिक डेटा आढळू शकतो ज्याचा लिंक अॅटॅकसाठी गैरवापर होऊ शकतो?
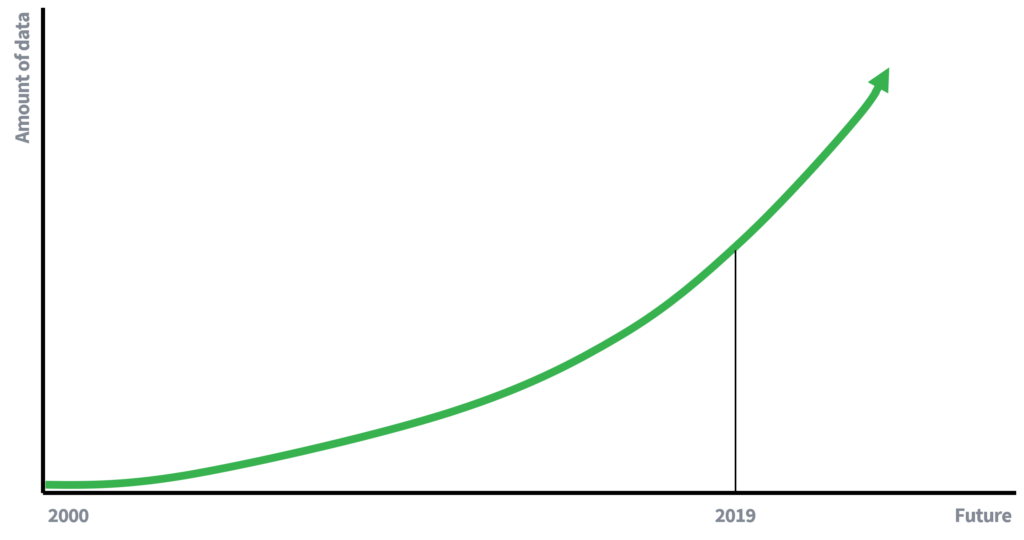
आधीच्या दिवसांमध्ये, डेटाची उपलब्धता खूपच मर्यादित होती, जी अंशतः स्पष्ट करते की व्यक्तींची गोपनीयता जपण्यासाठी नावे काढून टाकणे का पुरेसे आहे. कमी उपलब्ध डेटा म्हणजे डेटा लिंक करण्याच्या कमी संधी. तथापि, आम्ही आता डेटा-आधारित अर्थव्यवस्थेत (सक्रिय) सहभागी आहोत, जिथे डेटाचे प्रमाण घातांक दराने वाढत आहे. अधिक डेटा, आणि डेटा गोळा करण्यासाठी तंत्रज्ञान सुधारल्याने लिंकेज अटॅकची शक्यता वाढेल. लिंकेज अटॅकच्या जोखमीबद्दल 10 वर्षांत काय लिहावे?
स्पष्टीकरण एक्सएनयूएमएक्स
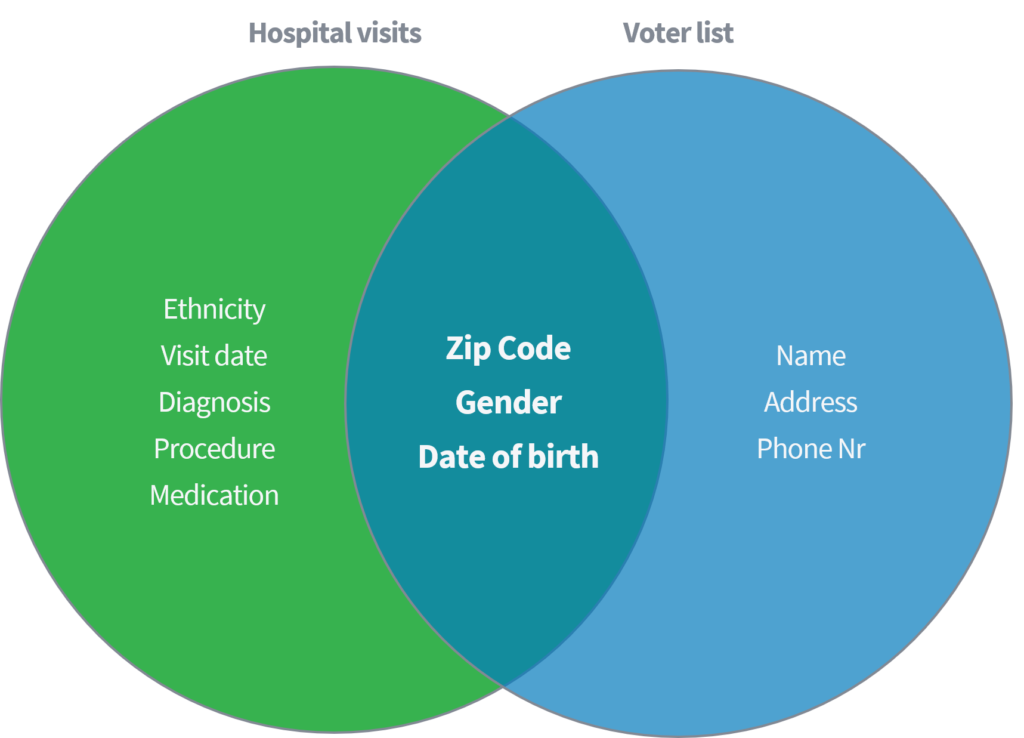
स्वीनी (2002) ने एका शैक्षणिक पेपरमध्ये दाखवून दिले की ती 'हॉस्पिटल व्हिजिट्स' चा सार्वजनिक उपलब्ध डेटा संच युनायटेड स्टेट्समधील सार्वजनिकरित्या उपलब्ध मतदान रजिस्ट्रारशी जोडण्यावर आधारित व्यक्तींकडून संवेदनशील वैद्यकीय डेटा कसा ओळखू आणि पुनर्प्राप्त करण्यात सक्षम आहे. दोन्ही डेटासेट जेथे नावे आणि इतर थेट अभिज्ञापक हटवून योग्यरित्या अज्ञात असल्याचे मानले जाते.
स्पष्टीकरण एक्सएनयूएमएक्स
फक्त तीन पॅरामीटर्स (1) पिन कोड, (2) लिंग आणि (3) जन्मतारखेच्या आधारे, तिने दर्शविले की संपूर्ण यूएस लोकसंख्येपैकी 87% दोन्ही डेटासेटमधील उपरोक्त गुणांशी जुळवून पुन्हा ओळखले जाऊ शकतात. स्वीनीने नंतर 'पिन कोड'ला पर्याय म्हणून' देश 'असण्यासह तिच्या कार्याची पुनरावृत्ती केली. याव्यतिरिक्त, तिने दाखवून दिले की संपूर्ण यूएस लोकसंख्येच्या 18% केवळ (1) मूळ देश, (2) लिंग आणि (3) जन्मतारखेची माहिती असलेल्या डेटासेटमध्ये प्रवेश करून ओळखली जाऊ शकते. फेसबुक, लिंक्डइन किंवा इन्स्टाग्राम सारख्या वरील सार्वजनिक स्त्रोतांचा विचार करा. तुमचा देश, लिंग आणि जन्मतारीख दृश्यमान आहे किंवा इतर वापरकर्ते ते वजा करू शकतात?
स्पष्टीकरण एक्सएनयूएमएक्स
| अर्ध-अभिज्ञापक | यूएस लोकसंख्येची विशिष्ट ओळख % (248 दशलक्ष) |
| 5-अंकी झिप, लिंग, जन्मतारीख | 87% |
| स्थान, लिंग, जन्मतारीख | 53% |
| देशातील, लिंग, जन्मतारीख | 18% |
हे उदाहरण दर्शवते की व्यक्तींना अज्ञात डेटामध्ये अज्ञात करणे सोपे आहे. प्रथम, हा अभ्यास मोठ्या प्रमाणावर जोखीम दर्शवतो 87% अमेरिकन लोकसंख्या वापरून सहज ओळखता येते काही वैशिष्ट्ये. दुसरे म्हणजे, या अभ्यासातील उघड वैद्यकीय डेटा अत्यंत संवेदनशील होता. रुग्णालयाच्या भेटीच्या डेटासेटमधून उघड झालेल्या व्यक्तींच्या डेटाची उदाहरणे वांशिकता, निदान आणि औषधोपचार यांचा समावेश करतात. गुण जे एखादी व्यक्ती गुप्त ठेवू शकते, उदाहरणार्थ, विमा कंपन्यांकडून.
केवळ प्रत्यक्ष ओळखकर्ता काढून टाकण्याचा आणखी एक धोका, जसे की नावे, जेव्हा माहिती असलेल्या व्यक्तींना डेटासेटमधील विशिष्ट व्यक्तींच्या गुणधर्मांबद्दल किंवा त्यांच्या वर्तनाबद्दल उत्कृष्ट ज्ञान किंवा माहिती असते तेव्हा उद्भवते.. त्यांच्या ज्ञानाच्या आधारे, हल्लेखोर नंतर विशिष्ट डेटा रेकॉर्ड वास्तविक लोकांशी जोडण्यास सक्षम होऊ शकतो.
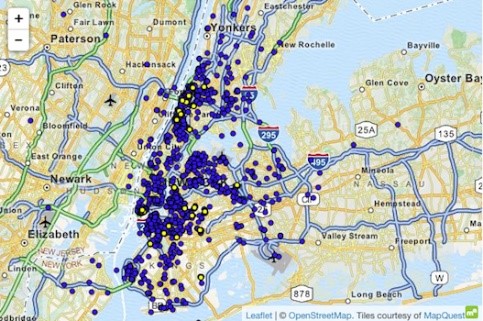
उच्च ज्ञानाचा वापर करून डेटासेटवरील हल्ल्याचे उदाहरण म्हणजे न्यूयॉर्क टॅक्सी प्रकरण, जिथे अटोकर (2014) विशिष्ट व्यक्तींना उघडे पाडण्यास सक्षम होते. नियोजित डेटासेटमध्ये न्यूयॉर्कमधील सर्व टॅक्सी प्रवास समाविष्ट आहेत, प्रारंभिक समन्वय, समाप्ती निर्देशांक, राइडची किंमत आणि टिप यासारख्या मूलभूत गुणांनी समृद्ध.
न्यूयॉर्कला माहीत असलेला एक माहितीपूर्ण व्यक्ती प्रौढ क्लब 'हस्टलर' ला टॅक्सी प्रवास करू शकला. 'शेवटचे स्थान' फिल्टर करून, त्याने अचूक प्रारंभ पत्ते काढले आणि त्याद्वारे विविध वारंवार येणाऱ्यांना ओळखले. त्याचप्रमाणे, जेव्हा एखाद्या व्यक्तीचा घरचा पत्ता माहित असेल तेव्हा कोणी टॅक्सी राइड काढू शकतो. गॉसिप साइट्सवर अनेक सेलिब्रिटी चित्रपट स्टार्सचा वेळ आणि स्थान शोधण्यात आले. ही माहिती NYC टॅक्सी डेटाशी लिंक केल्यानंतर, त्यांच्या टॅक्सी राईड्स, त्यांनी भरलेली रक्कम आणि त्यांनी टीप दिली होती का ते मिळवणे सोपे होते.
स्पष्टीकरण एक्सएनयूएमएक्स
ड्रॉप-ऑफ समन्वय हस्टलर
ब्रॅडली कूपर
जेसिका अल्बा
युक्तिवादाची एक सामान्य ओळ म्हणजे 'हा डेटा व्यर्थ आहे' किंवा 'या डेटासह कोणीही काहीही करू शकत नाही'. हा सहसा गैरसमज असतो. अगदी निष्पाप डेटा देखील एक अद्वितीय 'फिंगरप्रिंट' बनवू शकतो आणि व्यक्तींना पुन्हा ओळखण्यासाठी वापरला जाऊ शकतो. डेटा स्वतःच निरुपयोगी आहे असे मानण्यामुळे उद्भवलेला धोका आहे, तर तो नाही.
डेटा, एआय आणि इतर साधने आणि अल्गोरिदम वाढल्याने ओळखीचा धोका वाढेल ज्यामुळे डेटामधील गुंतागुंतीचे संबंध उघड होऊ शकतात. परिणामी, जरी आपला डेटासेट आता उघड केला जाऊ शकत नाही, आणि आज अनधिकृत व्यक्तींसाठी कदाचित निरुपयोगी आहे, तो उद्या असू शकत नाही.
एक उत्तम उदाहरण म्हणजे जेथे Netflix ने त्यांच्या R&D विभागाला त्यांच्या चित्रपट शिफारस प्रणालीमध्ये सुधारणा करण्यासाठी खुली Netflix स्पर्धा सादर करून क्राउडसोर्स करण्याचा हेतू ठेवला होता. 'जो चित्रपटांसाठी वापरकर्त्याच्या रेटिंगचा अंदाज लावण्यासाठी सहयोगी फिल्टरिंग अल्गोरिदम सुधारतो तो US $ 1,000,000 चे बक्षीस जिंकतो'. गर्दीला पाठिंबा देण्यासाठी, नेटफ्लिक्सने फक्त खालील मूलभूत गुणधर्म असलेला डेटासेट प्रकाशित केला: युजरआयडी, मूव्ही, ग्रेड आणि ग्रेडची तारीख (त्यामुळे वापरकर्त्यावर किंवा चित्रपटावरच अधिक माहिती नाही).
स्पष्टीकरण एक्सएनयूएमएक्स
| यूजरआयडी | चित्रपट | ग्रेडची तारीख | ग्रेड |
| 123456789 | मिशन अशक्य | 10-12-2008 | 4 |
अलगाव मध्ये, डेटा व्यर्थ दिसला. प्रश्न विचारताना 'डेटासेटमध्ये ग्राहकांची काही माहिती आहे जी खाजगी ठेवली पाहिजे?', उत्तर असे होते:
'नाही, ग्राहक ओळखणारी सर्व माहिती काढून टाकण्यात आली आहे; बाकी सर्व रेटिंग आणि तारखा आहेत. हे आमच्या गोपनीयता धोरणाचे अनुसरण करते ... '
तथापि, ऑस्टिन येथील टेक्सास विद्यापीठातील नारायणन (2008) अन्यथा सिद्ध झाले. ग्रेड, ग्रेडची तारीख आणि एखाद्या व्यक्तीच्या चित्रपटाचे संयोजन एक अद्वितीय चित्रपट-फिंगरप्रिंट बनवते. आपल्या स्वतःच्या नेटफ्लिक्स वर्तनाचा विचार करा. तुम्हाला असे वाटते की समान चित्रपटांचे किती लोक पाहिले? एकाच वेळी किती चित्रपटांचा सेट पाहिला?
मुख्य प्रश्न, हे फिंगरप्रिंट कसे जुळवायचे? ते ऐवजी सोपे होते. सुप्रसिद्ध मूव्ही-रेटिंग वेबसाइट IMDb (इंटरनेट मूव्ही डेटाबेस) च्या माहितीच्या आधारावर, एक समान फिंगरप्रिंट तयार केले जाऊ शकते. परिणामी, व्यक्तींना पुन्हा ओळखले जाऊ शकते.
चित्रपट पाहण्याचे वर्तन संवेदनशील माहिती म्हणून गृहीत धरले जात नसले तरी, आपल्या स्वतःच्या वर्तनाबद्दल विचार करा-जर ती सार्वजनिक झाली तर तुम्हाला काही हरकत आहे का? नारायणन यांनी त्यांच्या पेपरमध्ये पुरवलेली उदाहरणे म्हणजे राजकीय प्राधान्ये ('जीझस ऑफ नाझरेथ' आणि 'द गॉस्पेल ऑफ जॉन') आणि लैंगिक आवडीनिवडी ('बेंट' आणि 'क्वीर अॅज फॉक') जे सहज डिस्टिल्ड केले जाऊ शकतात.
GDPR कदाचित ब्लॉग विषयांमध्ये सुपर-रोमांचक किंवा चांदीची बुलेट असू शकत नाही. तरीही, वैयक्तिक डेटावर प्रक्रिया करताना सरळ व्याख्या मिळवणे उपयुक्त ठरते. हा ब्लॉग डेटा अनामित करण्याचा आणि डेटा प्रोसेसर म्हणून शिकवण्याचा एक मार्ग म्हणून स्तंभ काढून टाकण्याच्या सामान्य गैरसमजांबद्दल असल्याने, GDPR नुसार अनामिकतेची व्याख्या एक्सप्लोर करूया.
जीडीपीआर मधील 26 वाचनानुसार, अज्ञात माहिती अशी परिभाषित केली आहे:
'अशी माहिती जी ओळखल्या गेलेल्या किंवा ओळखण्यायोग्य नैसर्गिक व्यक्तीशी संबंधित नाही किंवा वैयक्तिक डेटा अनामिकपणे अशा प्रकारे सादर केला गेला आहे की डेटा विषय नाही किंवा यापुढे ओळखण्यायोग्य नाही.'
एखादी व्यक्ती नैसर्गिक डेटाशी संबंधित वैयक्तिक डेटावर प्रक्रिया करत असल्याने, व्याख्येचा फक्त भाग 2 संबंधित आहे. व्याख्येचे पालन करण्यासाठी, एखाद्याने हे सुनिश्चित केले पाहिजे की डेटा विषय (वैयक्तिक) यापुढे ओळखण्यायोग्य नाही किंवा नाही. या ब्लॉगमध्ये सूचित केल्याप्रमाणे, काही गुणधर्मांवर आधारित व्यक्ती ओळखणे हे उल्लेखनीय सोपे आहे. म्हणून, डेटासेटमधून नावे काढून टाकणे अनामिकतेच्या जीडीपीआर व्याख्येचे पालन करत नाही.
आम्ही सामान्यतः विचारात घेतल्या गेलेल्या आणि दुर्दैवाने, डेटा अनामितीकरणाच्या वारंवार लागू केलेल्या पद्धतीला आव्हान दिले: नावे काढून टाकणे. गेस हू गेममध्ये आणि इतर चार उदाहरणे:
हे दाखवले गेले की नावे काढणे अज्ञात म्हणून अयशस्वी होते. उदाहरणे धक्कादायक प्रकरणे असली तरी, प्रत्येक पुन्हा ओळखण्याची साधेपणा दर्शवते आणि व्यक्तींच्या गोपनीयतेवर संभाव्य नकारात्मक परिणाम.
शेवटी, तुमच्या डेटासेटमधून नावे काढून टाकल्याने अनामिक डेटा मिळत नाही. म्हणून, आम्ही दोन्ही अटी परस्पर बदलणे टाळणे चांगले. मला मनापासून आशा आहे की तुम्ही हा दृष्टिकोन अनामिकतेसाठी लागू करणार नाही. आणि, जर तुम्ही अजूनही करत असाल, तर तुम्ही आणि तुमची टीम गोपनीयतेचे धोके पूर्णपणे समजून घेत असल्याची खात्री करा आणि प्रभावित व्यक्तींच्या वतीने ते जोखीम स्वीकारण्याची परवानगी आहे.
सिंथोशी संपर्क साधा आणि सिंथेटिक डेटाचे मूल्य एक्सप्लोर करण्यासाठी आमचा एक विशेषज्ञ प्रकाशाच्या वेगाने तुमच्याशी संपर्क साधेल!