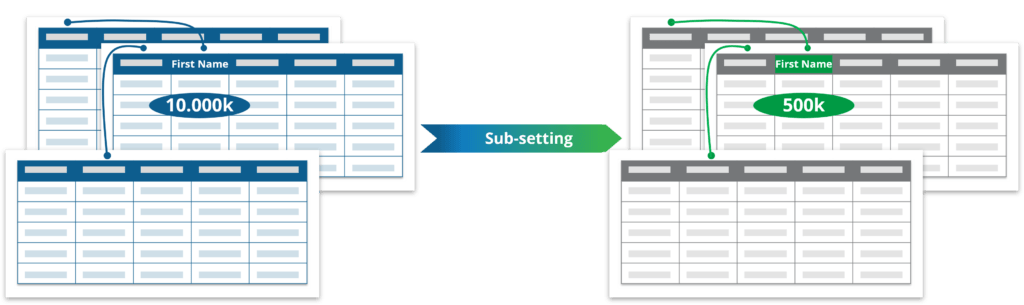

संरक्षित सन्दर्भ अखण्डताको साथ रिलेशनल डाटाबेसको सानो प्रतिनिधि सबसेट सिर्जना गर्न रेकर्डहरूको संख्या घटाउनुहोस्।
धेरै संस्थाहरूसँग ठूलो मात्रामा डाटाको साथ उत्पादन वातावरण छ र गैर-उत्पादन परीक्षण वातावरणमा ठूलो मात्रामा डाटा चाहँदैनन्। तसर्थ, डाटाबेस सबसेटिङलाई संरक्षित सन्दर्भ अखण्डताको साथ ठूलो रिलेशनल डाटाबेसको सानो, प्रतिनिधि सबसेट सिर्जना गर्न प्रयोग गरिन्छ। संगठनहरूले लागत घटाउन, यसलाई व्यवस्थित गर्न र छिटो सेटअप र मर्मतका लागि परीक्षण डेटाको लागि उप-सेटिङ प्रयोग गर्छन्।
अत्यधिक डेटा भोल्युमहरूले उच्च पूर्वाधार र गणना लागतहरू निम्त्याउन सक्छ, जुन गैर-उत्पादन वातावरणमा परीक्षण डेटाको लागि अनावश्यक हुन्छ। सबसेटिङ क्षमताहरूको साथ, तपाइँ तपाइँको लागत कम गर्न को लागी तपाइँको डाटा को साना सबसेटहरु लाई सजिलै संग बनाउन सक्नुहुन्छ।
गैर-उत्पादन वातावरणमा विशाल डेटा भोल्युमहरू प्रबन्ध गर्न परीक्षकहरू र विकासकर्ताहरूको लागि चुनौतीहरू खडा हुन्छन्। सानो र यसरी थप व्यवस्थित परीक्षण डेटा, महत्त्वपूर्ण रूपमा परीक्षण र विकास प्रक्रियाहरू सुव्यवस्थित गर्दै, अन्ततः समय र स्रोतहरूको सर्तमा सम्पूर्ण चक्रलाई अनुकूलन गर्दै।
साना डेटा भोल्युमहरूले छिटो र थप सीधा सेटअप र गैर-उत्पादन परीक्षण वातावरणको मर्मत सुविधा दिन्छ। यो विशेष गरी जटिल IT परिदृश्यहरूमा सान्दर्भिक छ र जब डेटा संरचनाहरूमा बारम्बार परिवर्तनहरू परीक्षण डेटाको प्रतिनिधित्व सुनिश्चित गर्न नियमित अपडेटहरू र रिफ्रेसहरू आवश्यक पर्दछ।
सन्दर्भ अखंडता डाटाबेस व्यवस्थापनमा एक अवधारणा हो जसले एक रिलेशनल डाटाबेसमा तालिकाहरू बीच स्थिरता र शुद्धता सुनिश्चित गर्दछ। सन्दर्भ अखण्डताले "तालिका 1" को "व्यक्ति 1" सँग मेल खाने हरेक मान "तालिका 1" र कुनै अन्य लिङ्क गरिएको तालिकाको "व्यक्ति 2" को सही मानसँग मेल खान्छ भन्ने सुनिश्चित गर्नेछ।
गैर-उत्पादन वातावरणको भागको रूपमा रिलेशनल डाटाबेसमा परीक्षण डाटाको विश्वसनीयता कायम राख्न सन्दर्भात्मक अखण्डता लागू गर्नु महत्त्वपूर्ण छ। यसले डेटा असंगतिहरूलाई रोक्छ र उचित परीक्षण र सफ्टवेयर विकासको लागि तालिकाहरू बीचको सम्बन्ध अर्थपूर्ण र भरपर्दो छ भनी सुनिश्चित गर्दछ।
रिलेसनल डाटाबेस वातावरणमा परीक्षण डाटा प्रयोग गर्न योग्य हुन सन्दर्भ अखण्डता जोगाउनु पर्छ। परीक्षण र सफ्टवेयर विकासका लागि प्रयोग गरिएका गैर-उत्पादन वातावरणहरूमा सन्दर्भ अखण्डता कायम राख्नु धेरै कारणहरूको लागि महत्त्वपूर्ण छ:
सबसेटिङ केवल डाटा मेटाउन जत्तिकै सजिलो छैन, किनकि सबै डाउनस्ट्रीम र अपस्ट्रीम सम्बन्धित लिङ्क गरिएका तालिकाहरू सन्दर्भात्मक अखण्डता जोगाउन समानुपातिक रूपमा सबसेट हुनुपर्छ। सबसेटिङले लक्ष्य तालिकामा रहेको डाटा मात्र मेटिएको होइन, तर लक्ष्य तालिकाबाट मेटाइएको डाटासँग सम्बन्धित कुनै पनि अन्य लिङ्क गरिएको तालिकामा रहेको कुनै पनि डाटा मेटाइने कुरा सुनिश्चित गर्दछ। यसले तालिकाहरू, डाटाबेसहरू र प्रणालीहरूमा सन्दर्भात्मक अखण्डता डेटा मेटाउने भागको रूपमा सुरक्षित गरिएको छ भनेर सुनिश्चित गर्दछ।
"तालिका Y" बाट "व्यक्ति X" हटाएर डाटा भोल्युम घटाउँदै, "तालिका Y" मा रहेको "व्यक्ति X" सँग सम्बन्धित सबै अभिलेखहरू मेटाइनुपर्छ, तर अन्य कुनै अपस्ट्रिम वा डाउनस्ट्रीम सम्बन्धित तालिका (तालिका A, B, C आदि) मा रहेको "व्यक्ति X" सँग सम्बन्धित सबै रेकर्डहरू पनि मेटाइनुपर्छ।
"ग्राहक" तालिकाबाट "रिचर्ड" हटाएर डाटा भोल्युम घटाउँदै, "ग्राहक" तालिकामा "रिचर्ड" सम्बन्धी सबै अभिलेखहरू मेटाइनुपर्छ, तर कुनै पनि अन्य अपस्ट्रिम वा डाउनस्ट्रीम सम्बन्धित तालिका (भुक्तानी तालिका, घटना तालिका, बीमा कवरेज तालिका आदि) मा "रिचर्ड" सम्बन्धी सबै रेकर्डहरू पनि मेटाइनुपर्छ। मेटाइयो।
सबसेटिङले तालिकाहरूमा काम गर्छ
सबसेटिङ डाटाबेसमा काम गर्दछ
सबसेटिङ प्रणालीहरूमा काम गर्दछ
तपाईले सिन्थो इन्जिनलाई रिलेसनल डाटाबेसलाई सबसेट गर्न र "लक्ष्य तालिका" मा आधारित सबै "लिंक गरिएका तालिकाहरू" सबसेट गरिएको सुनिश्चित गर्न कन्फिगर गर्न सक्नुहुन्छ।
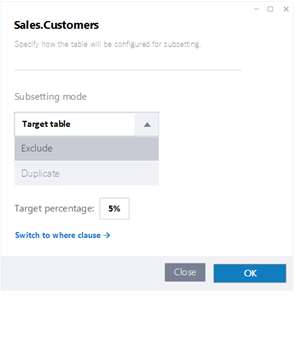
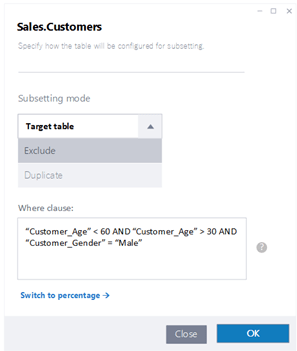
समानुपातिक सबसेटिङको अतिरिक्त, जहाँ तपाइँ डेटा निकासीको लागि प्रतिशत निर्दिष्ट गर्नुहुन्छ, हाम्रो उन्नत क्षमताहरूले तपाइँलाई सबसेटिङको लागि लक्ष्य समूहलाई ठीकसँग परिभाषित गर्न अनुमति दिन्छ। उदाहरणका लागि, तपाईंले डेटा निकासी प्रक्रियामा थप लचिलोपन र नियन्त्रण प्रदान गर्दै, विशेष उपसेटहरू समावेश वा बहिष्कार गर्न मापदण्ड निर्दिष्ट गर्न सक्नुहुन्छ।
