


Syntho द्वारा उत्पन्न सिंथेटिक डाटा SAS को डाटा विशेषज्ञहरु द्वारा बाह्य र वस्तुनिष्ठ दृष्टिकोणबाट मूल्याङ्कन, प्रमाणीकरण र अनुमोदन गरिन्छ।
यद्यपि सिन्थोले आफ्ना प्रयोगकर्ताहरूलाई उन्नत गुणस्तर आश्वासन प्रतिवेदन प्रदान गर्न पाउँदा गर्व छ, हामी उद्योगका नेताहरूबाट हाम्रो सिंथेटिक डेटाको बाह्य र वस्तुनिष्ठ मूल्याङ्कन गर्नुको महत्त्व पनि बुझ्छौं। यसैले हामी हाम्रो सिंथेटिक डेटाको मूल्याङ्कन गर्नको लागि विश्लेषणमा अग्रणी SAS सँग सहकार्य गर्छौं।
SAS ले मौलिक डेटाको तुलनामा Syntho को AI-उत्पन्न सिंथेटिक डेटाको डेटा-शुद्धता, गोपनीयता सुरक्षा, र उपयोगितामा विभिन्न गहन मूल्याङ्कनहरू सञ्चालन गर्दछ। निष्कर्षको रूपमा, SAS ले सिन्थोको सिंथेटिक डाटालाई मौलिक डाटाको तुलनामा सही, सुरक्षित र प्रयोगयोग्य भएको रूपमा मूल्याङ्कन र अनुमोदन गर्यो।
हामीले टेलिकम डेटा प्रयोग गर्यौं जुन लक्ष्य डेटाको रूपमा "मंथन" भविष्यवाणीको लागि प्रयोग गरिन्छ। मूल्याङ्कनको लक्ष्य विभिन्न मन्थन भविष्यवाणी मोडेलहरूलाई तालिम दिन र प्रत्येक मोडेलको कार्यसम्पादन मूल्याङ्कन गर्न सिंथेटिक डाटा प्रयोग गर्नु थियो। मन्थन भविष्यवाणी वर्गीकरण कार्य भएको हुनाले, SAS ले भविष्यवाणी गर्न लोकप्रिय वर्गीकरण मोडेलहरू चयन गर्यो, जसमा:
सिंथेटिक डाटा उत्पन्न गर्नु अघि, SAS ले टेलिकम डाटासेटलाई अनियमित रूपमा ट्रेन सेट (मोडलहरू प्रशिक्षणको लागि) र होल्डआउट सेट (मोडलहरू स्कोर गर्नको लागि) मा विभाजित गर्दछ। स्कोरिङको लागि छुट्टै होल्डआउट सेट हुनुले नयाँ डाटामा लागू गर्दा वर्गीकरण मोडेलले कत्तिको राम्रो गर्न सक्छ भन्ने निष्पक्ष मूल्याङ्कन गर्न अनुमति दिन्छ।
इनपुटको रूपमा ट्रेन सेट प्रयोग गरेर, सिन्थोले सिन्थेटिक डेटासेट उत्पन्न गर्न यसको सिन्थो इन्जिन प्रयोग गर्यो। बेन्चमार्किङका लागि, SAS ले एउटा निश्चित थ्रेसहोल्ड (k-अनामताको) मा पुग्न विभिन्न बेनामी प्रविधिहरू लागू गरेपछि ट्रेन सेटको बेनामी संस्करण पनि सिर्जना गर्यो। अघिल्लो चरणहरू चार डेटासेटहरूमा परिणाम:
डेटासेटहरू 1, 3 र 4 प्रत्येक वर्गीकरण मोडेललाई तालिम दिन प्रयोग गरिएको थियो, परिणामस्वरूप 12 (3 x 4) प्रशिक्षित मोडेलहरू। SAS ले पछि ग्राहक मन्थनको भविष्यवाणीमा प्रत्येक मोडेलको शुद्धता मापन गर्न होल्डआउट डाटासेट प्रयोग गर्यो।
SAS ले मौलिक डेटाको तुलनामा Syntho को AI-उत्पन्न सिंथेटिक डेटाको डेटा-शुद्धता, गोपनीयता सुरक्षा, र उपयोगितामा विभिन्न गहन मूल्याङ्कनहरू सञ्चालन गर्दछ। निष्कर्षको रूपमा, SAS ले सिन्थोको सिंथेटिक डाटालाई मौलिक डाटाको तुलनामा सही, सुरक्षित र प्रयोगयोग्य भएको रूपमा मूल्याङ्कन र अनुमोदन गर्यो।
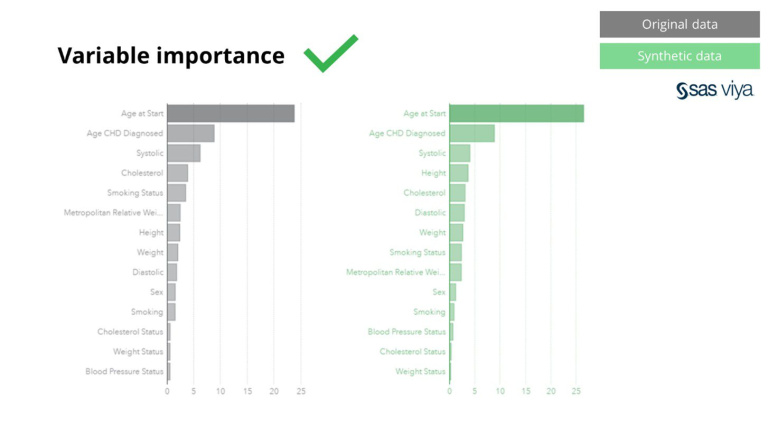
सिन्थोको सिंथेटिक डेटाले आधारभूत ढाँचाहरूको लागि मात्र होइन, यसले उन्नत विश्लेषणात्मक कार्यहरूको लागि आवश्यक गहिरो 'लुकेका' सांख्यिकीय ढाँचाहरू पनि क्याप्चर गर्दछ। पछिल्लो बार चार्टमा प्रदर्शन गरिएको छ, यसले संकेत गर्दछ कि सिंथेटिक डाटामा प्रशिक्षित मोडेलहरूको शुद्धता बनाम मूल डाटामा प्रशिक्षित मोडेलहरू समान छन्। तसर्थ, सिंथेटिक डाटा मोडेलहरूको वास्तविक प्रशिक्षणको लागि प्रयोग गर्न सकिन्छ। मूल डाटाको तुलनामा सिंथेटिक डाटामा एल्गोरिदमहरू द्वारा चयन गरिएका इनपुटहरू र चर महत्त्व धेरै समान थिए। तसर्थ, यो निष्कर्षमा पुग्छ कि मोडेलिङ प्रक्रिया सिंथेटिक डाटामा गर्न सकिन्छ, वास्तविक संवेदनशील डाटा प्रयोग गर्नको लागि विकल्पको रूपमा।
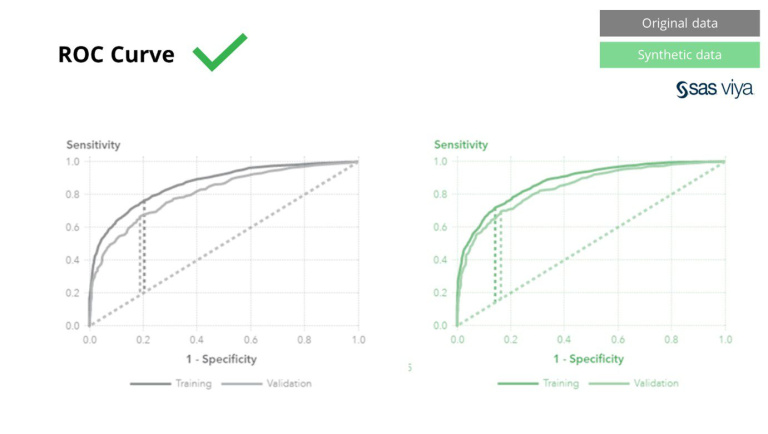
क्लासिक एनोनिमाइजेसन प्रविधिहरू सामान्य छन् कि तिनीहरूले व्यक्तिहरूलाई ट्रेसिङमा बाधा पुर्याउन मूल डेटा हेरफेर गर्छन्। तिनीहरू डेटा हेरफेर गर्छन् र यसैले प्रक्रियामा डाटा नष्ट गर्छन्। तपाईले जति धेरै गुमनाम गर्नुहुन्छ, तपाईको डेटा सुरक्षित हुन्छ, तर तपाईको डेटा जति धेरै नष्ट हुन्छ। यो विशेष गरी एआई र मोडलिङ कार्यहरूको लागि विनाशकारी छ जहाँ "भविष्यवाणी शक्ति" आवश्यक छ, किनभने खराब गुणस्तर डेटाले एआई मोडेलबाट खराब अन्तरदृष्टिको परिणाम दिन्छ। SAS ले यो प्रदर्शन गर्यो, कर्भ (AUC*) अन्तर्गतको क्षेत्र ०.५ को नजिक, अज्ञात डेटामा प्रशिक्षित मोडेलहरूले सबैभन्दा खराब प्रदर्शन गरेको देखाउँदै।
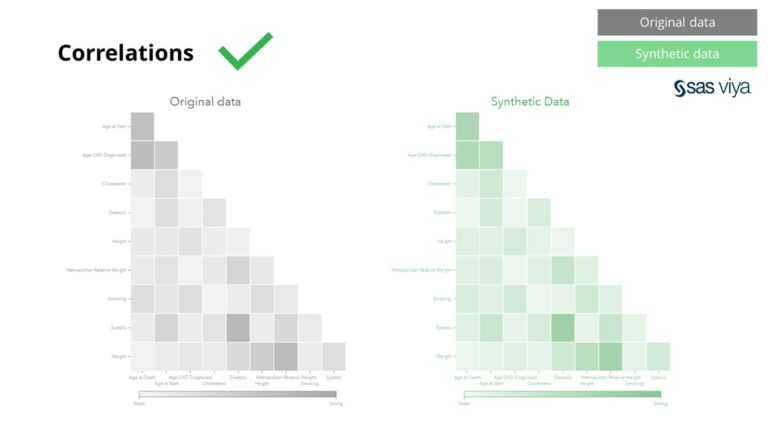
चरहरू बीचको सहसंबंध र सम्बन्धहरू सिंथेटिक डेटामा सही रूपमा सुरक्षित गरिएको थियो।
कर्भ अन्तर्गत क्षेत्र (AUC), मोडेल प्रदर्शन मापनको लागि एक मेट्रिक, स्थिर रह्यो।
यसबाहेक, चर महत्त्व, जसले मोडेलमा चरहरूको भविष्यवाणी गर्ने शक्तिलाई संकेत गर्छ, सिंथेटिक डेटालाई मूल डेटासेटसँग तुलना गर्दा यथावत रह्यो।
SAS द्वारा र SAS Viya प्रयोग गरेर यी अवलोकनहरूको आधारमा, हामी सिन्थो इन्जिन द्वारा उत्पन्न सिंथेटिक डाटा वास्तवमा गुणस्तरको सन्दर्भमा वास्तविक डाटासँग बराबर छ भन्ने निष्कर्षमा पुग्न सक्छौं। यसले मोडेल विकासको लागि सिंथेटिक डेटाको प्रयोगलाई प्रमाणित गर्दछ, सिंथेटिक डेटाको साथ उन्नत विश्लेषणहरूको लागि मार्ग प्रशस्त गर्दछ।
