AI-उत्पन्न सिंथेटिक डाटा, उच्च गुणस्तर डाटामा सजिलो र छिटो पहुँच?
एआईले अभ्यासमा सिंथेटिक डाटा उत्पन्न गर्यो
सिन्थो, एआई-उत्पन्न सिंथेटिक डाटा मा एक विशेषज्ञ, घुमाउने लक्ष्य छ privacy by design AI-उत्पन्न सिंथेटिक डेटा संग प्रतिस्पर्धात्मक लाभ मा। तिनीहरूले संगठनहरूलाई उच्च गुणस्तरको डाटामा सजिलो र द्रुत पहुँचको साथ बलियो डाटा फाउन्डेशन निर्माण गर्न मद्दत गर्छन् र हालै फिलिप्स इनोभेसन अवार्ड जितेका छन्।
यद्यपि, AI सँग सिंथेटिक डेटा उत्पादन अपेक्षाकृत नयाँ समाधान हो जसले प्रायः सोधिने प्रश्नहरूको परिचय दिन्छ। यसको जवाफ दिनको लागि, सिन्थोले SAS, Advanced Analytics र AI सफ्टवेयरमा बजार प्रमुखसँग मिलेर केस-स्टडी सुरु गर्यो।
डच एआई गठबन्धन (NL AIC) सँगको सहकार्यमा, तिनीहरूले डेटाको गुणस्तर, कानूनी वैधता र उपयोगितामा विभिन्न मूल्याङ्कनहरू मार्फत सिन्थो इन्जिनद्वारा उत्पन्न AI-उत्पन्न सिंथेटिक डाटालाई मौलिक डाटासँग तुलना गरेर सिंथेटिक डाटाको मूल्यको अनुसन्धान गरे।
के डाटा एनोनिमाइजेसन समाधान होइन?
क्लासिक एनोनिमाइजेसन प्रविधिहरूमा सामान्य छ कि तिनीहरूले व्यक्तिहरूलाई ट्रेसिङमा बाधा पुर्याउन मौलिक डेटा हेरफेर गर्छन्। उदाहरणहरू सामान्यीकरण, दमन, वाइपिङ, छद्म नामकरण, डेटा मास्किङ, र पङ्क्ति र स्तम्भहरू फेरबदल हुन्। तपाईंले तलको तालिकामा उदाहरणहरू फेला पार्न सक्नुहुन्छ।
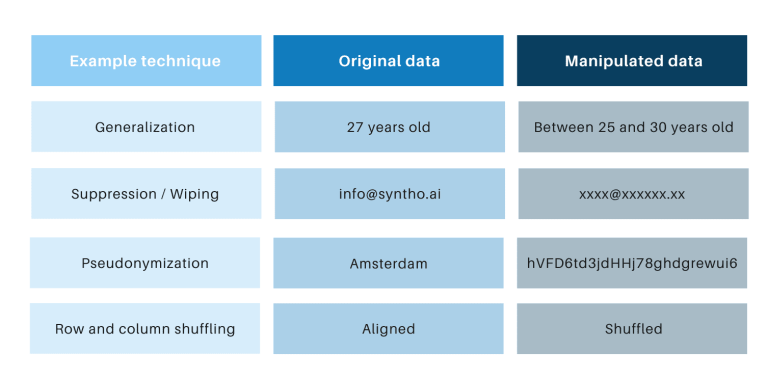
ती प्रविधिहरूले 3 प्रमुख चुनौतीहरू प्रस्तुत गर्दछ:
- तिनीहरू प्रति डेटा प्रकार र प्रति डेटासेट फरक तरिकाले काम गर्छन्, तिनीहरूलाई मापन गर्न गाह्रो बनाउँदै। यसबाहेक, तिनीहरू फरक तरिकाले काम गर्ने हुनाले, कुन विधिहरू लागू गर्ने र कुन प्रविधिहरूको संयोजन आवश्यक छ भन्ने बारेमा सधैं बहस हुनेछ।
- मूल डाटासँग सधैं एक-देखि-एक सम्बन्ध हुन्छ। यसको मतलब त्यहाँ सधैं गोपनीयता जोखिम हुनेछ, विशेष गरी सबै खुला डाटासेटहरू र ती डाटासेटहरू लिङ्क गर्न उपलब्ध प्रविधिहरूको कारण।
- तिनीहरू डेटा हेरफेर गर्छन् र यसैले प्रक्रियामा डाटा नष्ट गर्छन्। यो विशेष गरी AI कार्यहरूको लागि विनाशकारी छ जहाँ "भविष्यवाणी शक्ति" आवश्यक छ, किनभने खराब गुणस्तर डेटाले AI मोडेलबाट खराब अन्तरदृष्टिको परिणाम दिन्छ (गार्बेज-इनले फोहोर-आउटको परिणाम हुनेछ)।
यी बुँदाहरू पनि यस केस स्टडी मार्फत मूल्याङ्कन गरिन्छ।
केस स्टडीको परिचय
केस स्टडीको लागि, लक्षित डाटासेट SAS द्वारा उपलब्ध गराइएको टेलिकम डाटासेट थियो जसमा 56.600 ग्राहकहरूको डाटा थियो। डाटासेटमा 128 स्तम्भहरू छन्, जसमा ग्राहकले कम्पनी छोडेको छ वा छैन भन्ने संकेत गर्ने एउटा स्तम्भ सहित। केस स्टडीको लक्ष्य ग्राहक मन्थन भविष्यवाणी गर्न र ती प्रशिक्षित मोडेलहरूको कार्यसम्पादन मूल्याङ्कन गर्न केही मोडेलहरूलाई तालिम दिन सिंथेटिक डाटा प्रयोग गर्नु थियो। मन्थन भविष्यवाणी वर्गीकरण कार्य भएकोले, SAS ले भविष्यवाणी गर्न चार लोकप्रिय वर्गीकरण मोडेलहरू चयन गर्यो, जसमा:
- अनियमित जंगल
- ग्रेडियन्ट बढावा
- लजिस्टिक प्रतिगमन
- तंत्रिका नेटवर्क
सिंथेटिक डाटा उत्पन्न गर्नु अघि, SAS ले टेलिकम डाटासेटलाई अनियमित रूपमा ट्रेन सेट (मोडलहरू प्रशिक्षणको लागि) र होल्डआउट सेट (मोडलहरू स्कोर गर्नको लागि) मा विभाजित गर्दछ। स्कोरिङका लागि छुट्टै होल्डआउट सेट हुनुले नयाँ डाटामा लागू गर्दा वर्गीकरण मोडेलले कत्तिको राम्रो प्रदर्शन गर्न सक्छ भन्ने निष्पक्ष मूल्याङ्कन गर्न अनुमति दिन्छ।
इनपुटको रूपमा ट्रेन सेट प्रयोग गरेर, सिन्थोले सिन्थेटिक डेटासेट उत्पन्न गर्न यसको सिन्थो इन्जिन प्रयोग गर्यो। बेन्चमार्किङका लागि, SAS ले एउटा निश्चित थ्रेसहोल्ड (k-anonimity) मा पुग्न विभिन्न अज्ञात प्रविधिहरू लागू गरेपछि ट्रेन सेटको हेरफेर संस्करण पनि सिर्जना गर्यो। अघिल्लो चरणहरू चार डेटासेटहरूमा परिणाम:
- ट्रेन डेटासेट (अर्थात् मूल डेटासेट माइनस होल्डआउट डेटासेट)
- एक होल्डआउट डेटासेट (जस्तै मूल डेटासेट को एक उपसेट)
- एउटा अज्ञात डेटासेट (ट्रेन डेटासेटमा आधारित)
- सिंथेटिक डाटासेट (ट्रेन डाटासेटमा आधारित)
डेटासेटहरू 1, 3 र 4 प्रत्येक वर्गीकरण मोडेललाई तालिम दिन प्रयोग गरियो, जसको परिणामस्वरूप 12 (3 x 4) प्रशिक्षित मोडेलहरू। SAS पछि प्रत्येक मोडेलले ग्राहक मन्थनको भविष्यवाणी गर्ने सटीकता मापन गर्न होल्डआउट डाटासेट प्रयोग गर्यो। नतिजाहरू तल प्रस्तुत गरिएका छन्, केही आधारभूत तथ्याङ्कहरूबाट सुरु हुँदै।
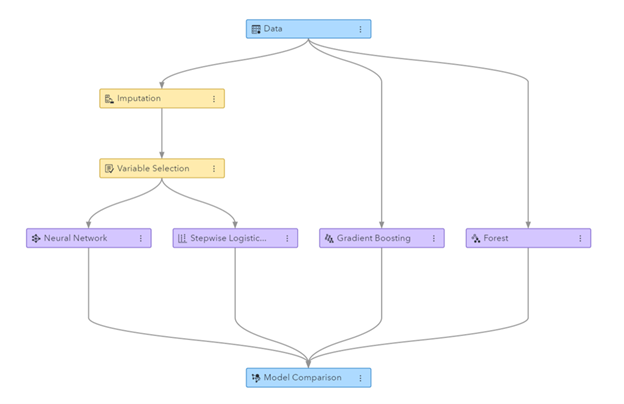
चित्र: SAS भिजुअल डाटा माइनिङ र मेसिन लर्निङमा उत्पन्न मेसिन लर्निङ पाइपलाइन
मौलिक डेटासँग अज्ञात डेटा तुलना गर्दा आधारभूत तथ्याङ्कहरू
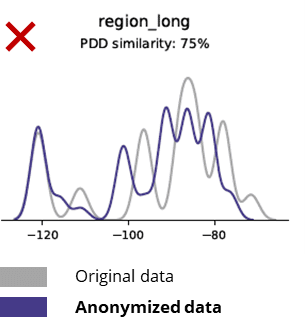
बेनामी प्रविधिहरूले आधारभूत ढाँचाहरू, व्यापार तर्कहरू, सम्बन्धहरू र तथ्याङ्कहरूलाई पनि नष्ट गर्दछ (तलको उदाहरणमा)। आधारभूत एनालिटिक्सका लागि गुमनाम डाटा प्रयोग गर्दा अविश्वसनीय परिणामहरू उत्पादन गर्दछ। वास्तवमा, अज्ञात डेटाको खराब गुणस्तरले यसलाई उन्नत विश्लेषण कार्यहरू (जस्तै AI/ML मोडलिङ र ड्यासबोर्डिङ) को लागि प्रयोग गर्न लगभग असम्भव बनायो।
मौलिक डाटासँग सिंथेटिक डाटा तुलना गर्दा आधारभूत तथ्याङ्कहरू
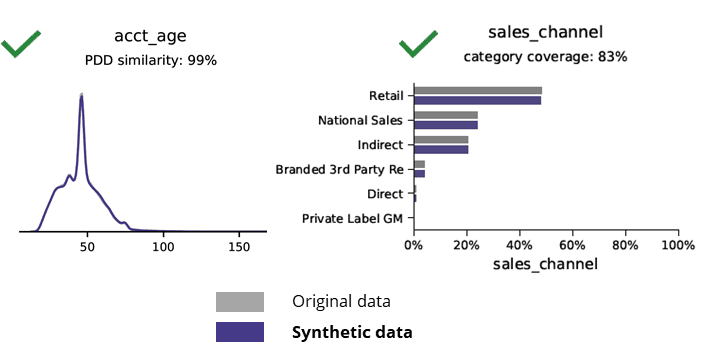
AI सँग सिंथेटिक डेटा उत्पादनले आधारभूत ढाँचा, व्यापार तर्क, सम्बन्ध र तथ्याङ्कहरू (तलको उदाहरणमा) सुरक्षित गर्दछ। आधारभूत एनालिटिक्सका लागि सिंथेटिक डाटा प्रयोग गर्दा भरपर्दो नतिजाहरू उत्पादन हुन्छ। मुख्य प्रश्न, उन्नत विश्लेषण कार्यहरू (जस्तै AI/ML मोडलिङ र ड्यासबोर्डिङ) को लागि सिंथेटिक डेटा होल्ड गर्छ?
AI-उत्पन्न सिंथेटिक डाटा र उन्नत विश्लेषण
सिंथेटिक डेटाले आधारभूत ढाँचाहरूको लागि मात्र होइन (पहिलेका प्लटहरूमा देखाइएको जस्तै), यसले उन्नत विश्लेषण कार्यहरूको लागि आवश्यक गहिरो 'लुकेका' सांख्यिकीय ढाँचाहरू पनि क्याप्चर गर्दछ। पछिल्लो तलको बार चार्टमा प्रदर्शन गरिएको छ, यसले संकेत गर्दछ कि सिंथेटिक डेटामा प्रशिक्षित मोडेलहरूको शुद्धता र मौलिक डेटामा प्रशिक्षित मोडेलहरू समान छन्। यसबाहेक, कर्भ (AUC*) मुनिको क्षेत्र ०.५ को नजिक भएकोमा, अज्ञात डेटामा प्रशिक्षित मोडेलहरूले सबैभन्दा खराब प्रदर्शन गर्छन्। सिंथेटिक डाटामा मौलिक डाटाको तुलनामा सबै उन्नत विश्लेषणात्मक मूल्याङ्कनहरूको साथ पूर्ण रिपोर्ट अनुरोधमा उपलब्ध छ।
*AUC: कर्भ मुनिको क्षेत्र भनेको साँचो सकारात्मक, गलत सकारात्मक, गलत नकारात्मक र साँचो नकारात्मकहरूलाई ध्यानमा राखेर उन्नत विश्लेषण मोडेलहरूको शुद्धताको मापन हो। 0,5 को अर्थ हो कि मोडेलले अनियमित रूपमा भविष्यवाणी गर्दछ र कुनै भविष्यवाणी गर्ने शक्ति छैन र 1 को मतलब यो हो कि मोडेल सधैं सही छ र पूर्ण भविष्यवाणी शक्ति छ।
थप रूपमा, यो सिंथेटिक डाटा डाटा विशेषताहरू र मोडेलहरूको वास्तविक प्रशिक्षणको लागि आवश्यक मुख्य चरहरू बुझ्न प्रयोग गर्न सकिन्छ। मूल डाटाको तुलनामा सिंथेटिक डाटामा एल्गोरिदमहरू द्वारा चयन गरिएका इनपुटहरू धेरै समान थिए। तसर्थ, मोडलिङ प्रक्रिया यस सिंथेटिक संस्करणमा गर्न सकिन्छ, जसले डाटा उल्लंघनको जोखिम कम गर्छ। यद्यपि, व्यक्तिगत रेकर्डहरू (जस्तै। टेलको ग्राहक) अनुमान गर्दा मूल डेटामा पुन: तालिमलाई स्पष्टीकरण, बढ्दो स्वीकृति वा नियमको कारणले सिफारिस गरिन्छ।
विधि द्वारा समूहबद्ध एल्गोरिदम द्वारा AUC
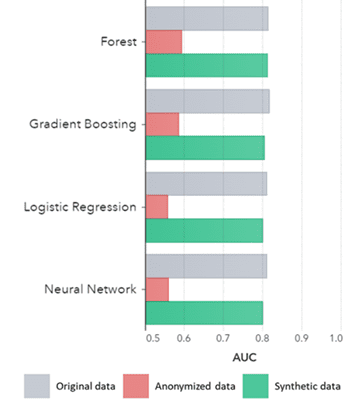
निष्कर्ष:
- मौलिक डेटामा प्रशिक्षित मोडेलहरूको तुलनामा सिंथेटिक डेटामा प्रशिक्षित मोडेलहरूले अत्यधिक समान प्रदर्शन देखाउँछन्
- 'क्लासिक एनोनिमाइजेसन टेक्निक' मार्फत अज्ञात डेटामा प्रशिक्षित मोडेलहरूले मौलिक डेटा वा सिंथेटिक डेटामा प्रशिक्षित मोडेलहरूको तुलनामा निम्न प्रदर्शन देखाउँछन्।
- सिंथेटिक डेटा उत्पादन सजिलो र छिटो छ किनभने प्रविधिले प्रति डेटासेट र प्रति डेटा प्रकार ठ्याक्कै समान काम गर्दछ।
मूल्य-थपना सिंथेटिक डेटा प्रयोग केसहरू
केस १ प्रयोग गर्नुहोस्: मोडेल विकास र उन्नत विश्लेषणका लागि सिंथेटिक डेटा
मोडेलहरू (जस्तै ड्यासबोर्डहरू [BI] र उन्नत एनालिटिक्स [AI र ML]) विकास गर्न प्रयोगयोग्य, उच्च गुणस्तरको डाटामा सजिलो र द्रुत पहुँचको साथ बलियो डाटा फाउन्डेशन हुनु आवश्यक छ। जे होस्, धेरै संस्थाहरूले सबोप्टिमल डाटा फाउन्डेशनबाट ग्रस्त छन् जसको परिणामस्वरूप 3 प्रमुख चुनौतीहरू छन्:
- डाटा मा पहुँच प्राप्त गर्न उमेर (गोपनीयता) नियमहरु, आन्तरिक प्रक्रियाहरु वा डाटा silos को कारण ले लिन्छ
- क्लासिक एनोनिमाइजेसन प्रविधिहरूले डाटा नष्ट गर्छ, डाटालाई अब विश्लेषण र उन्नत विश्लेषणका लागि उपयुक्त हुँदैन (गार्बेज इन = गार्बेज आउट)
- अवस्थित समाधानहरू मापनयोग्य छैनन् किनभने तिनीहरू प्रति डेटासेट र प्रति डेटा प्रकार फरक तरिकाले काम गर्छन् र ठूला बहु-तालिका डेटाबेसहरू ह्यान्डल गर्न सक्दैनन्।
सिंथेटिक डेटा दृष्टिकोण: राम्रो-जस्तो-वास्तविक सिंथेटिक डेटाको साथ मोडेलहरू विकास गर्नुहोस्:
- तपाइँको डेवलपर्स को बाधा बिना, मूल डाटा को उपयोग लाई कम गर्नुहोस्
- व्यक्तिगत डेटा अनलक गर्नुहोस् र अधिक डेटा को लागी पहुँच छ जुन पहिले प्रतिबन्धित थियो (जस्तै गोपनीयता को कारण)
- सान्दर्भिक डाटा को लागी सजिलो र छिटो डाटा पहुँच
- स्केलेबल समाधान जुन प्रत्येक डाटासेट, डाटाटाइप र विशाल डाटाबेस को लागी उस्तै काम गर्दछ
यसले संगठनलाई डाटा अनलक गर्न र डाटा अवसरहरूको लाभ उठाउन प्रयोगयोग्य, उच्च गुणस्तरको डाटामा सजिलो र छिटो पहुँचको साथ बलियो डाटा फाउन्डेशन निर्माण गर्न अनुमति दिन्छ।
केस २ प्रयोग गर्नुहोस्: सफ्टवेयर परीक्षण, विकास र डेलिभरीको लागि स्मार्ट सिंथेटिक परीक्षण डाटा
अत्याधुनिक सफ्टवेयर समाधानहरू प्रदान गर्न उच्च गुणस्तर परीक्षण डाटाको साथ परीक्षण र विकास आवश्यक छ। मौलिक उत्पादन डेटा प्रयोग गर्दा स्पष्ट देखिन्छ, तर (गोपनीयता) नियमहरूको कारणले अनुमति छैन। वैकल्पिक Test Data Management (TDM) उपकरण परिचय "legacy-by-design"परीक्षण डाटा सही प्राप्त गर्न मा:
- उत्पादन डेटा प्रतिबिम्बित नगर्नुहोस् र व्यापार तर्क र सन्दर्भ अखण्डता संरक्षित छैन
- ढिलो र समय खपत गर्ने काम गर्नुहोस्
- म्यानुअल काम आवश्यक छ
सिंथेटिक डेटा दृष्टिकोण: AI-उत्पन्न सिंथेटिक परीक्षण डाटाको साथ परीक्षण गर्नुहोस् र विकास गर्नुहोस् अत्याधुनिक सफ्टवेयर समाधानहरू स्मार्ट प्रदान गर्न:
- संरक्षित व्यापार तर्क र सन्दर्भ अखण्डता संग उत्पादन जस्तै डाटा
- अत्याधुनिक एआई संग सजिलो र छिटो डाटा उत्पादन
- गोपनीयता-द्वारा-डिजाइन
- सजिलो, छिटो र agile
यसले संगठनलाई अत्याधुनिक सफ्टवेयर समाधानहरू डेलिभर गर्न अर्को-स्तर परीक्षण डेटाको साथ परीक्षण र विकास गर्न अनुमति दिन्छ!
थप जानकारी
रुचि छ? सिंथेटिक डाटा बारे थप जानकारीको लागि, सिन्थो वेबसाइटमा जानुहोस् वा Wim Kees Janssen लाई सम्पर्क गर्नुहोस्। SAS को बारेमा थप जानकारीको लागि, भ्रमण गर्नुहोस् www.sas.com वा kees@syntho.ai मा सम्पर्क गर्नुहोस्।
यस प्रयोगको अवस्थामा, Syntho, SAS र NL AIC ले अपेक्षित परिणामहरू प्राप्त गर्न सँगै काम गर्छन्। Syntho AI-उत्पन्न सिंथेटिक डेटा मा एक विशेषज्ञ हो र SAS विश्लेषण मा एक बजार नेता हो र डेटा को अन्वेषण, विश्लेषण र दृश्य को लागी सफ्टवेयर प्रदान गर्दछ।
* २०२१ को भविष्यवाणी गर्दछ - डाटा र एनालिटिक्स रणनीतिहरू गभर्न, स्केल र ट्रान्सफर्म डिजिटल बिजनेस, गार्टनर, २०२०।

अब आफ्नो सिंथेटिक डाटा गाइड बचत गर्नुहोस्!
- सिंथेटिक डाटा के हो?
- संस्थाहरूले किन प्रयोग गर्छन्?
- सिंथेटिक डेटा क्लाइन्ट केसहरू थप्दै मूल्य
- कसरी सुरू गर्ने
