कोहो? अनुमान गर्नुहोस? 5 उदाहरणहरू किन नामहरू हटाउने विकल्प छैन



कोहो? अनुमान गर्नुहोस? जे होस् म पक्का छु कि तपाइँ मध्ये धेरै जसो दिन मा फिर्ता बाट यो खेल थाहा छ, यहाँ एक संक्षिप्त पुनरावृत्ति। खेल को लक्ष्य: 'हो' र 'छैन' प्रश्न सोधेर तपाइँको विरोधी द्वारा चयन कार्टून चरित्र को नाम पत्ता लगाउनुहोस्, जस्तै 'व्यक्ति टोपी लगाउँछ?' वा 'व्यक्ति चश्मा लगाउँछ'? खेलाडीहरु प्रतिद्वंद्वी को प्रतिक्रिया को आधार मा उम्मेदवारहरु लाई हटाउन र आफ्नो प्रतिद्वंद्वी को रहस्य चरित्र संग सम्बन्धित विशेषताहरु जान्न। पहिलो खेलाडी जो अन्य खेलाडी को रहस्य चरित्र बाहिर आंकडा खेल जित्छ।
तपाइले बुझ्नुभयाे। एक मात्र सम्बन्धित विशेषताहरु को लागी उपयोग गरेर एक डाटासेट को बाहिर व्यक्तिगत पहिचान गर्नु पर्छ। वास्तव मा, हामी नियमित रूप बाट अनुमान को अभ्यास मा लागू जो को अवधारणा देख्छौं, तर तब प people्क्तिहरु र स्तम्भहरु संग वास्तविक मान्छे को विशेषताहरु संग स्वरूपित डाटासेट मा कार्यरत। डाटा संग काम गर्दा मुख्य भिन्नता यो हो कि मानिसहरु सजीलो लाई कम गर्न को लागी हुन्छन् जसको द्वारा वास्तविक व्यक्तिहरु लाई मात्र केहि विशेषताहरु को लागी पहुँच बाट अनमास्क गर्न सकिन्छ।
अनुमान को रूप मा खेल को चित्रण गर्दछ, कोहि व्यक्तिहरु लाई मात्र केहि विशेषताहरु को लागी उपयोग गरेर व्यक्तिहरुको पहिचान गर्न सक्छन्। यो तपाइँको डेटासेट बाट मात्र 'नाम' (वा अन्य प्रत्यक्ष पहिचानकर्ताहरु) लाई हटाउने को एक बेनामीकरण प्रविधिको रूपमा असफल हुन्छ को एक साधारण उदाहरण को रूप मा कार्य गर्दछ। यो ब्लग मा, हामी डेटा व्यावहारिकरण को एक साधन को रूप मा स्तम्भहरु को हटाउने संग सम्बन्धित गोपनीयता जोखिम को बारे मा सूचित गर्न को लागी चार व्यावहारिक मामलाहरु प्रदान गर्दछौं।
एक लिंकेज हमला को जोखिम सबैभन्दा महत्त्वपूर्ण कारण हो कि मात्र नामहरु लाई हटाउन को लागी गुमनाम को लागी एक तरीका को रूप मा (अब) काम गर्दैन। एक लिंकेज हमला संग, हमलावर मूल रूप बाट अन्य सुलभ डाटा स्रोतहरु संग संयोजन को क्रम मा अद्वितीय रूप मा एक व्यक्ति को पहिचान र जान्न को लागी (अक्सर संवेदनशील) यो व्यक्ति को बारे मा जानकारी सिक्छ।
यहाँ कुञ्जी अन्य डाटा संसाधनहरु को उपलब्धता हो कि वर्तमान मा उपलब्ध छ, वा भविष्य मा वर्तमान हुन सक्छ। आफ्नो बारेमा सोच्नुहोस्। तपाइँको आफ्नै व्यक्तिगत डाटा को कति फेसबुक, इन्स्टाग्राम वा LinkedIn मा पाउन सकिन्छ कि सम्भावित एक लि attack्क हमला को लागी दुर्व्यवहार गर्न सकिन्छ?
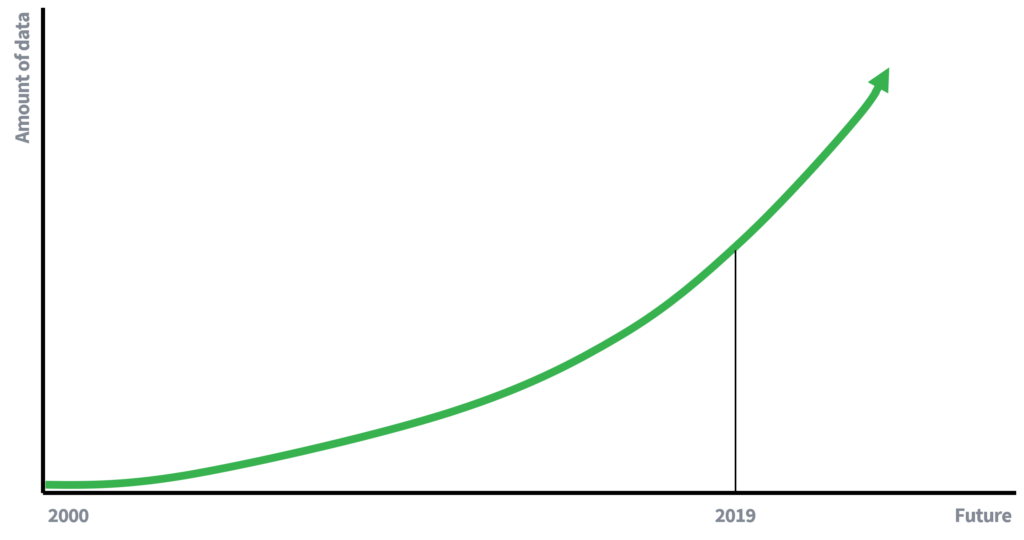
अघिल्लो दिनहरुमा, डाटा को उपलब्धता धेरै धेरै सीमित थियो, जो आंशिक रूप बाट बताउँछ कि नाम को हटाउन को लागी व्यक्तिको गोपनीयता को संरक्षण को लागी पर्याप्त थियो। कम उपलब्ध डाटा डाटा लिinking्क को लागी कम अवसर को मतलब। जे होस्, हामी अब एक डाटा संचालित अर्थव्यवस्था मा (सक्रिय) सहभागी हौं, जहाँ डाटा को मात्रा एक घातीय दर मा बढ्दै छ। अधिक डाटा, र डाटा स gathering्कलन को लागी टेक्नोलोजी सुधार लिंकेज हमलाहरु को लागी बृद्धि क्षमता को लागी नेतृत्व गर्दछ। एक 10 बर्ष मा एक लि attack्क हमला को जोखिम को बारे मा के लेख्ने?
चित्रण 1
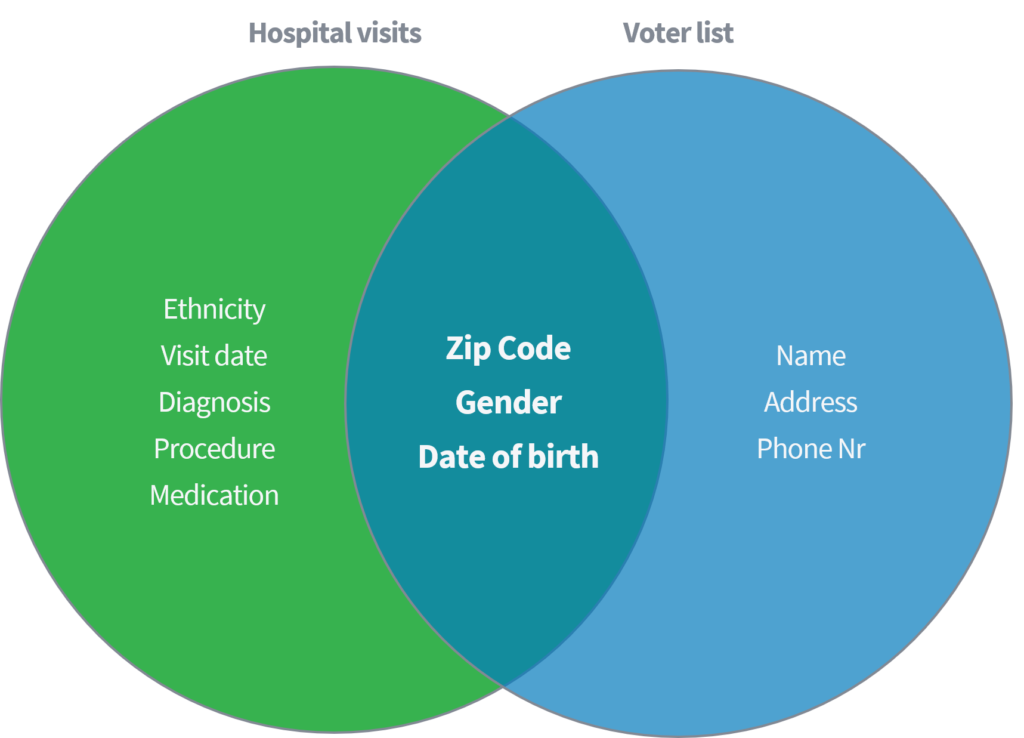
Sweeney (२००२) एक शैक्षिक कागज मा प्रदर्शन गरीरहेकी थिइन् कि उनी कसरी संयुक्त राज्य अमेरिका मा सार्वजनिक रुपमा उपलब्ध भोटि regist रजिस्ट्रार संग 'अस्पताल भ्रमण' को एक सार्वजनिक उपलब्ध डाटा सेट को लिंक को आधार मा व्यक्तिहरु बाट संवेदनशील मेडिकल डाटा को पहिचान र पुनः प्राप्त गर्न सक्षम थियो। दुबै डाटासेट जहाँ नाम र अन्य प्रत्यक्ष पहिचानकर्ताहरु को मेटाउने को माध्यम बाट ठीक संगै अज्ञात मानीन्छ।
चित्रण 2
केवल तीन मापदण्डहरु (१) जिप कोड, (२) लि and्ग र (३) जन्म मिति को आधारमा, उनले देखाए कि सम्पूर्ण अमेरिकी जनसंख्या को%% दुबै डाटासेट बाट उल्लेखित विशेषताहरु मिलान गरेर पुनः पहिचान गर्न सकिन्छ। Sweeney त्यसपछि 'जिप कोड' को विकल्प को रूप मा 'देश' संग आफ्नो काम दोहोर्यायो। यसबाहेक, उनले प्रदर्शन गरे कि सम्पूर्ण अमेरिकी जनसंख्या को १%% मात्र पहिचान गर्न सकिन्छ (१) गृह देश, (२) लिंग र (३) जन्म मिति को बारे मा जानकारी भएको एक डाटासेट को उपयोग गरेर। Facebook, LinkedIn वा Instagram जस्तै aforementioned सार्वजनिक स्रोतहरु को बारे मा सोच्नुहोस्। के तपाइँको देश, लि gender्ग र जन्म मिति देखिने छ, वा अन्य प्रयोगकर्ताहरु यसलाई कटौती गर्न सक्षम छन्?
चित्रण 3
| अर्ध-पहिचानकर्ता | % संयुक्त राज्य को जनसंख्या को विशिष्ट पहिचान (२248 मिलियन) |
| ५ अंकको जिप, लिंग, जन्म मिति | 87% |
| ठाउँ, लिंग, जन्म मिति | 53% |
| देश, लिंग, जन्म मिति | 18% |
यो उदाहरण देखाउँछ कि यो उल्लेखनीय सजीलो बेनामी डाटा मा व्यक्तिहरु de- गुमनाम गर्न को लागी सजीलो हुन सक्छ। पहिलो, यो अध्ययन जोखिम को एक विशाल परिमाण, को रूप मा संकेत गर्दछ अमेरिका को जनसंख्या को%% सजीलै प्रयोग गरी पहिचान गर्न सकिन्छ केहि विशेषताहरु। दोस्रो, यस अध्ययन मा उजागर मेडिकल डाटा अत्यधिक संवेदनशील थियो। अस्पताल भ्रमण डाटासेट बाट उजागर व्यक्तिहरु को डेटा को उदाहरण जातीयता, निदान र औषधि शामिल छन्। विशेषताहरु कि एक बरु गोप्य राख्न सक्छ, उदाहरण को लागी, बीमा कम्पनीहरु बाट।
मात्र प्रत्यक्ष पहिचानकर्ताहरु लाई हटाउन को लागी अर्को जोखिम, जस्तै नाम, तब उत्पन्न हुन्छ जब सूचित व्यक्तिहरु लाई उच्च ज्ञान वा डाटासेट मा विशिष्ट व्यक्तिको व्यवहार वा व्यवहार को बारे मा जानकारी छ।। उनीहरुको ज्ञानको आधारमा, हमलावर तब वास्तविक व्यक्तिहरु लाई विशिष्ट डाटा रेकर्ड लिंक गर्न सक्षम हुन सक्छ।
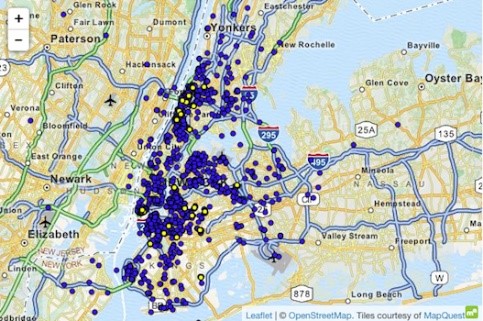
उच्च ज्ञान को उपयोग गरेर एक डाटासेट मा एक हमला को एक उदाहरण न्यूयोर्क ट्याक्सी मामला हो, जहाँ Atockar (2014) विशिष्ट व्यक्तिहरु लाई मुखौटा गर्न सक्षम थियो। नियोजित डाटासेट न्यूयोर्क मा सबै ट्याक्सी यात्रा, शुरू निर्देशांक, अन्त निर्देशांक, मूल्य र सवारी को टिप जस्तै आधारभूत विशेषताहरु संग समृद्ध निहित।
एक सूचित व्यक्ति जो न्यूयोर्क जान्दछ वयस्क क्लब 'हसलर' को लागी ट्याक्सी यात्राहरु प्राप्त गर्न सक्षम थियो। 'अन्त्य स्थान' फिल्टर गरेर, उहाँले सटीक सुरु ठेगाना deduced र यस प्रकार विभिन्न लगातार आगन्तुकहरुको पहिचान। त्यसै गरी, एक व्यक्ति को घर को ठेगाना थाहा थियो जब एक ट्याक्सी सवारी घटाउन सक्छ। समय र धेरै सेलिब्रिटी चलचित्र ताराहरु को गपशप साइटहरु मा खोजिएको थियो। यो जानकारी NYC ट्याक्सी डाटा लाई लिंक गरे पछि, यो उनीहरुको ट्याक्सी सवारी, उनीहरुले तिरेको रकम, र उनीहरु टिपिएको थियो कि प्राप्त गर्न सजिलो थियो।
चित्रण 4
ड्रप बन्द निर्देशक हस्टलर
ब्राडली कोपर
जेसिका अल्बा
तर्क को एक सामान्य लाइन 'यो डाटा बेकार छ' वा 'कोहि पनि यो डाटा संग केहि गर्न सक्दैन'। यो अक्सर एक गलत धारणा हो। यहाँ सम्म कि सबैभन्दा निर्दोष डाटा एक अद्वितीय 'फिंगरप्रिन्ट' बनाउन र व्यक्तिहरु लाई पुनः पहिचान गर्न को लागी प्रयोग गर्न सकिन्छ। यो डाटा बाट व्यर्थ छ भन्ने विश्वास बाट व्युत्पन्न जोखिम हो, जबकि यो छैन।
पहिचान को जोखिम डाटा, एआई, र अन्य उपकरण र एल्गोरिदम को बृद्धि संगै बृद्धि हुनेछ जुन डाटा मा जटिल सम्बन्ध को उजागर गर्न को लागी सक्षम छ। फलस्वरूप, भले ही तपाइँको डाटासेट अब खुला गर्न सकिदैन, र सम्भवतः आज अनधिकृत व्यक्तिहरु को लागी बेकार छ, यो भोलि नहुन सक्छ।
एक महान उदाहरण को मामला हो जहाँ Netflix एक खुला Netflix प्रतियोगिता शुरू गरेर आफ्नो फिल्म सिफारिश प्रणाली लाई सुधार गर्न को लागी यसको आर एन्ड डी विभाग क्राउडसोर्स गर्न को लागी। 'एक जसले फिल्टर को लागी प्रयोगकर्ता रेटिंग को भविष्यवाणी गर्न को लागी सहयोगी फिल्टरिंग एल्गोरिदम मा सुधार गर्दछ US $ १,००,००० को पुरस्कार जीते'। क्रम मा भीड को समर्थन गर्न को लागी, Netflix एक डाटासेट प्रकाशित मात्र निम्न आधारभूत विशेषताहरु युक्त: userID, चलचित्र, ग्रेड र ग्रेड को मिति (त्यसैले प्रयोगकर्ता वा फिल्म मा कुनै थप जानकारी)।
चित्रण 5
| प्रयोगकर्ता ID | चलचित्र | ग्रेड को मिति | ग्रेड |
| 123456789 | असम्भव मिशन | 10-12-2008 | 4 |
अलगाव मा, डाटा व्यर्थ देखा पर्यो। जब प्रश्न सोध्न 'त्यहाँ डाटासेट मा कुनै ग्राहक जानकारी छ कि निजी राख्नु पर्छ?', जवाफ थियो:
'होइन, सबै ग्राहक पहिचान जानकारी हटाइएको छ; सबै बाँकी छ कि रेटिंग र मितिहरु छन्। यो हाम्रो गोपनीयता नीति पछ्याउँछ ... '
जे होस्, नारायणन (२००)) अस्टिन मा टेक्सास विश्वविद्यालय बाट अन्यथा साबित भयो। ग्रेड, ग्रेड र एक व्यक्तिको फिल्म को मिति को संयोजन एक अद्वितीय चलचित्र फिंगरप्रिन्ट रूपहरु। तपाइँको आफ्नै Netflix व्यवहार को बारे मा सोच्नुहोस्। कती मानिसहरु लाई लाग्छ कि फिल्महरुको एउटै सेट हेर्नुभयो? कति जना एकै समयमा फिल्महरु को एउटै सेट हेर्नुभयो?
मुख्य प्रश्न, कसरी यो फिंगरप्रिन्ट मेल खाने? यो बरु सरल थियो। प्रसिद्ध फिल्म रेटिंग वेबसाइट IMDb (इन्टरनेट चलचित्र डाटाबेस) बाट जानकारी को आधार मा, एक समान फिंगरप्रिन्ट गठन गर्न सकिन्छ। फलस्वरूप, व्यक्तिहरु लाई पुनः पहिचान गर्न सकिन्छ।
जबकि फिल्म हेर्ने व्यवहार संवेदनशील जानकारी को रूप मा अनुमान नहुन सक्छ, तपाइँको आफ्नै व्यवहार को बारे मा सोच्नुहोस्-के तपाइँ दिमाग गर्नुहुन्छ यदि यो सार्वजनिक भयो? उदाहरणहरु कि नारायणन आफ्नो कागज मा प्रदान गरीयो राजनीतिक प्राथमिकताहरु ('नासरत को येशू' र 'जॉन को सुसमाचार' मा रेटिंग) र यौन प्राथमिकताहरु ('बेंट' र 'लोक को रूप मा क्वियर') सजीलै आसुत गर्न सकिन्छ।
GDPR सुपर रोमाञ्चक नहुन सक्छ, न त ब्लग बिषयहरु बीच चाँदी बुलेट। अझै पनी, यो सीधा परिभाषा प्राप्त गर्न को लागी उपयोगी छ जब व्यक्तिगत डाटा प्रशोधन। चूंकि यो ब्लग डाटा बेनामी गर्न को लागी एक तरीका को रूप मा स्तम्भहरु लाई हटाउने र डाटा प्रोसेसर को रूप मा तपाइँलाई शिक्षित गर्न को लागी सामान्य गलत धारणा को बारे मा छ, हामी GDPR अनुसार बेनामीकरण को परिभाषा को अन्वेषण संग शुरू गरौं।
GDPR बाट पाठ 26 को अनुसार, अज्ञात जानकारी को रूप मा परिभाषित गरीएको छ:
'जानकारी जो एक पहिचान वा पहिचान योग्य प्राकृतिक व्यक्ति वा व्यक्तिगत डाटा संग बेनामी प्रदान गरीएको छ कि डाटा विषय छैन वा अब पहिचान योग्य छैन।
चूंकि एक व्यक्तिगत डेटा को प्रक्रिया गर्दछ कि एक प्राकृतिक व्यक्ति संग सम्बन्धित छ, केवल परिभाषा को भाग २ प्रासंगिक छ। आदेश को परिभाषा को पालना गर्न को लागी, एक सुनिश्चित गर्न को लागी डाटा विषय (व्यक्तिगत) छैन वा अब पहिचान योग्य छैन। यस ब्लग मा संकेत गरीएको छ, जे होस्, यो उल्लेखनीय सरल छ केहि विशेषताहरु मा आधारित व्यक्तिहरुको पहिचान गर्न। त्यसोभए, एक डाटासेट बाट नामहरु हटाउने गुमनामीकरण को GDPR परिभाषा को अनुपालन गर्दैन।
हामीले एउटा सामान्य रुपमा मानीएको चुनौती, र दुर्भाग्यवश, अझै पनी बारम्बार डाटा बेनामीकरण को दृष्टिकोण लागू: नामहरु हटाउने। अनुमान को खेल मा र चार अन्य उदाहरण को बारे मा:
यो देखाइएको थियो कि नाम हटाउन को लागी बेनामीकरण को रूप मा विफल हुन्छ। जे होस् उदाहरण हडताल मामलाहरु छन्, प्रत्येक पुन: पहिचान को सादगी देखाउँछ र व्यक्तिको गोपनीयता मा सम्भावित नकारात्मक प्रभाव।
अन्त्यमा, तपाइँको डाटासेट बाट नामहरु को हटाउने बेनामी डाटा मा परिणाम छैन। तेसैले, हामी राम्रो संग दुबै शब्दहरु एक अर्का को उपयोग बाट बच्न। म ईमानदारी बाट आशा गर्दछु कि तपाइँ गुमनाम को लागी यो दृष्टिकोण लागू गर्नुहुन्न। र, यदि तपाइँ अझै पनी गर्नुहुन्छ, सुनिश्चित गर्नुहोस् कि तपाइँ र तपाइँको टीम गोपनीयता जोखिमहरु लाई पुरा तरिकाले बुझ्नुहुन्छ, र प्रभावित व्यक्तिहरु को तर्फ बाट ती जोखिमहरु लाई स्वीकार गर्न को लागी अनुमति छ।
Syntho लाई सम्पर्क गर्नुहोस् र हाम्रा विशेषज्ञहरू मध्ये एकले सिंथेटिक डाटाको मूल्य अन्वेषण गर्न प्रकाशको गतिमा तपाईंसँग सम्पर्कमा आउनेछन्!