Што такое тэставыя даныя: значэнне, прымяненне і праблемы
Змест
Што такое тэставыя дадзеныя ў тэсціраванні праграмнага забеспячэння?
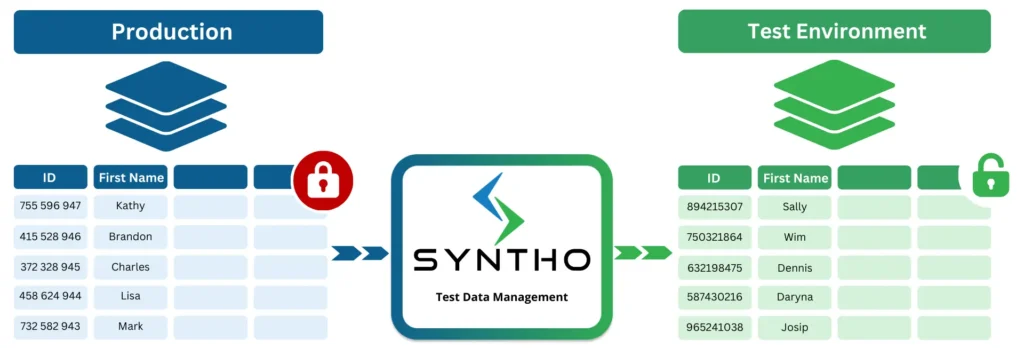
Прасцей кажучы, вызначэнне тэставых дадзеных гэта: выбраны тэставыя даныя наборы дадзеных выкарыстоўваецца, каб знайсці недахопы і пераканацца, што праграмнае забеспячэнне працуе так, як яно павінна працаваць.
На што разлічваюць выпрабавальнікі і інжынеры тэставыя наборы дадзеных, незалежна ад таго, сабраныя ўручную або з дапамогай спецыялізаваных сродкі генерацыі тэставых даных, для праверкі функцыянальнасці праграмнага забеспячэння, ацэнкі прадукцыйнасці і павышэння бяспекі.
Пашыраючы гэтую канцэпцыю, што такое тэставыя дадзеныя ў тэставанні? За межамі простага наборы дадзеных, тэставыя даныя ўключаюць у сябе шэраг уваходных значэнняў, сцэнарыяў і ўмоў. Гэтыя элементы старанна адбіраюцца, каб праверыць, ці адпавядаюць вынікі строгім крытэрыям якасці і функцыянальнасці, якія чакаюцца ад праграмнага забеспячэння.
Каб лепш зразумець вызначэнне тэставых дадзеных, давайце вывучым розныя тыпы тэставых даных.
Якія бываюць тыпы тэставых даных?
У той час як асноўная мэта ст дадзеныя тэсціравання каб гарантаваць, што праграмнае забеспячэнне паводзіць сябе належным чынам, фактары, якія ўплываюць на прадукцыйнасць праграмнага забеспячэння, моцна адрозніваюцца. Гэтая зменлівасць азначае, што тэстары павінны выкарыстоўваць розныя тыпы даных для ацэнкі паводзін сістэмы ў розных умовах.
Такім чынам, давайце адкажам на гэтае пытанне -што такое тэставыя дадзеныя ў тэсціраванні праграмнага забеспячэння?—з прыкладамі.
- Станоўчыя дадзеныя тэстаў выкарыстоўваецца для тэсціравання праграмнага забеспячэння ў нармальных умовах працы, напрыклад, каб праверыць, ці спакойна едзе аўтамабіль па роўнай дарозе без перашкод.
- Адмоўныя дадзеныя тэстаў падобна на тэставанне прадукцыйнасці аўтамабіля з няспраўнасцю некаторых запасных частак. Гэта дапамагае вызначыць, як праграмнае забеспячэнне рэагуе на несапраўдныя дадзеныя ўваходы або перагрузка сістэмы.
- Тэставыя даныя класа эквівалентнасці дапамагае прадставіць паводзіны пэўнай групы або катэгорыі ў рамках праграмнага забеспячэння, каб праверыць, у прыватнасці, як праграмнае забеспячэнне апрацоўвае розныя тыпы карыстальнікаў або ўваходныя дадзеныя.
- Дадзеныя выпадковых тэстаў генеруецца без пэўнага шаблону. Гэта дапамагае праграмнаму забеспячэнню бесперашкодна апрацоўваць нечаканыя сітуацыі.
- Тэставыя даныя на аснове правілаў генеруецца ў адпаведнасці з загадзя вызначанымі правіламі або крытэрыямі. У банкаўскім дадатку гэта могуць быць дадзеныя аб транзакцыях, згенераваныя для таго, каб гарантаваць, што ўсе транзакцыі адпавядаюць пэўным нарматыўным патрабаванням або што рэшткі на рахунках застаюцца ў вызначаных межах.
- Дадзеныя межавых выпрабаванняў правярае, як праграмнае забеспячэнне кіруе значэннямі на крайніх канцах дапушчальных дыяпазонаў. Гэта падобна на тое, каб давесці нейкае абсталяванне да яго абсалютных межаў.
- Дадзеныя тэсту рэгрэсіі выкарыстоўваецца, каб праверыць, ці не выклікалі нядаўнія змены ў праграмным забеспячэнні новыя дэфекты або праблемы.
Выкарыстоўваючы гэтыя розныя тыпы тэставых даных, спецыялісты па забеспячэнні якасці могуць эфектыўна ацаніць, ці працуе праграмнае забеспячэнне належным чынам, выявіць любыя недахопы або памылкі і ў канчатковым выніку павысіць прадукцыйнасць сістэмы.
Але дзе каманды праграмнага забеспячэння могуць атрымаць гэтыя дадзеныя? Давайце абмяркуем гэта далей.
Як ствараюцца тэставыя даныя?
У вас ёсць наступныя тры варыянты стварыць тэставыя дадзеныя для вашага праекта:
- Вішнёвы выбар даных з існуючай базы даных, маскіруючы інфармацыю аб кліенце, напрыклад інфармацыю, якая дазваляе ідэнтыфікаваць асобу (PII).
- Стварыць уручную рэалістычныя тэставыя дадзеныя з праграмамі даных на аснове правілаў.
- Генераваць сінтэтычныя даныя.
Многія каманды інжынерных даных абапіраюцца толькі на адзін з падыходаў, занадта часта выбіраючы найбольш працаёмкі і працаёмкі метад генерацыя тэставых дадзеных. Напрыклад, пры пікіроўцы узор даных з існуючых баз даных, каманды інжынераў павінны спачатку атрымаць яго з некалькіх крыніц, затым адфарматаваць, ачысціць і замаскіраваць, каб зрабіць яго прыдатным для асяроддзя распрацоўкі або тэсціравання.
Яшчэ адна праблема заключаецца ў забеспячэнні таго, каб даныя адпавядалі пэўным крытэрам тэсціравання: дакладнасць, разнастайнасць, спецыфіка для канкрэтнага рашэння, высокая якасць і адпаведнасць правілам па абароне персанальных даных. Аднак гэтыя задачы эфектыўна вырашаюцца сучаснай test data management падыходы, такія як аўтаматызаванае стварэнне тэставых дадзеных.
Платформа Syntho прапануе шэраг магчымасцей для вырашэння гэтых задач, у тым ліку:
- Разумная дэідэнтыфікацыя, калі інструмент аўтаматычна ідэнтыфікуе ўсю ідэнтыфікацыйную інфармацыю, эканомячы час і намаганні экспертаў.
- Абыход канфідэнцыйнай інфармацыі шляхам замены ідэнтыфікацыйнай інфармацыі і іншых ідэнтыфікатараў на сінтэтычныя макет дадзеных што адпавядае бізнес-логіцы і шаблонам.
- Падтрыманне спасылачнай цэласнасці шляхам паслядоўнага адлюстравання даных у базах дадзеных і сістэмах.
Мы вывучым гэтыя магчымасці больш падрабязна. Але спачатку давайце паглыбімся ў пытанні, звязаныя з стварэнне тэставых дадзеных так што вы ведаеце пра іх і ведаеце, як з імі змагацца.
Задачы тэставых дадзеных пры тэсціраванні праграмнага забеспячэння
Sourcing сапраўдныя дадзеныя тэсту з'яўляецца краевугольным каменем эфектыўнага тэставання. Аднак каманды інжынераў сутыкаюцца з мноствам праблем на шляху да надзейнага праграмнага забеспячэння.
Разрозненыя крыніцы даных
Дадзеныя, асабліва карпаратыўныя, знаходзяцца ў мностве крыніц, у тым ліку састарэлых мэйнфрэймаў, SAP, рэляцыйных баз даных, NoSQL і розных воблачных асяроддзях. Гэтая дысперсія ў спалучэнні з шырокім дыяпазонам фарматаў ускладняе доступ да вытворчых дадзеных для каманд праграмнага забеспячэння. Гэта таксама запавольвае працэс атрымання патрэбных даных для тэставання і вынікаў несапраўдныя тэставыя дадзеныя.
Паднабор для фокусу
Інжынерныя групы часта змагаюцца з сегментаваннем вялікіх і разнастайных тэставых набораў даных на меншыя мэтавыя падмноствы. Але гэта неабходна зрабіць, бо гэты разрыў дапамагае ім засяродзіцца на канкрэтным тэсты, палягчаючы прайграванне і выпраўленне праблем, захоўваючы нізкі аб'ём тэставых даных і звязаныя з імі выдаткі.
Максімальны ахоп тэстам
Інжынеры таксама нясуць адказнасць за тое, каб даныя тэставання былі дастаткова поўнымі, каб правесці дбайнае тэставанне тэсты, звесці да мінімуму шчыльнасць дэфектаў і ўмацаваць надзейнасць праграмнага забеспячэння. Аднак у гэтых намаганнях яны сутыкаюцца з праблемамі з-за розных фактараў, такіх як складанасць сістэмы, абмежаваныя рэсурсы, змены ў праграмным забеспячэнні, канфідэнцыяльнасць і бяспека дадзеных, а таксама праблемы з маштабаванасцю.
Рэалізм у тэставых дадзеных
Імкненне да рэалістычнасці тэставых дадзеных паказвае, наколькі важна адлюстроўваць арыгінал значэння дадзеных з найвялікшай вернасцю. Тэставыя дадзеныя павінны быць вельмі падобныя на вытворчае асяроддзе, каб пазбегнуць ілжывых спрацоўванняў або адмоў. Калі гэтага рэалізму не дасягнуць, гэта можа пагоршыць якасць і надзейнасць праграмнага забеспячэння. Улічваючы гэта, спецыялісты павінны звярнуць пільную ўвагу на дэталі падрыхтаваць тэставыя дадзеныя.
Абнаўленне і абслугоўванне даных
Тэставыя даныя павінны рэгулярна абнаўляцца з улікам змяненняў у вытворчым асяроддзі і патрабаваннях прыкладанняў. Аднак гэтая задача звязана са значнымі праблемамі, асабліва ў асяроддзях, дзе доступ да даных абмежаваны з-за адпаведнасці нарматыўным патрабаванням. Каардынацыя цыклаў абнаўлення даных і забеспячэнне ўзгодненасці даных у асяроддзі тэсціравання становяцца складанымі задачамі, якія патрабуюць дбайнай каардынацыі і строгіх мер адпаведнасці.
Праблемы з рэальнымі дадзенымі тэстаў
Паводле апытання Syntho на LinkedIn, 50% кампаній выкарыстоўваюць вытворчыя дадзеныя, а 22% выкарыстоўваюць замаскіраваныя даныя, каб праверыць сваё праграмнае забеспячэнне. Яны выбіраюць фактычныя дадзеныя як здаецца, простае рашэнне: скапіяваць існуючыя дадзеныя з вытворчага асяроддзя, устаўце яго ў тэставае асяроддзе і выкарыстоўвайце пры неабходнасці.
Аднак выкарыстоўваючы рэал дадзеныя для тэставання прадстаўляе некалькі праблем, у тым ліку:
- Пазбягайце маскіроўкі даных у адпаведнасці з правіламі прыватнасці даных бяспеку дадзеных парушэнні і прытрымлівацца законаў, якія забараняюць выкарыстанне рэальных даных у мэтах тэсціравання.
- Падганянне дадзеных у тэставае асяроддзе, якое звычайна адрозніваецца ад вытворчага асяроддзя.
- Абнаўленне баз дастатковую рэгулярнасць.
У дадатак да гэтых праблем, кампаніі змагаюцца з трыма найважнейшымі праблемамі пры выбары рэальныя дадзеныя для тэставання.
Абмежаваная даступнасць
Абмежаваныя, дэфіцытныя або прапушчаныя даныя часта сустракаюцца, калі распрацоўшчыкі разглядаюць вытворчыя даныя як прыдатныя тэставыя дадзеныя. Атрымаць доступ да высакаякасных тэставых даных, асабліва для складаных сістэм або сцэнарыяў, становіцца ўсё цяжэй. Гэты дэфіцыт даных перашкаджае комплексным працэсам тэсціравання і праверкі, што робіць спробы тэсціравання праграмнага забеспячэння менш эфектыўнымі.
Пытанні захавання
Строгія законы аб канфідэнцыяльнасці даных, такія як CPRA і GDPR, патрабуюць абароны ідэнтыфікацыйнай інфармацыі ў тэставых асяроддзях, навязваючы строгія стандарты адпаведнасці санітарнай ачыстцы даных. У гэтым кантэксце ўлічваюцца сапраўдныя імёны, адрасы, нумары тэлефонаў і нумары сацыяльнага страхавання, знойдзеныя ў вытворчых дадзеных незаконныя фарматы дадзеных.
пытанні прыватнасці
Праблема адпаведнасці відавочная: выкарыстанне зыходных асабістых даных у якасці тэставых забаронена. Каб вырашыць гэтую праблему і пераканацца, што пры канструяванні не выкарыстоўваецца ідэнтыфікацыйная інфармацыя тэсты, тэстары павінны пераправерыць гэта канфідэнцыйныя дадзеныя дэзінфікуецца або ананімізуецца перад выкарыстаннем у тэставых асяроддзях. Пакуль крытычны для бяспеку дадзеных, гэтая задача адымае шмат часу і дадае яшчэ адзін узровень складанасці для каманд тэсціравання.
Важнасць даных тэставання якасці
Добрыя тэставыя дадзеныя служыць асновай усяго працэсу кантролю якасці. Гэта гарантыя таго, што праграмнае забеспячэнне працуе належным чынам, добра працуе ў розных умовах і застаецца ў бяспецы ад узлому даных і зламысных нападаў. Аднак ёсць яшчэ адна важная перавага.
Вы знаёмыя з тэставаннем зруху налева? Такі падыход прасоўвае тэсціраванне да ранніх этапаў жыццёвага цыкла распрацоўкі, каб не запаволіць agile працэс. Тэставанне пры націсканні зруху налева скарачае час і выдаткі, звязаныя з тэставаннем і адладкай пазней у цыкле, выяўляючы і выпраўляючы праблемы на ранняй стадыі.
Каб тэсціраванне зруху налева працавала добра, неабходныя сумяшчальныя наборы тэставых даных. Гэта дапамагае групам распрацоўшчыкаў і кантролю якасці старанна тэставаць канкрэтныя сцэнарыі. Аўтаматызацыя і ўпарадкаванне ручных працэсаў тут важныя. Вы можаце паскорыць падрыхтоўку і вырашыць большасць праблем, якія мы абмяркоўвалі, выкарыстоўваючы адпаведны тэст сродкі генерацыі даных з сінтэтычнымі дадзенымі.
Сінтэтычныя дадзеныя як рашэнне
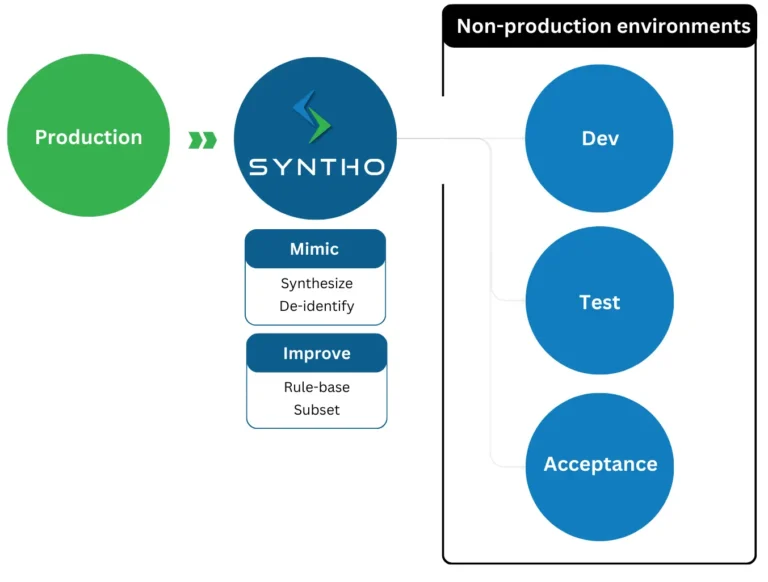
На аснове сінтэтычных даных test data management падыход гэта адносна новая, але эфектыўная стратэгія для падтрымання якасці пры вырашэнні праблем. Кампаніі могуць спадзявацца на стварэнне сінтэтычных даных для хуткага стварэння высакаякасных тэставых даных.
Азначэнне і характарыстыка
Сінтэтычныя тэставыя даныя - гэта штучна створаныя даныя, прызначаныя для мадэлявання асяроддзя тэсціравання даных для распрацоўкі праграмнага забеспячэння. Шляхам замены ідэнтыфікацыйнай інфармацыі фіктыўнымі данымі без канфідэнцыяльнай інфармацыі ствараюцца сінтэтычныя даныя test data management хутчэй і прасцей.
Сінтэтычныя тэставыя даныя зніжаюць рызыку канфідэнцыяльнасці, а таксама дазваляюць распрацоўшчыкам строга ацэньваць прадукцыйнасць, бяспеку і функцыянальнасць праграмы ў розных магчымых сцэнарыях, не ўплываючы на рэальную сістэму. Зараз давайце даведаемся, што яшчэ могуць зрабіць інструменты сінтэтычных даных.
Вырашыце праблемы адпаведнасці і прыватнасці
Давайце ў якасці прыкладу возьмем рашэнне Syntho. Для вырашэння праблем адпаведнасці і прыватнасці мы выкарыстоўваем складаныя маскіроўка дадзеных метады разам з самай сучаснай тэхналогіяй сканавання PII. Сканер ідэнтыфікацыйных звестак Syntho на базе штучнага інтэлекту аўтаматычна вызначае і пазначае любыя слупкі ў карыстальніцкіх базах дадзеных, якія змяшчаюць прамыя ідэнтыфікацыйныя даныя. Гэта скарачае ручную працу і забяспечвае дакладнае выяўленне канфідэнцыяльных даных, зніжаючы рызыку ўзлому даных і невыканання правілаў прыватнасці.
Пасля ідэнтыфікацыі слупкоў з ідэнтыфікацыйнай інфармацыяй платформа Syntho прапануе фіктыўныя даныя як лепшы метад дэідэнтыфікацыі ў гэтым выпадку. Гэта функцыя абараняе канфідэнцыйную арыгінальную ідэнтыфікацыйную інфармацыю, замяняючы яе рэпрэзентатыўнымі фіктыўнымі данымі, якія па-ранейшаму захоўваюць спасылачную цэласнасць для мэт тэсціравання ў базах даных і сістэмах. Гэта дасягаецца за кошт паслядоўная функцыя адлюстравання, які гарантуе, што падстаўленыя даныя адпавядаюць бізнес-логіцы і шаблонам, выконваючы такія правілы, як GDPR і HIPAA.
Забяспечце ўніверсальнасць тэсціравання
Разнастайныя даныя тэсціравання могуць дапамагчы кампаніям пераадолець праблему абмежаванай даступнасці даных і павялічыць ахоп тэстамі. Платформа Syntho падтрымлівае ўніверсальнасць сваёй генерацыя сінтэтычных даных на аснове правілаў.
Гэта паняцце прадугледжвае стварэнне тэставых дадзеных прытрымліваючыся наканаваных правілаў і абмежаванняў, каб імітаваць рэальныя дадзеныя або мадэляваць пэўныя сцэнары. Генерацыя сінтэтычных даных на аснове правілаў забяспечвае ўніверсальнасць тэсціравання з дапамогай розных стратэгій:
- Стварэнне дадзеных з нуля: Сінтэтычныя даныя на аснове правілаў дазваляюць ствараць даныя, калі рэальныя даныя абмежаваныя або адсутнічаюць. Гэта забяспечвае тэстараў і распрацоўшчыкаў неабходнымі дадзенымі.
- Узбагачэнне дадзеных: Гэта ўзбагачае даныя, дадаючы больш радкоў і слупкоў, палягчаючы стварэнне вялікіх набораў даных.
- Гнуткасць і налада: Дзякуючы падыходу, заснаванаму на правілах, мы можам заставацца гнуткімі і адаптавацца да розных фарматаў і структур даных, ствараючы сінтэтычныя даныя, адаптаваныя да канкрэтных патрэб і сцэнарыяў.
- Ачыстка дадзеных: Гэта прадугледжвае прытрымліванне загадзя вызначаным правілам пры стварэнні даных для выпраўлення неадпаведнасцяў, запаўнення прапушчаных значэнняў і выдалення пашкоджаныя тэставыя дадзеныя. Гэта забяспечвае якасць дадзеных і цэласнасць, асабліва важная, калі зыходны набор даных змяшчае недакладнасці, якія могуць паўплываць на вынікі тэставання.
Пры выбары правільнага інструменты генерацыі даных, вельмі важна ўлічваць некаторыя фактары, каб пераканацца, што яны сапраўды палягчаюць нагрузку для вашых каманд.
Меркаванні пры выбары інструментаў сінтэтычных дадзеных
Выбар інструментаў для сінтэтычных даных залежыць ад вашых бізнес-патрэбаў, магчымасцей інтэграцыі і патрабаванняў да прыватнасці даных. Хоць кожная арганізацыя ўнікальная, мы акрэслілі ключавыя крытэрыі выбару сінтэтыкі сродкі генерацыі даных.
Рэалістычнасць дадзеных
Пераканайцеся, што інструмент вы лічыце генеруе тэставыя дадзеныя вельмі падобныя на рэальныя дадзеныя. Толькі тады ён будзе эфектыўна мадэляваць розныя тэставыя сцэнары і выяўляць магчымыя праблемы. Інструмент таксама павінен прапаноўваць параметры наладкі для імітацыі розных размеркаванняў даных, шаблонаў і анамалій у вытворчых асяроддзях.
Разнастайнасць дадзеных
Шукайце інструменты, якія могуць ствараць узор даных які ахоплівае шырокі дыяпазон варыянтаў выкарыстання, уключаючы розныя тыпы даных, фарматы і структуры, якія адносяцца да тэсціруемага праграмнага забеспячэння. Гэта разнастайнасць дапамагае праверыць, ці з'яўляецца сістэма надзейнай, і забяспечвае поўнае ахоп тэстаў.
Маштабаванасць і прадукцыйнасць
Праверце, наколькі добра інструмент можа ствараць вялікія аб'ёмы сінтэтычных даных, асабліва для тэсціравання складаных або вялікіх аб'ёмаў сістэм. Вы хочаце інструмент, які можна маштабаваць, каб задаволіць патрабаванні да даных для карпаратыўных праграм без шкоды для прадукцыйнасці або надзейнасці.
Канфідэнцыяльнасць і бяспека дадзеных
Аддавайце прыярытэт інструментам з убудаванымі функцыямі для абароны канфідэнцыйнай або канфідэнцыйнай інфармацыі пры стварэнні даных. Звярніце ўвагу на такія функцыі, як ананімізацыя даных і захаванне правілаў абароны даных, каб мінімізаваць рызыку прыватнасці і выконваць закон.
Інтэграцыя і сумяшчальнасць
Выбірайце праграмнае забеспячэнне, якое цалкам адпавядае вашай існуючай наладзе тэсціравання, каб палегчыць прыняцце і інтэграцыю ў працоўны працэс распрацоўкі праграмнага забеспячэння. Інструмент, які сумяшчальны з рознымі сістэмамі захоўвання даных, базамі даных і платформамі тэсціравання, будзе больш універсальным і простым у выкарыстанні.
Напрыклад, Падтрымлівае Syntho 20+ злучальнікаў баз дадзеных і 5+ злучальнікаў файлавых сістэм, уключаючы такія папулярныя варыянты, як Microsoft SQL Server, Amazon S3 і Oracle, якія забяспечваюць бяспеку даных і лёгкае стварэнне даных.
Налада і гнуткасць
Шукайце інструменты, якія прапануюць гнуткія варыянты наладкі для адаптацыі генерацыі сінтэтычных даных да канкрэтных патрабаванняў і сцэнарыяў тэсціравання. Наладжвальныя параметры, такія як правілы генерацыі даных, адносіны і абмежаванні, дазваляюць дакладна наладзіць згенераваныя даныя ў адпаведнасці з крытэрыямі і мэтамі тэставання.
Падсумоўваць
,en значэнне тэставых дадзеных у распрацоўцы праграмнага забеспячэння немагчыма пераацаніць - гэта тое, што дапамагае нам выяўляць і выпраўляць недахопы ў функцыянальнасці праграмнага забеспячэння. Але кіраванне тэставымі дадзенымі - гэта не проста пытанне зручнасці; гэта вельмі важна для выканання правілаў і правілаў прыватнасці. Правільнае выкананне можа палегчыць нагрузку на вашыя каманды распрацоўшчыкаў, зэканоміць грошы і хутчэй вывесці прадукты на рынак.
Вось дзе сінтэтычныя дадзеныя прыходзяць на карысць. Ён забяспечвае рэалістычныя і разнастайныя даныя без занадта шмат працаёмкай працы, забяспечваючы адпаведнасць і бяспеку кампаній. З інструментамі генерацыі сінтэтычных даных кіраванне тэставымі дадзенымі становіцца больш хуткім і эфектыўным.
Лепшая частка заключаецца ў тым, што якасныя сінтэтычныя тэставыя дадзеныя даступныя кожнай кампаніі, незалежна ад яе мэтаў. Усё, што вам трэба зрабіць, гэта знайсці надзейнага пастаўшчыка інструментаў генерацыі сінтэтычных даных. Звяжыцеся з Syntho сёння і забраніраваць бясплатную дэма-версію каб убачыць, як сінтэтычныя дадзеныя могуць прынесці карысць вашаму тэсціраванню праграмнага забеспячэння.
Аб аўтарах

Галоўны дырэктар па прадуктах і сузаснавальнік
Марыйн мае акадэмічную адукацыю ў галіне інфарматыкі, прамысловага будаўніцтва і фінансаў, і з таго часу выдатна працуе ў галіне распрацоўкі праграмнага забеспячэння, аналітыкі даных і кібербяспекі. Мэрын цяпер выконвае абавязкі заснавальніка і галоўнага дырэктара па прадуктах (CPO) у Syntho, прасоўваючы інавацыі і стратэгічнае бачанне ў авангардзе тэхналогій.

Захавайце сваё кіраўніцтва па сінтэтычных дадзеных зараз!
- Што такое сінтэтычныя дадзеныя?
- Чаму арганізацыі выкарыстоўваюць яго?
- Выпадкі кліентаў, якія дадаюць сінтэтычныя даныя
- З чаго пачаць
