

Што такое сінтэтычныя дадзеныя?
Адказ адносна просты. У той час як зыходныя даныя збіраюцца пры ўсіх вашых узаемадзеяннях з рэальнымі людзьмі (напрыклад, кліентамі, пацыентамі, супрацоўнікамі і г.д.) і праз усе вашы ўнутраныя працэсы, сінтэтычныя даныя генеруюцца камп'ютэрным алгарытмам. Гэты кампутарны алгарытм генеруе цалкам новыя і штучныя кропкі даных.
Вырашыце праблемы канфідэнцыяльнасці дадзеных
Сінтэтычна згенераваныя даныя складаюцца з цалкам новых і штучных кропак даных без узаемасувязных адносін з зыходнымі данымі. Такім чынам, ні адна з сінтэтычных кропак дадзеных не можа быць прасачана назад або зменена з арыгінальнымі дадзенымі. У выніку сінтэтычныя даныя вызваляюцца ад правілаў прыватнасці, такіх як GDPR, і служаць рашэннем для вырашэння і пераадолення праблем з канфідэнцыяльнасцю даных.
Павялічвайце і мадэлюйце
Генератыўны аспект генерацыі сінтэтычных даных дазваляе дапаўняць і мадэляваць цалкам новыя дадзеныя. Гэта функцыянуе як рашэнне, калі ў вас недастаткова дадзеных (дэфіцыт дадзеных), калі вы хочаце павысіць выбарку крайніх выпадкаў або калі ў вас яшчэ няма дадзеных.
Тут у цэнтры ўвагі Syntho - структураваныя дадзеныя (дадзеныя, адфарматаваныя ў табліцах, якія змяшчаюць радкі і слупкі, як вы бачыце на лістах Excel), але нам заўсёды падабаецца ілюстраваць паняцце сінтэтычных дадзеных праз выявы, таму што гэта больш прывабна.
Тры тыпу сінтэтычных даных сапраўды існуюць у рамках сінтэтычных даных. Гэтыя 3 тыпу сінтэтычных даных: фіктыўныя даныя, сінтэтычныя даныя, створаныя на аснове правілаў, і сінтэтычныя даныя, створаныя штучным інтэлектам (ІІ). Мы коратка тлумачым, што такое 3 розных тыпу сінтэтычных даных.
Фіктыўныя дадзеныя - гэта выпадкова згенераваныя даныя (напрыклад, з дапамогай генератара фіктыўных даных).
Такім чынам, характарыстыкі, адносіны і статыстычныя заканамернасці, якія знаходзяцца ў зыходных дадзеных, не захоўваюцца, не фіксуюцца і не прайграваюцца ў згенераваных фіктыўных дадзеных. Такім чынам, рэпрэзентатыўнасць фіктыўных даных / фіктыўных дадзеных мінімальная ў параўнанні з зыходнымі дадзенымі.
Сінтэтычныя даныя, створаныя на аснове правілаў, — гэта сінтэтычныя даныя, створаныя з дапамогай загадзя вызначанага набору правілаў. Прыкладам гэтых загадзя вызначаных правілаў можа быць тое, што вы хацелі б мець сінтэтычныя даныя з пэўным мінімальным значэннем, максімальным або сярэднім значэннем. Любыя характарыстыкі, адносіны і статыстычныя мадэлі, якія вы хацелі б прайграць у сінтэтычных дадзеных, створаных на аснове правілаў, павінны быць папярэдне вызначаны.
Такім чынам, якасць дадзеных будзе такім жа добрым, як і загадзя вызначаны набор правілаў. Гэта прыводзіць да праблем, калі высокая якасць дадзеных мае сутнасць. Па-першае, можна вызначыць толькі абмежаваны набор правілаў, якія будуць фіксавацца ў сінтэтычных дадзеных. Акрамя таго, налада некалькіх правілаў звычайна прыводзіць да перакрыцця і супярэчлівасці правілаў. Больш за тое, вы ніколі не зможаце цалкам ахапіць усе адпаведныя правілы. Акрамя таго, могуць быць адпаведныя правілы, пра якія вы нават не ведаеце. І, нарэшце (і не забывайце), гэта зойме ў вас шмат часу і энергіі, што прывядзе да неэфектыўнага рашэння.
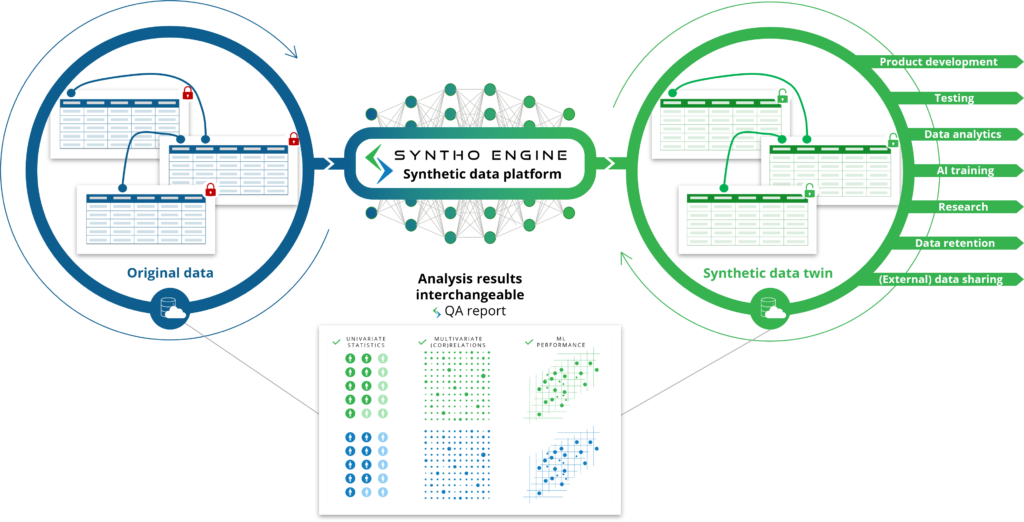
Як вы і чакаеце з назвы, сінтэтычныя даныя, створаныя штучным інтэлектам (AI), - гэта сінтэтычныя даныя, створаныя алгарытмам штучнага інтэлекту (AI). Мадэль AI навучаецца на зыходных дадзеных, каб даведацца ўсе характарыстыкі, адносіны і статыстычныя мадэлі. Пасля гэтага алгарытм ІІ можа генераваць цалкам новыя кропкі даных і мадэлюе гэтыя новыя кропкі даных такім чынам, што ён прайгравае характарыстыкі, адносіны і статыстычныя мадэлі з зыходнага набору даных. Гэта тое, што мы называем сінтэтычным двайнікам дадзеных.
Мадэль AI імітуе зыходныя дадзеныя для стварэння сінтэтычных двайнікаў дадзеных, якія можна выкарыстоўваць як-калі гэта зыходныя дадзеныя. Гэта адкрывае розныя варыянты выкарыстання, калі сінтэтычныя даныя, згенераваныя ІІ, могуць выкарыстоўвацца ў якасці альтэрнатывы для выкарыстання зыходных (канфідэнцыйных) даных, напрыклад, выкарыстанне сінтэтычных даных, згенераваных ІІ, у якасці тэставых, дэма-даных або для аналітыкі.
У параўнанні з сінтэтычнымі данымі, створанымі на аснове правілаў: замест таго, каб вы вывучалі і вызначалі адпаведныя правілы, алгарытм ІІ робіць гэта аўтаматычна. Тут будуць ахоплены не толькі характарыстыкі, адносіны і статыстычныя мадэлі, пра якія вы ведаеце, але і характарыстыкі, адносіны і статыстычныя мадэлі, пра якія вы нават не ведаеце.
У залежнасці ад вашага варыянту выкарыстання, рэкамендуецца спалучэнне фіктыўных даных / фіктыўных даных, сінтэтычных даных, згенераваных на аснове правілаў, або сінтэтычных даных, створаных штучным інтэлектам (AI). Гэты агляд дае вам першае ўказанне на тое, які тып сінтэтычных даных выкарыстоўваць. Паколькі Syntho падтрымлівае ўсе іх, не саромейцеся звяртацца да нашых экспертаў, каб яны з намі паглыбіліся ў ваш варыянт выкарыстання.
