Сінтэтычныя даныя, створаныя штучным інтэлектам, лёгкі і хуткі доступ да высакаякасных дадзеных?
ІІ генеруе сінтэтычныя даныя на практыцы
Syntho, эксперт у галіне сінтэтычных дадзеных, створаных AI, імкнецца ператварыць privacy by design у канкурэнтную перавагу з сінтэтычнымі дадзенымі, створанымі AI. Яны дапамагаюць арганізацыям стварыць трывалую аснову дадзеных з лёгкім і хуткім доступам да высакаякасных даных і нядаўна атрымалі ўзнагароду Philips Innovation Award.
Тым не менш, генерацыя сінтэтычных даных з дапамогай ІІ з'яўляецца адносна новым рашэннем, якое звычайна ўводзіць часта задаюць пытанні. Каб адказаць на іх, Syntho разам з SAS, лідэрам на рынку пашыранай аналітыкі і праграмнага забеспячэння для штучнага інтэлекту, распачаў тэматычнае даследаванне.
У супрацоўніцтве з галандскай кааліцыяй штучнага інтэлекту (NL AIC) яны даследавалі каштоўнасць сінтэтычных даных, параўноўваючы сінтэтычныя даныя, створаныя AI, згенераваныя Syntho Engine, з арыгінальнымі дадзенымі з дапамогай розных ацэнак якасці дадзеных, юрыдычнай абгрунтаванасці і зручнасці выкарыстання.
Ананімізацыя дадзеных не рашэнне?
Класічныя метады ананімізацыі аб'ядноўвае тое, што яны маніпулююць зыходнымі дадзенымі, каб перашкодзіць адсочванню асоб. Прыкладамі з'яўляюцца абагульненне, падаўленне, сціранне, псеўданімізацыя, маскіроўка даных і перамешванне радкоў і слупкоў. Вы можаце знайсці прыклады ў табліцы ніжэй.
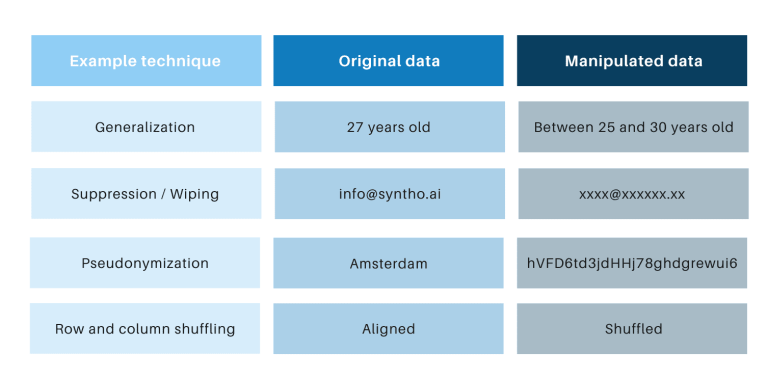
Гэтыя метады ствараюць 3 ключавыя праблемы:
- Яны працуюць па-рознаму ў залежнасці ад тыпу і набору даных, што робіць іх цяжка маштабаваць. Акрамя таго, паколькі яны працуюць па-рознаму, заўсёды будуць абмяркоўвацца, якія метады ўжываць і якая камбінацыя метадаў неабходная.
- Заўсёды існуе ўзаемасувязь з зыходнымі дадзенымі. Гэта азначае, што заўсёды будзе існаваць рызыка канфідэнцыяльнасці, асабліва з-за ўсіх адкрытых набораў даных і даступных метадаў звязвання гэтых набораў даных.
- Яны маніпулююць дадзенымі і тым самым знішчаюць дадзеныя ў працэсе. Гэта асабліва разбуральна для задач штучнага інтэлекту, дзе «прагназуючая здольнасць» мае важнае значэнне, таму што дадзеныя дрэннай якасці прывядуць да дрэннага разумення мадэлі ІІ (увядзенне смецця прывядзе да выдалення смецця).
Гэтыя моманты таксама ацэньваюцца з дапамогай гэтага тэматычнага даследавання.
Уводзіны ў тэматычны даследаванні
Для тэматычнага даследавання мэтавым наборам даных быў набор даных тэлекамунікацый, прадастаўлены SAS, які змяшчае даныя 56.600 128 кліентаў. Набор даных змяшчае XNUMX слупкоў, у тым ліку адзін слупок, які паказвае, пакінуў кліент кампанію (г.зн. «збракваў») ці не. Мэтай тэматычнага даследавання было выкарыстанне сінтэтычных даных для навучання некаторых мадэляў для прагназавання адтоку кліентаў і ацэнкі прадукцыйнасці гэтых навучаных мадэляў. Паколькі прагназаванне адтоку з'яўляецца задачай класіфікацыі, SAS выбрала чатыры папулярныя мадэлі класіфікацыі, каб зрабіць прагнозы, у тым ліку:
- Выпадковы лес
- Градыентнае ўзмацненне
- Лагістычны рэгрэс
- Нейронная сетка
Перад генерацыяй сінтэтычных даных SAS выпадковым чынам падзяліла набор даных тэлекамунікацый на набор цягнікоў (для навучання мадэляў) і набор утрымання (для ацэнкі мадэляў). Наяўнасць асобнага набору рэзультатыўных паказчыкаў для падліку балаў дазваляе непрадузята ацэньваць, наколькі добра можа працаваць мадэль класіфікацыі пры ўжыванні да новых даных.
Выкарыстоўваючы набор цягнікоў у якасці ўваходных дадзеных, Syntho выкарыстаў свой Syntho Engine для стварэння сінтэтычнага набору даных. Для параўнальнага аналізу SAS таксама стварыў маніпуляваную версію набору цягнікоў пасля прымянення розных метадаў ананімізацыі для дасягнення пэўнага парога (k-ананімнасці). Папярэднія крокі прывялі да чатырох набораў даных:
- Набор даных цягніка (г.зн. зыходны набор даных за вылікам набору даных утрымання)
- Набор даных (г.зн. падмноства зыходнага набору даных)
- Ананімны набор даных (на аснове набору даных цягніка)
- Сінтэтычны набор даных (заснаваны на наборы даных цягніка)
Наборы даных 1, 3 і 4 былі выкарыстаны для навучання кожнай мадэлі класіфікацыі, у выніку чаго было 12 (3 х 4) навучаных мадэляў. Пазней SAS выкарыстаў набор даных, каб вымераць дакладнасць, з якой кожная мадэль прагназуе адток кліентаў. Вынікі прадстаўлены ніжэй, пачынаючы з некаторых асноўных статыстычных дадзеных.
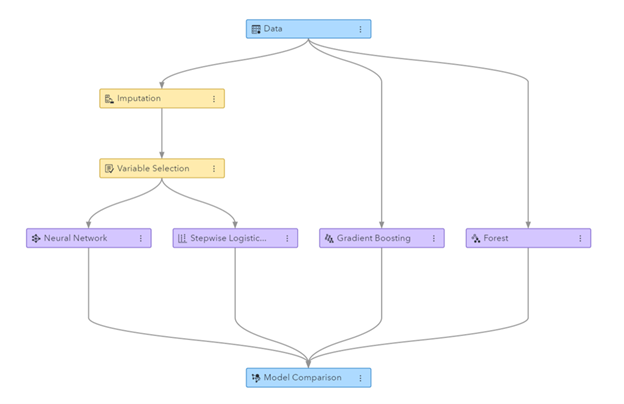
Малюнак: канвеер машыннага навучання, створаны ў SAS Visual Data Mining і Machine Learning
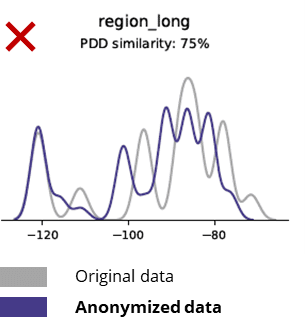
Асноўная статыстыка пры параўнанні ананімных даных з зыходнымі
Тэхнікі ананімізацыі знішчаюць нават асноўныя шаблоны, бізнес-логіку, адносіны і статыстыку (як у прыкладзе ніжэй). Такім чынам, выкарыстанне ананімных дадзеных для базавай аналітыкі дае ненадзейныя вынікі. Насамрэч, нізкая якасць ананімных даных зрабіла амаль немагчымым іх выкарыстанне для прасунутых аналітычных задач (напрыклад, мадэлявання AI/ML і прыборнай панэлі).
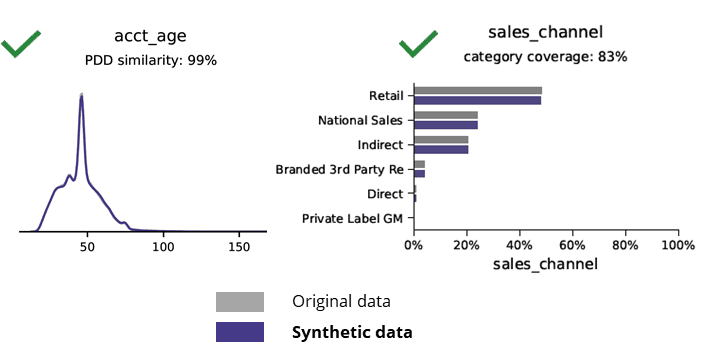
Асноўная статыстыка пры параўнанні сінтэтычных даных з зыходнымі
Сінтэтычная генерацыя даных з дапамогай ІІ захоўвае асноўныя шаблоны, бізнес-логіку, адносіны і статыстыку (як у прыкладзе ніжэй). Такім чынам, выкарыстанне сінтэтычных дадзеных для базавай аналітыкі дае надзейныя вынікі. Ключавое пытанне: ці прымяняюцца сінтэтычныя дадзеныя для задач пашыранай аналітыкі (напрыклад, мадэлявання AI/ML і прыборнай панэлі)?
Сінтэтычныя даныя, створаныя штучным інтэлектам, і пашыраная аналітыка
Сінтэтычныя дадзеныя ўтрымліваюцца не толькі для асноўных шаблонаў (як паказана на папярэдніх графіках), яны таксама фіксуюць глыбокія «схаваныя» статыстычныя заканамернасці, неабходныя для прасунутых аналітычных задач. Апошняе дэманструецца на дыяграме ніжэй, што паказвае на тое, што дакладнасць мадэляў, навучаных на сінтэтычных дадзеных, у параўнанні з мадэлямі, навучанымі на зыходных дадзеных, падобныя. Акрамя таго, з плошчай пад крывой (AUC*), блізкай да 0.5, мадэлі, навучаныя на ананімных дадзеных, працуюць значна горш. Поўны справаздачу з усімі перадавымі аналітычнымі ацэнкамі сінтэтычных даных у параўнанні з зыходнымі дадзенымі даступны па запыце.
*AUC: плошчу пад крывой з'яўляецца мерай дакладнасці перадавых аналітычных мадэляў з улікам праўдзівых станоўчых, ілжывых, ілжывых адмоўных і сапраўдных адмоўных паказчыкаў. 0,5 азначае, што мадэль прагназуе выпадковым чынам і не мае прадказальнай сілы, а 1 азначае, што мадэль заўсёды правільная і мае поўную прагнастычную сілу.
Акрамя таго, гэтыя сінтэтычныя дадзеныя могуць быць выкарыстаны для разумення характарыстык дадзеных і асноўных зменных, неабходных для фактычнага навучання мадэляў. Уваходныя дадзеныя, выбраныя алгарытмамі на сінтэтычных дадзеных у параўнанні з зыходнымі дадзенымі, былі вельмі падобныя. Такім чынам, працэс мадэлявання можа быць выкананы на гэтай сінтэтычнай версіі, што зніжае рызыку ўзлому дадзеных. Аднак пры вывадзе асобных запісаў (напрыклад, кліентаў сувязі) рэкамендуецца перанавучанне на зыходных дадзеных для тлумачэння, большага прызнання або проста з-за рэгулявання.
AUC па алгарытме, згрупаваным па метадзе
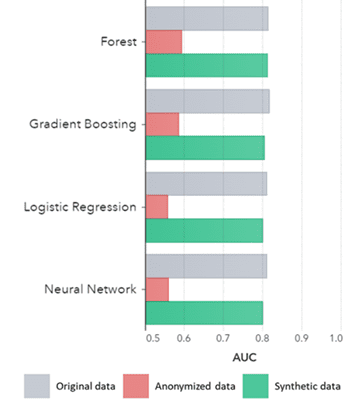
Высновы:
- Мадэлі, навучаныя на сінтэтычных дадзеных, у параўнанні з мадэлямі, навучанымі на зыходных дадзеных, паказваюць вельмі падобную прадукцыйнасць
- Мадэлі, навучаныя на ананімных дадзеных з дапамогай «класічных метадаў ананімізацыі», паказваюць горш прадукцыйнасць у параўнанні з мадэлямі, навучанымі на зыходных або сінтэтычных дадзеных
- Генерацыя сінтэтычных даных лёгка і хутка, таму што тэхніка працуе абсалютна аднолькава для набору і тыпу даных.
Выпадкі выкарыстання сінтэтычных даных, якія дадаюць каштоўнасць
Варыянт выкарыстання 1: сінтэтычныя дадзеныя для распрацоўкі мадэлі і пашыранай аналітыкі
Наяўнасць моцнай базы дадзеных з простым і хуткім доступам да даных высокай якасці, якія можна выкарыстоўваць, вельмі важна для распрацоўкі мадэляў (напрыклад, прыборных панэляў [BI] і пашыранай аналітыкі [AI & ML]). Аднак многія арганізацыі пакутуюць ад неаптымальнай базы дадзеных, што прыводзіць да трох ключавых праблем:
- Атрыманне доступу да даных займае ўзрост з -за правілаў (прыватнасці), унутраных працэсаў або сховішчаў дадзеных
- Класічныя метады ананімізацыі знішчаюць дадзеныя, што робіць іх непрыдатнымі для аналізу і пашыранай аналітыкі (смецце ўваходзіць = смецце выходзіць)
- Існуючыя рашэнні не маштабуюцца, таму што яны працуюць па-рознаму на набор даных і тып даных і не могуць апрацоўваць вялікія шматтаблічныя базы дадзеных
Падыход да сінтэтычных даных: распрацоўвайце мадэлі з такімі ж добрымі, як і рэальнымі сінтэтычнымі дадзенымі, каб:
- Мінімізуйце выкарыстанне зыходных дадзеных, не перашкаджаючы распрацоўшчыкам
- Разблакіруйце асабістыя дадзеныя і атрымайце доступ да дадатковых дадзеных, якія былі раней абмежаваны (напрыклад, з -за прыватнасці)
- Лёгкі і хуткі доступ да адпаведных дадзеных
- Маштабуецца рашэнне, якое працуе аднолькава для кожнага набору дадзеных, тыпу дадзеных і для масіўных баз дадзеных
Гэта дазваляе арганізацыі стварыць трывалую аснову дадзеных з лёгкім і хуткім доступам да даных высокай якасці, каб разблакіраваць даныя і выкарыстоўваць магчымасці перадачы дадзеных.
Варыянт выкарыстання 2: разумныя сінтэтычныя тэставыя дадзеныя для тэставання, распрацоўкі і дастаўкі праграмнага забеспячэння
Тэставанне і распрацоўка з высакаякаснымі тэставымі дадзенымі вельмі важныя для пастаўкі найноўшых праграмных рашэнняў. Выкарыстанне арыгінальных даных вытворчасці здаецца відавочным, але недапушчальна з-за правілаў (канфідэнцыяльнасці). Альтэрнатыва Test Data Management (TDM) інструменты прадстаўляюць «legacy-by-design», каб правільна атрымаць тэставыя дадзеныя:
- Не адлюстроўваюць вытворчыя даныя, бізнес-логіка і спасылкай цэласнасці не захоўваюцца
- Працаваць павольна і займае шмат часу
- Патрабуецца ручная праца
Падыход да сінтэтычных даных: тэстуйце і распрацоўвайце з дапамогай сінтэтычных тэставых даных, створаных AI, каб пастаўляць сучасныя праграмныя рашэнні, разумныя з:
- Вытворчыя дадзеныя з захаванай бізнес-логікай і спасылкай цэласнасцю
- Лёгкая і хуткая генерацыя дадзеных з дапамогай сучаснага AI
- Канфідэнцыяльнасць па дызайне
- Лёгка, хутка і agile
Гэта дазваляе арганізацыі тэставаць і распрацоўваць з тэставымі дадзенымі наступнага ўзроўню, каб пастаўляць самыя сучасныя праграмныя рашэнні!
Больш падрабязная інфармацыя
Зацікавіліся? Для атрымання дадатковай інфармацыі аб сінтэтычных дадзеных наведайце вэб-сайт Syntho або звярніцеся да Віма Кеса Янсэна. Для атрымання дадатковай інфармацыі аб SAS наведайце www.sas.com або звяжыцеся з kees@syntho.ai.
У гэтым выпадку выкарыстання Syntho, SAS і NL AIC працуюць разам для дасягнення запланаваных вынікаў. Syntho з'яўляецца экспертам у галіне сінтэтычных даных, створаных AI, а SAS з'яўляецца лідэрам на рынку аналітыкі і прапануе праграмнае забеспячэнне для вывучэння, аналізу і візуалізацыі дадзеных.
* Прагназуе 2021 г. Стратэгіі даных і аналітыкі для кіравання, маштабавання і трансфармацыі лічбавага бізнесу, Gartner, 2020 г.

Захавайце сваё кіраўніцтва па сінтэтычных дадзеных зараз!
- Што такое сінтэтычныя дадзеныя?
- Чаму арганізацыі выкарыстоўваюць яго?
- Выпадкі кліентаў, якія дадаюць сінтэтычныя даныя
- З чаго пачаць
