адгадай хто? 5 прыкладаў, чаму выдаленне імёнаў не варыянт



Адгадайце, хто? Хоць я ўпэўнены, што большасць з вас ведае гэтую гульню з тых часоў, вось кароткі агляд. Мэта гульні: даведайцеся імя героя мультфільма, абранага вашым праціўнікам, задаючы пытанні «так» і «не», напрыклад, «ці носіць чалавек шапку?» ці "чалавек носіць акуляры"? Гульцы ліквідуюць кандыдатаў на падставе адказу суперніка і вывучаюць атрыбуты, звязаныя з таямнічым характарам суперніка. Першы гулец, які разбярэцца ў таямнічым характары іншага гульца, выйграе гульню.
Вы зразумелі. Трэба ідэнтыфікаваць чалавека з набору дадзеных, маючы толькі доступ да адпаведных атрыбутаў. На самай справе, мы рэгулярна бачым гэтае паняцце «Угадай, хто» прымяняецца на практыцы, але затым выкарыстоўваецца на наборах дадзеных, адфарматаваных радкамі і слупкамі, якія змяшчаюць атрыбуты рэальных людзей. Асноўнае адрозненне пры працы з дадзенымі заключаецца ў тым, што людзі схільныя недаацэньваць лёгкасць, з дапамогай якой рэальныя асобы могуць быць раскрыты, маючы доступ толькі да некалькіх атрыбутаў.
Як паказвае гульня «Угадай хто», хтосьці можа вызначыць асоб, маючы доступ толькі да некалькіх атрыбутаў. Ён служыць простым прыкладам таго, чаму выдаленне толькі "імёнаў" (або іншых прамых ідэнтыфікатараў) з вашага набору дадзеных не ўдаецца як метад ананімізацыі. У гэтым блогу мы прадстаўляем чатыры практычныя выпадкі, каб паведаміць вам пра рызыкі прыватнасці, звязаныя з выдаленнем слупкоў як сродкам ананімізацыі дадзеных.
Рызыка нападаў на сувязь - гэта самая важная прычына, чаму выключэнне выдалення імёнаў не працуе (больш) як метад ананімізацыі. З дапамогай атакі злучэння зламыснік аб'ядноўвае зыходныя дадзеныя з іншымі даступнымі крыніцамі дадзеных, каб адназначна ідэнтыфікаваць асобу і даведацца (часта адчувальную) інфармацыю пра гэтага чалавека.
Ключавым тут з'яўляецца наяўнасць іншых рэсурсаў дадзеных, якія прысутнічаюць зараз або могуць з'явіцца ў будучыні. Падумайце пра сябе. Колькі вашых асабістых дадзеных можна знайсці ў Facebook, Instagram або LinkedIn, якія патэнцыйна могуць быць выкарыстаны для атакі на сувязь?
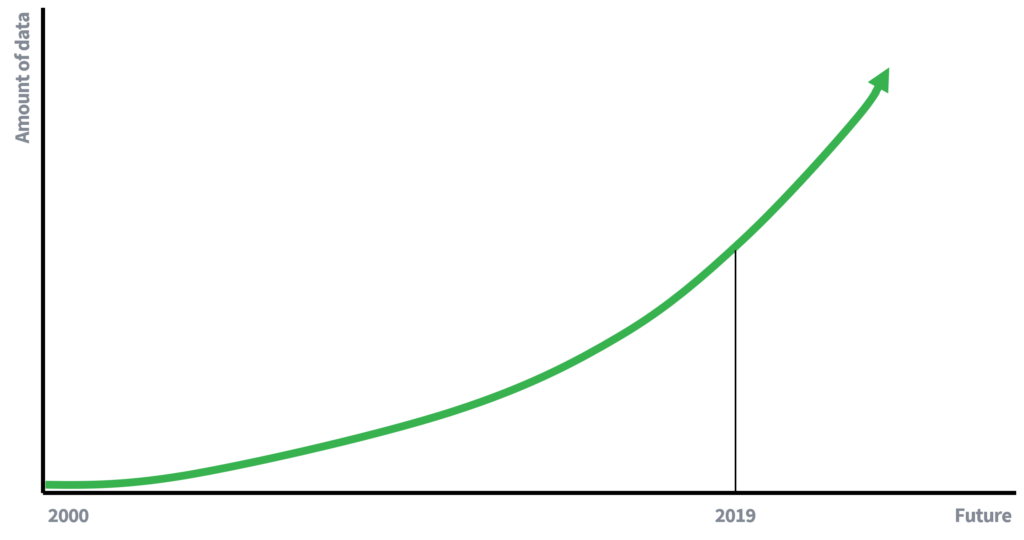
У ранейшыя часы наяўнасць дадзеных была значна больш абмежаванай, што часткова тлумачыць, чаму выдалення імёнаў было дастаткова для захавання канфідэнцыяльнасці асоб. Менш даступныя дадзеныя азначаюць меншыя магчымасці для звязвання дадзеных. Аднак цяпер мы (актыўныя) удзельнікі эканомікі, якая кіруецца дадзенымі, дзе аб'ём дадзеных расце ў геаметрычнай прагрэсіі. Дадатковыя дадзеныя і ўдасканаленне тэхналогій збору дадзеных прывядуць да павелічэння патэнцыялу нападаў на сувязь. Што можна напісаць праз 10 гадоў пра рызыку атакі сувязі?
Ілюстрацыя 1
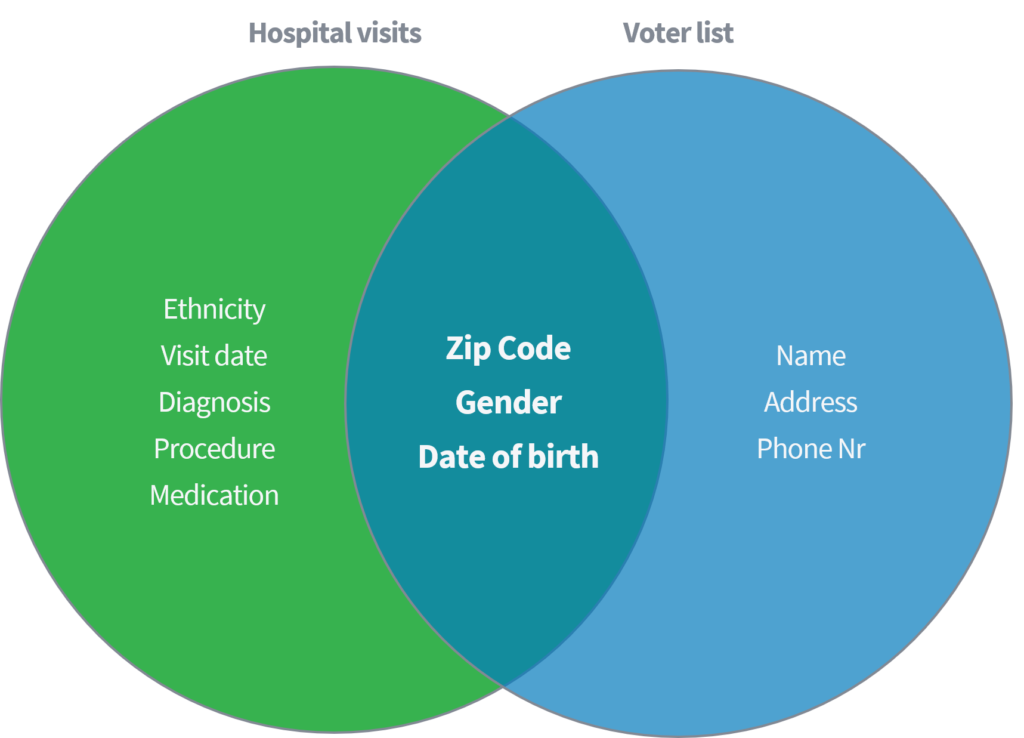
Суіні (2002) прадэманстравала ў акадэмічным дакуменце, як ёй удалося вызначыць і атрымаць адчувальныя медыцынскія дадзеныя ад асобных людзей на аснове прывязкі агульнадаступнага набору дадзеных «наведванняў бальніц» да агульнадаступнага рэгістратара галасавання ў ЗША. Абодва набору дадзеных мяркуюцца належнай ананімай праз выдаленне імёнаў і іншых прамых ідэнтыфікатараў.
Ілюстрацыя 2
Зыходзячы толькі з трох параметраў (1) паштовы індэкс, (2) пол і (3) дата нараджэння, яна паказала, што 87% усяго насельніцтва ЗША можа быць ідэнтыфікавана паўторна, супаставіўшы вышэйзгаданыя атрыбуты з абодвух набораў дадзеных. Затым Суіні паўтарыла сваю працу, маючы "краіну" у якасці альтэрнатывы "паштоваму індэксу". Акрамя таго, яна прадэманстравала, што 18% усяго насельніцтва ЗША можна вызначыць, толькі маючы доступ да набору дадзеных, які змяшчае інфармацыю пра (1) краіну пражывання, (2) пол і (3) дату нараджэння. Падумайце аб вышэйзгаданых публічных крыніцах, такіх як Facebook, LinkedIn або Instagram. Ці бачныя ваша краіна, пол і дата нараджэння, ці іншыя карыстальнікі могуць вылічыць іх?
Ілюстрацыя 3
| Квазі-ідэнтыфікатары | % адназначна вызначанага насельніцтва ЗША (248 мільёнаў) |
| 5-значны ZIP, пол, дата нараджэння | 87% |
| месца, пол, дата нараджэння | 53% |
| краіна, пол, дата нараджэння | 18% |
Гэты прыклад дэманструе, што дэананімізаваць асобаў у, здавалася б, ананімных дадзеных можа быць надзвычай лёгка. Па -першае, гэта даследаванне паказвае на велізарную велічыню рызыкі, як 87% насельніцтва ЗША можна лёгка вызначыць з дапамогай некалькі характарыстык. Па -другое, адкрытыя медыцынскія дадзеныя ў гэтым даследаванні былі вельмі адчувальнымі. Прыклады дадзеных аб выяўленых асобах з баз дадзеных наведванняў бальніцы ўключаюць этнічную прыналежнасць, дыягназ і лекі. Характарыстыкі, якія можна хутчэй захаваць у сакрэце, напрыклад, ад страхавых кампаній.
Іншы рызыка выдалення толькі прамых ідэнтыфікатараў, такіх як імёны, узнікае, калі дасведчаныя людзі валодаюць найвышэйшымі ведамі або інфармацыяй аб рысах або паводзінах канкрэтных асоб у наборы дадзеных. Зыходзячы з іх ведаў, зламыснік можа мець магчымасць звязаць пэўныя запісы дадзеных з рэальнымі людзьмі.
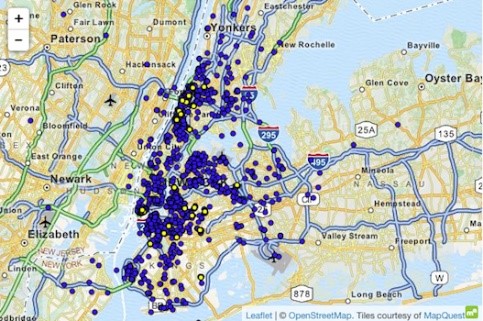
Прыкладам нападу на набор дадзеных з выкарыстаннем найвышэйшых ведаў з'яўляецца выпадак таксі ў Нью -Ёрку, дзе Atockar (2014) змог разгадаць канкрэтных асоб. Наняты набор дадзеных утрымліваў усе паездкі таксі ў Нью -Ёрку, узбагачаны такімі асноўнымі атрыбутамі, як каардынаты пачатку, каардынаты канца, кошт і падказка паездкі.
Дасведчаны чалавек, які ведае Нью -Ёрк, змог здзейсніць паездку на таксі ў клуб для дарослых "Hustler". Адфільтраваўшы "канчатковае месцазнаходжанне", ён вывеў дакладныя пачатковыя адрасы і тым самым вызначыў розных частых наведвальнікаў. Сапраўды гэтак жа можна было вывесці паездкі на таксі, калі быў вядомы хатні адрас чалавека. Час і месцазнаходжанне некалькіх зорак знакамітасцяў былі выяўлены на пляткарных сайтах. Пасля звязвання гэтай інфармацыі з дадзенымі таксі ў Нью -Ёрку было лёгка высветліць іх паездкі на таксі, суму, якую яны заплацілі, і ці атрымалі яны чаевыя.
Ілюстрацыя 4
каардынаты высадкі Hustler
Брэдлі Купер
Джэсіка Альба
Агульная аргументацыя: "гэтыя дадзеныя нічога не вартыя" або "ніхто не можа нічога зрабіць з гэтымі дадзенымі". Гэта часта памылковае меркаванне. Нават самыя нявінныя дадзеныя могуць стварыць унікальны «адбітак пальца» і быць выкарыстаны для паўторнай ідэнтыфікацыі асоб. Гэта рызыка, які вынікае з меркавання, што дадзеныя самі па сабе нічога не вартыя, а гэта не так.
Рызыка ідэнтыфікацыі ўзрасце з павелічэннем колькасці дадзеных, ІІ і іншых інструментаў і алгарытмаў, якія дазваляюць выявіць складаныя адносіны ў дадзеных. Такім чынам, нават калі ваш набор дадзеных не можа быць выяўлены зараз і, як мяркуецца, бескарысны для старонніх асоб сёння, гэта можа быць не заўтра.
Выдатным прыкладам можа служыць той выпадак, калі Netflix збіраўся прыцягнуць увагу свайго аддзела даследаванняў і развіцця праз краўдсорсінг, увёўшы адкрыты конкурс Netflix для паляпшэння сістэмы рэкамендацый да фільмаў. "Той, хто ўдасканальвае алгарытм сумеснай фільтрацыі для прагназавання рэйтынгаў карыстальнікаў фільмаў, атрымлівае прыз у памеры 1,000,000 XNUMX XNUMX долараў ЗША". Каб падтрымаць натоўп, Netflix апублікаваў набор дадзеных, які змяшчае толькі наступныя асноўныя атрыбуты: ідэнтыфікатар карыстальніка, фільм, дата ацэнкі і адзнакі (таму ніякай дадатковай інфармацыі пра карыстальніка або фільм няма).
Ілюстрацыя 5
| UserID | фільм | Дата ацэнкі | Клас |
| 123456789 | Місія невыканальная | 10-12-2008 | 4 |
Асобна дадзеныя здаліся марнымі. Адказваючы на пытанне "Ці ёсць у наборы дадзеных інфармацыя аб кліенце, якую трэба захоўваць у прыватнасці?"
«Не, уся інфармацыя, якая ідэнтыфікуе кліента, была выдалена; засталіся толькі рэйтынгі і даты. Гэта адпавядае нашай палітыцы прыватнасці ... "
Аднак Нараянан (2008) з Тэхаскага ўніверсітэта ў Осціне даказаў адваротнае. Спалучэнне адзнак, даты ацэнкі і фільма асобнага чалавека ўтварае ўнікальны фільм-адбітак пальца. Падумайце аб сваім уласным паводзінах Netflix. Як вы думаеце, колькі людзей глядзелі адзін і той жа фільм? Колькі глядзелі адзін і той жа фільм адначасова?
Галоўнае пытанне, як супаставіць гэты адбітак пальца? Гэта было даволі проста. На падставе інфармацыі з вядомага вэб-сайта па рэйтынгах фільмаў IMDb (Internet Movie Database), падобны адбітак пальца можна сфармаваць. Такім чынам, асоб можна было ідэнтыфікаваць паўторна.
Нягледзячы на тое, што паводзіны пры праглядзе фільмаў не могуць лічыцца адчувальнай інфармацыяй, падумайце аб сваіх уласных паводзінах-вы не супраць, калі б гэта стала агульнадаступным? Прыкладамі, якія Нараянан прадставіў у сваёй працы, з'яўляюцца палітычныя перавагі (рэйтынгі "Ісус з Назарэта" і "Евангелле ад Яна") і сэксуальныя перавагі (рэйтынгі "Бэнт" і "Квір як народ"), якія можна лёгка пераганяць.
GDPR не можа быць надзвычай захапляльным, як і срэбра сярод тэм блога. Тым не менш, пры апрацоўцы персанальных дадзеных карысна ўдакладніць вызначэнні. Паколькі гэты блог распавядае аб распаўсюджанай памылцы выдалення слупкоў як спосабу ананімізацыі дадзеных і выхавання вас у якасці апрацоўшчыка дадзеных, давайце пачнем з вывучэння вызначэння ананімізацыі ў адпаведнасці з GDPR.
Згодна са зводным пунктам 26 GDPR, ананімная інфармацыя вызначаецца як:
"інфармацыя, якая не адносіцца да ідэнтыфікаванай або ідэнтыфікаванай фізічнай асобы, або персанальныя дадзеныя, зробленыя ананімнымі такім чынам, што суб'ект дадзеных не можа быць ідэнтыфікаваны".
Паколькі апрацоўваюцца персанальныя дадзеныя, якія адносяцца да фізічнай асобы, мае значэнне толькі частка 2 вызначэння. Каб адпавядаць вызначэнню, неабходна пераканацца, што суб'ект даных (фізічная асоба) не ідэнтыфікуецца або больш не ідэнтыфікуецца. Аднак, як паказана ў гэтым блогу, ідэнтыфікаваць асоб на аснове некалькіх прыкмет надзвычай проста. Такім чынам, выдаленне імёнаў з набору дадзеных не адпавядае вызначэнню ананімізацыі GDPR.
Мы кінулі выклік аднаму шырока разгляданаму і, на жаль, па -ранейшаму часта ўжывальнаму падыходу ананімізацыі дадзеных: выдаленню імёнаў. У гульні «Угадай хто» і яшчэ чатыры прыклады пра:
было паказана, што выдаленне імёнаў не ўдаецца як ананімізацыя. Хоць прыклады-яскравыя выпадкі, кожны паказвае прастату паўторнай ідэнтыфікацыі і патэнцыйны негатыўны ўплыў на канфідэнцыяльнасць асоб.
У заключэнне можна сказаць, што выдаленне імёнаў з вашага набору дадзеных не прыводзіць да ананімных дадзеных. Такім чынам, нам лепш пазбягаць выкарыстання абодвух тэрмінаў узаемазаменна. Я шчыра спадзяюся, што вы не будзеце прымяняць гэты падыход для ананімізацыі. І калі вы ўсё ж такі зробіце, пераканайцеся, што вы і ваша каманда цалкам разумееце рызыкі канфідэнцыяльнасці і маеце права прымаць гэтыя рызыкі ад імя пацярпелых асоб.
Звяжыцеся з Syntho і адзін з нашых экспертаў звяжацца з вамі на хуткасці святла, каб вывучыць каштоўнасць сінтэтычных дадзеных!