

Отчет об обеспечении качества Syntho оценивает сгенерированные синтетические данные и демонстрирует точность, конфиденциальность и скорость синтетических данных по сравнению с исходными данными.
В Syntho мы понимаем важность надежных и точных синтетических данных. Вот почему мы предоставляем комплексный отчет по обеспечению качества для каждого анализа синтетических данных. Наш отчет о качестве включает в себя различные показатели, такие как распределения, корреляции, многомерные распределения, показатели конфиденциальности и многое другое. Таким образом, вы можете легко оценить, что предоставляемые нами синтетические данные имеют высочайшее качество и могут использоваться с тем же уровнем точности и надежности, что и исходные данные.
Краткий обзор: в этом разделе представлены основные моменты из нашего отчета о качестве синтетических данных. В наших оценках синтетические данные сравниваются с реальными данными по различным измерениям.
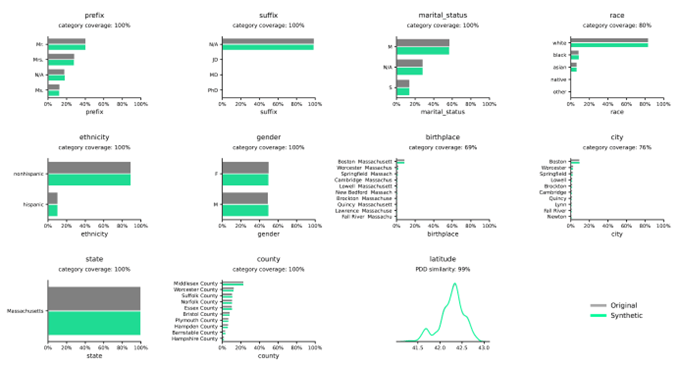
Распределение синтетических данных по сравнению с реальными данными
Распределения иллюстрируют частоту переменных в пределах заданных категорий или значений и точно фиксируются Syntho Engine.
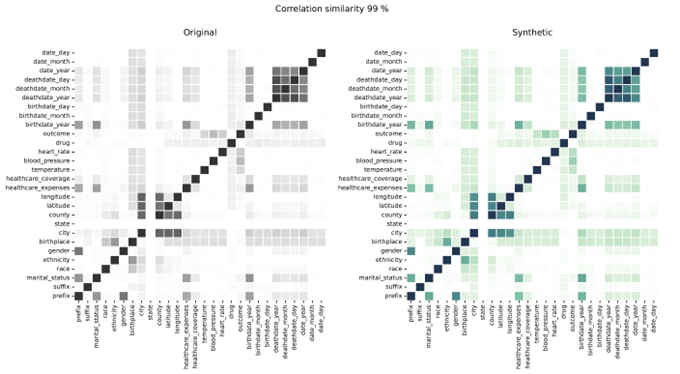
Корреляции синтетических данных по сравнению с реальными данными
Корреляции показывают взаимосвязь между переменными, иллюстрируя степень, в которой переменные связаны. Syntho Engine точно фиксирует эти отношения.
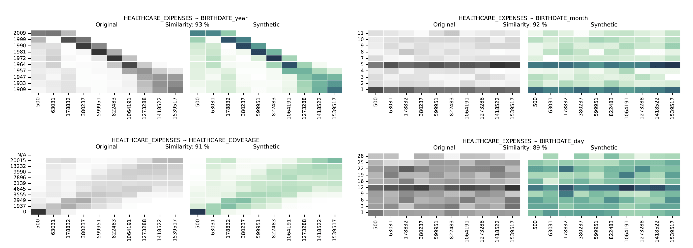
Многомерные распределения синтетических данных по сравнению с реальными данными
Многомерные распределения и многомерные корреляции выводят нас за рамки единичных измерений, обеспечивая полное представление о том, как связаны несколько переменных. Syntho Engine фиксирует эти отношения.
Генерация синтетических данных сложна, и существуют подводные камни, и их необходимо контролировать. В алгоритмах ИИ переобучение представляет собой риск, и это также относится к генерации синтетических данных с помощью ИИ. Следовательно, следует контролировать риск переобучения при создании синтетических данных. Риск переобучения контролируется в Syntho Engine. Кроме того, отчет Syntho Quality Assurance (QA) позволяет организациям продемонстрировать, что синтетические данные не соответствуют исходным данным. Мы также оцениваем аспекты, связанные с конфиденциальностью, которые часто используются внутренними аудиторами.
Тест на «Точные совпадения» с коэффициентом идентичного совпадения (IMR)
Демонстрация того, что соотношение записей синтетических данных, соответствующих реальной записи, из исходных данных не значительно превышает соотношение, которое можно ожидать при анализе данных поезда.
Тест на «Похожие матчи» с расстоянием до ближайшей записи (DCR)
Демонстрация того, что нормализованное расстояние для записей синтетических данных до их ближайшей фактической записи в исходных данных не намного ближе, чем расстояние, которое можно ожидать при анализе данных поезда.
Тест на «Выбросы» с Коэффициент расстояния до ближайшего соседа (NNDR)
Демонстрация того, что отношение расстояния между ближайшей и второй ближайшей синтетической записью к их ближайшей записи в исходных данных не значительно ближе, чем соотношение, которое следует ожидать для данных поезда.
Это всего лишь краткий обзор, который суммирует суть нашего отчета об исследовании качества синтетических данных и обеспечении качества. Он предлагает детальное понимание распределений, корреляций и многомерных распределений как части синтетических данных, полученных с помощью расширенных возможностей Syntho Engine. Более подробную информацию о нашем отчете по обеспечению качества можно получить по запросу.