Синтетические данные, созданные искусственным интеллектом, простой и быстрый доступ к высококачественным данным?
ИИ сгенерировал синтетические данные на практике
Syntho, эксперт в области синтетических данных, генерируемых искусственным интеллектом, стремится превратить privacy by design в конкурентное преимущество с синтетическими данными, сгенерированными ИИ. Они помогают организациям создавать прочную базу данных с простым и быстрым доступом к высококачественным данным и недавно получили награду Philips Innovation Award.
Однако генерация синтетических данных с помощью ИИ — это относительно новое решение, которое обычно вызывает часто задаваемые вопросы. Чтобы ответить на эти вопросы, Syntho совместно с SAS, лидером рынка программного обеспечения для расширенной аналитики и искусственного интеллекта, начала исследование.
В сотрудничестве с Голландской коалицией ИИ (NL AIC) они исследовали ценность синтетических данных, сравнивая синтетические данные, сгенерированные ИИ, сгенерированные Syntho Engine, с исходными данными с помощью различных оценок качества данных, юридической достоверности и удобства использования.
Анонимизация данных — это не решение?
Общим для классических методов анонимизации является то, что они манипулируют исходными данными, чтобы затруднить отслеживание людей. Примерами являются обобщение, подавление, стирание, псевдонимизация, маскирование данных и перетасовка строк и столбцов. Вы можете найти примеры в таблице ниже.
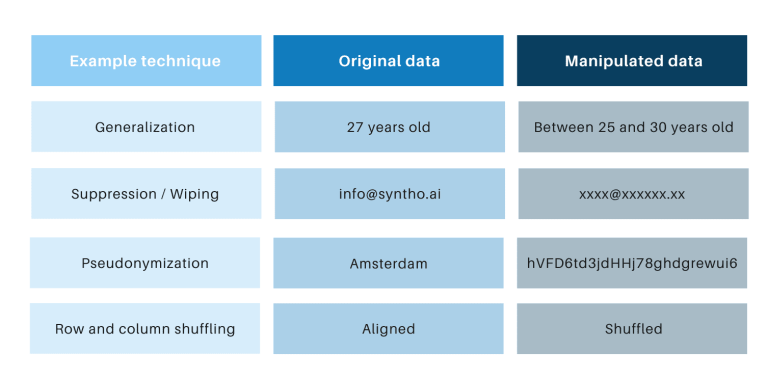
Эти методы создают 3 ключевые проблемы:
- Они работают по-разному в зависимости от типа данных и набора данных, что затрудняет их масштабирование. Кроме того, поскольку они работают по-разному, всегда будут споры о том, какие методы применять и какая комбинация методов необходима.
- Всегда существует отношение один к одному с исходными данными. Это означает, что всегда будет существовать риск для конфиденциальности, особенно из-за всех открытых наборов данных и доступных методов связывания этих наборов данных.
- Они манипулируют данными и тем самым уничтожают данные в процессе. Это особенно разрушительно для задач ИИ, где важна «предсказательная сила», потому что данные плохого качества приведут к неправильным выводам из модели ИИ (мусор на входе приведет к мусору на выходе).
Эти точки также оцениваются с помощью этого тематического исследования.
Введение в тематическое исследование
Для примера целевым набором данных был набор телекоммуникационных данных, предоставленный SAS, содержащий данные 56.600 128 клиентов. Набор данных содержит XNUMX столбцов, в том числе один столбец, показывающий, покинул ли клиент компанию (то есть «ушел») или нет. Цель тематического исследования заключалась в том, чтобы использовать синтетические данные для обучения некоторых моделей прогнозированию оттока клиентов и оценки производительности этих обученных моделей. Поскольку прогнозирование оттока является задачей классификации, SAS выбрала четыре популярные модели классификации для прогнозирования, в том числе:
- Случайный лес
- Повышение градиента
- Логистическая регрессия
- Нейронная сеть
Перед созданием синтетических данных SAS случайным образом разделила набор телекоммуникационных данных на набор поездов (для обучения моделей) и набор задержек (для оценки моделей). Наличие отдельного набора задержек для оценки позволяет беспристрастно оценить, насколько хорошо модель классификации может работать применительно к новым данным.
Используя набор поездов в качестве входных данных, Syntho использовал свой Syntho Engine для создания синтетического набора данных. Для сравнительного анализа SAS также создала модифицированную версию поезда после применения различных методов анонимизации для достижения определенного порога (k-анонимности). Первые шаги привели к четырем наборам данных:
- Набор данных поезда (т. е. исходный набор данных минус набор данных удержания)
- Задержанный набор данных (т. е. подмножество исходного набора данных)
- Анонимизированный набор данных (на основе набора данных поезда)
- Синтетический набор данных (на основе набора данных поезда)
Наборы данных 1, 3 и 4 использовались для обучения каждой модели классификации, в результате чего было получено 12 (3 x 4) обученных моделей. Впоследствии SAS использовала этот набор данных для измерения точности, с которой каждая модель предсказывает отток клиентов. Результаты представлены ниже, начиная с некоторых основных статистических данных.
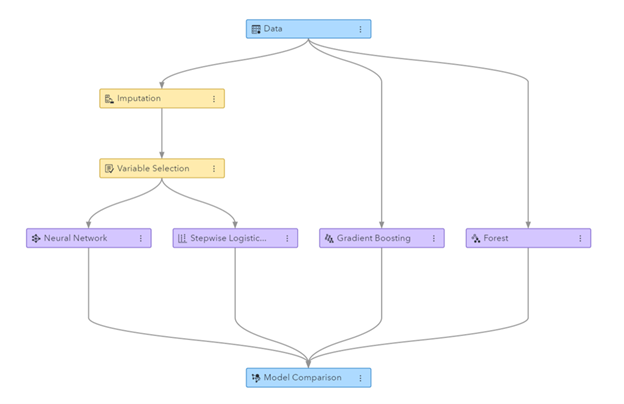
Рисунок: Конвейер машинного обучения, созданный в SAS Visual Data Mining and Machine Learning
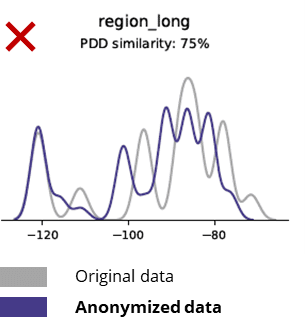
Базовая статистика при сравнении обезличенных данных с исходными данными
Методы анонимизации разрушают даже базовые шаблоны, бизнес-логику, отношения и статистику (как в примере ниже). Таким образом, использование анонимных данных для базовой аналитики дает ненадежные результаты. Фактически, низкое качество анонимных данных сделало практически невозможным их использование для задач расширенной аналитики (например, моделирования AI/ML и создания информационных панелей).
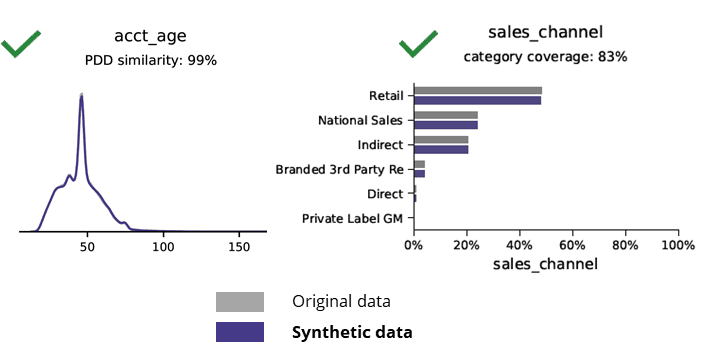
Базовая статистика при сравнении синтетических данных с исходными данными
Генерация синтетических данных с помощью ИИ сохраняет основные шаблоны, бизнес-логику, отношения и статистику (как в примере ниже). Таким образом, использование синтетических данных для базовой аналитики дает надежные результаты. Ключевой вопрос: годятся ли синтетические данные для задач расширенной аналитики (например, моделирования AI/ML и создания информационных панелей)?
Синтетические данные, созданные искусственным интеллектом, и расширенная аналитика
Синтетические данные применимы не только к базовым закономерностям (как показано на предыдущих графиках), но и фиксируют глубокие «скрытые» статистические закономерности, необходимые для сложных аналитических задач. Последнее продемонстрировано на гистограмме ниже, что указывает на то, что точность моделей, обученных на синтетических данных, по сравнению с моделями, обученными на исходных данных, одинакова. Кроме того, с площадью под кривой (AUC*), близкой к 0.5, модели, обученные на анонимных данных, работают намного хуже. Полный отчет со всеми оценками расширенной аналитики синтетических данных в сравнении с исходными данными доступен по запросу.
*AUC: площадь под кривой является мерой точности моделей расширенной аналитики с учетом истинно положительных, ложноположительных, ложноотрицательных и истинно отрицательных результатов. 0,5 означает, что модель предсказывает случайным образом и не имеет предсказательной силы, а 1 означает, что модель всегда верна и имеет полную предсказательную силу.
Кроме того, эти синтетические данные можно использовать для понимания характеристик данных и основных переменных, необходимых для фактического обучения моделей. Входные данные, выбранные алгоритмами на синтетических данных по сравнению с исходными данными, были очень похожи. Следовательно, процесс моделирования может быть выполнен на этой синтетической версии, что снижает риск утечки данных. Однако при выводе отдельных записей (например, о клиентах телекоммуникационных компаний) рекомендуется повторное обучение на исходных данных для пояснения, повышения приемлемости или просто из-за регулирования.
AUC по алгоритму, сгруппированному по методу
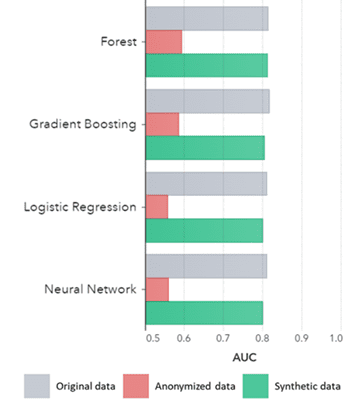
Выводы:
- Модели, обученные на синтетических данных, по сравнению с моделями, обученными на исходных данных, демонстрируют очень схожую производительность.
- Модели, обученные на анонимных данных с помощью «классических методов анонимизации», демонстрируют более низкую производительность по сравнению с моделями, обученными на исходных или синтетических данных.
- Генерация синтетических данных проста и быстра, потому что этот метод работает одинаково для каждого набора данных и для каждого типа данных.
Варианты использования синтетических данных, добавляющие ценность
Вариант использования 1: Синтетические данные для разработки моделей и расширенной аналитики
Наличие надежной базы данных с простым и быстрым доступом к полезным высококачественным данным имеет важное значение для разработки моделей (например, информационных панелей [BI] и расширенной аналитики [AI & ML]). Однако многие организации страдают от неоптимальной базы данных, что приводит к трем ключевым проблемам:
- Получение доступа к данным занимает много времени из-за правил (конфиденциальности), внутренних процессов или разрозненных хранилищ данных.
- Классические методы анонимизации уничтожают данные, делая их непригодными для анализа и расширенной аналитики (мусор на входе = мусор на выходе).
- Существующие решения не масштабируются, поскольку они работают по-разному в зависимости от набора данных и типа данных и не могут работать с большими многотабличными базами данных.
Подход на основе синтетических данных: разрабатывайте модели с использованием синтетических данных, не уступающих реальным, чтобы:
- Сведите к минимуму использование исходных данных, не мешая вашим разработчикам
- Разблокируйте личные данные и получите доступ к большему количеству данных, которые ранее были ограничены (например, из-за конфиденциальности)
- Простой и быстрый доступ к актуальным данным
- Масштабируемое решение, которое работает одинаково для каждого набора данных, типа данных и для больших баз данных
Это позволяет организации создать надежную базу данных с простым и быстрым доступом к пригодным для использования высококачественным данным для разблокировки данных и использования возможностей данных.
Вариант использования 2: интеллектуальные синтетические тестовые данные для тестирования, разработки и поставки программного обеспечения.
Тестирование и разработка с использованием высококачественных тестовых данных необходимы для создания современных программных решений. Использование исходных производственных данных кажется очевидным, но это не разрешено из-за правил (конфиденциальности). Альтернатива Test Data Management (TDM) представляют «legacy-by-design” в правильном получении тестовых данных:
- Не отражают производственные данные и бизнес-логику, а ссылочная целостность не сохраняется.
- Работать медленно и долго
- Требуется ручная работа
Подход на основе синтетических данных. Тестируйте и разрабатывайте с помощью синтетических тестовых данных, сгенерированных искусственным интеллектом, чтобы предоставлять самые современные программные решения с интеллектуальными функциями:
- Производственные данные с сохраненной бизнес-логикой и ссылочной целостностью
- Простое и быстрое создание данных с помощью современного искусственного интеллекта
- Конфиденциальность по дизайну
- Легко, быстро и agile
Это позволяет организации тестировать и разрабатывать с помощью тестовых данных следующего уровня для предоставления самых современных программных решений!
Больше информации
Заинтересованы? Для получения дополнительной информации о синтетических данных посетите веб-сайт Syntho или свяжитесь с Вимом Кисом Янссеном. Для получения дополнительной информации о SAS посетите www.sas.com или свяжитесь с kees@syntho.ai.
В этом случае Syntho, SAS и NL AIC работают вместе для достижения намеченных результатов. Syntho является экспертом в области синтетических данных, генерируемых искусственным интеллектом, а SAS является лидером рынка в области аналитики и предлагает программное обеспечение для изучения, анализа и визуализации данных.
* Predicts 2021 — Data and Analytics Strategies to Governance, Scale and Transform Digital Business, Gartner, 2020.

Сохраните руководство по синтетическим данным прямо сейчас!
- Что такое синтетические данные?
- Почему организации его используют?
- Клиентские кейсы с синтетическими данными, добавляющие ценность
- Как начать
