Gjett hvem? 5 eksempler på hvorfor det ikke er et alternativ å fjerne navn



Gjett hvem? Selv om jeg er sikker på at de fleste av dere kjenner dette spillet fra tidligere dager, her en kort oppsummering. Målet med spillet: oppdag navnet på tegneseriefiguren som er valgt av motstanderen din ved å stille "ja" og "nei" spørsmål, som "bærer personen en hatt?" eller "bruker personen briller"? Spillere eliminerer kandidater basert på motstanderens svar og lærer attributter som er knyttet til motstanderens mystiske karakter. Den første spilleren som finner ut den andre spillerens mystiske karakter vinner spillet.
Du har det. Man må identifisere individet ut av et datasett ved bare å ha tilgang til de tilsvarende attributtene. Faktisk ser vi regelmessig dette konseptet med Guess Who som ble brukt i praksis, men deretter brukt på datasett formatert med rader og kolonner som inneholder attributter for virkelige mennesker. Hovedforskjellen når man arbeider med data er at folk har en tendens til å undervurdere hvor enkelt virkelige individer kan avmaskeres ved å ha tilgang til bare noen få attributter.
Som Guess Who -spillet illustrerer, kan noen identifisere individer ved å ha tilgang til bare noen få attributter. Det fungerer som et enkelt eksempel på hvorfor det bare er en anonymiseringsteknikk å fjerne "navn" (eller andre direkte identifikatorer) fra datasettet ditt. I denne bloggen gir vi fire praktiske saker for å informere deg om personvernrisikoen forbundet med fjerning av kolonner som et middel til dataanonymisering.
Risikoen for koblingsangrep er den viktigste grunnen til at det å fjerne navn ikke (lenger) fungerer som en metode for anonymisering. Med et koblingsangrep kombinerer angriperen de originale dataene med andre tilgjengelige datakilder for å identifisere et individ på en unik måte og lære (ofte sensitiv) informasjon om denne personen.
Nøkkelen her er tilgjengeligheten av andre dataressurser som er til stede nå, eller som kan bli til stede i fremtiden. Tenk på deg selv. Hvor mye av dine egne personlige data finnes på Facebook, Instagram eller LinkedIn som potensielt kan misbrukes for et koblingsangrep?
Tidligere var tilgjengeligheten av data mye mer begrenset, noe som delvis forklarer hvorfor fjerning av navn var tilstrekkelig for å bevare personvernet til enkeltpersoner. Mindre tilgjengelig data betyr færre muligheter for å koble data. Imidlertid er vi nå (aktive) deltakere i en datadrevet økonomi, hvor datamengden vokser eksponentielt. Flere data og forbedret teknologi for innsamling av data vil føre til økt potensial for koblingsangrep. Hva ville man skrive om 10 år om risikoen for et koblingsangrep?
Illustrasjon 1
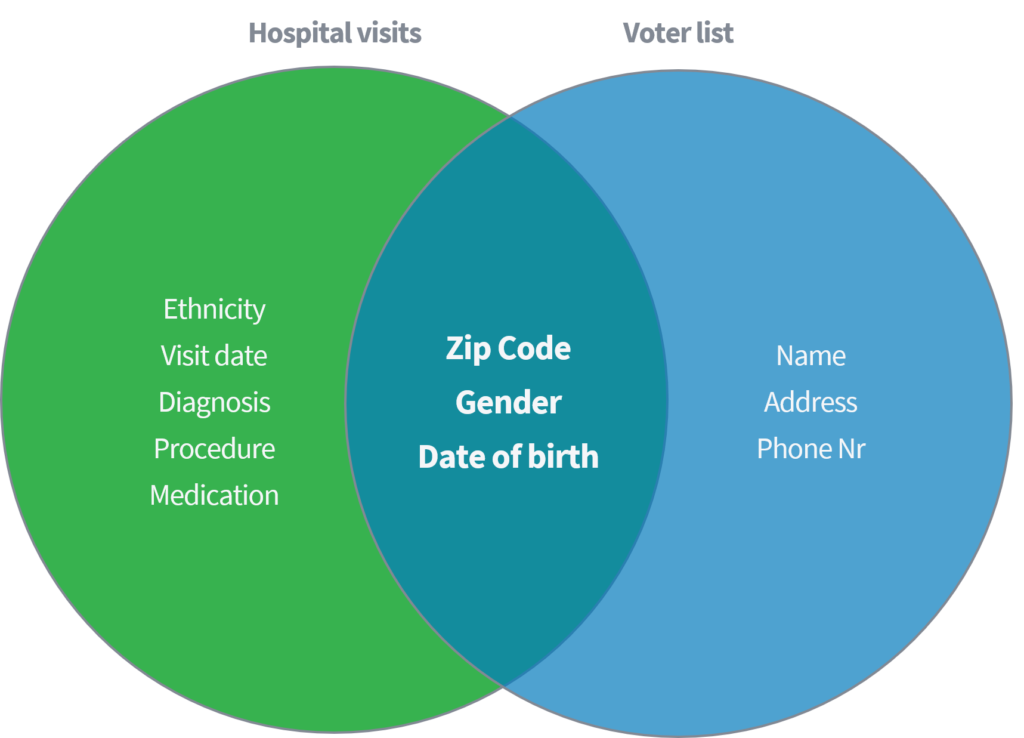
Sweeney (2002) demonstrerte i en akademisk artikkel hvordan hun var i stand til å identifisere og hente sensitive medisinske data fra enkeltpersoner basert på å koble et offentlig tilgjengelig datasett med 'sykehusbesøk' til den offentlig tilgjengelige stemmeregistratoren i USA. Begge datasettene antas å være skikkelig anonymiserte gjennom sletting av navn og andre direkte identifikatorer.
Illustrasjon 2
Basert på bare de tre parameterne (1) postnummer, (2) kjønn og (3) fødselsdato, viste hun at 87% av hele den amerikanske befolkningen kunne gjenidentifiseres ved å matche de nevnte attributtene fra begge datasettene. Sweeney gjentok deretter arbeidet med å ha 'country' som et alternativ til 'postnummer'. I tillegg demonstrerte hun at 18% av hele den amerikanske befolkningen bare kunne identifiseres ved å ha tilgang til et datasett som inneholder informasjon om (1) hjemlandet, (2) kjønn og (3) fødselsdato. Tenk på de nevnte offentlige kildene, som Facebook, LinkedIn eller Instagram. Er ditt land, kjønn og fødselsdato synlig, eller kan andre brukere trekke fra det?
Illustrasjon 3
| Kvasi-identifikatorer | % unikt identifisert av amerikansk befolkning (248 millioner) |
| 5-sifret ZIP, kjønn, fødselsdato | 87% |
| plass, kjønn, fødselsdato | 53% |
| land, kjønn, fødselsdato | 18% |
Dette eksemplet viser at det kan være bemerkelsesverdig enkelt å de-anonymisere enkeltpersoner i tilsynelatende anonyme data. Først indikerer denne studien en enorm risiko, som 87% av den amerikanske befolkningen kan enkelt identifiseres ved hjelp av få egenskaper. For det andre var de eksponerte medisinske dataene i denne studien svært følsomme. Eksempler på eksponerte personers data fra sykehusbesøkets datasett inkluderer etnisitet, diagnose og medisinering. Attributter som man heller kan holde hemmelig, for eksempel fra forsikringsselskaper.
En annen risiko ved å fjerne bare direkte identifikatorer, for eksempel navn, oppstår når informerte individer har overlegen kunnskap eller informasjon om egenskaper eller oppførsel til bestemte individer i datasettet.. Basert på deres kunnskap kan angriperen da kunne koble spesifikke dataposter til faktiske mennesker.
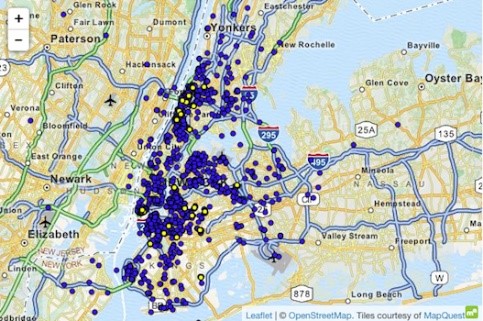
Et eksempel på et angrep på et datasett som bruker overlegen kunnskap, er taxisaken i New York, der Atockar (2014) klarte å avmaske bestemte individer. Det brukte datasettet inneholdt alle drosjeturer i New York, beriket med grunnleggende attributter som startkoordinater, sluttkoordinater, pris og tips på turen.
En informert person som kjenner New York var i stand til å hente drosjeturer til voksenklubben 'Hustler'. Ved å filtrere 'sluttstedet', fant han ut de eksakte startadressene og identifiserte derved forskjellige hyppige besøkende. På samme måte kan man utlede drosjeturer når hjemmeadressen til den enkelte var kjent. Tid og sted for flere kjendisfilmstjerner ble oppdaget på sladdersteder. Etter å ha koblet denne informasjonen til taxidataene i NYC, var det enkelt å utlede taxiturene deres, beløpet de betalte og om de hadde tipset.
Illustrasjon 4
avleveringskoordinater Hustler
Bradley Cooper
Jessica Alba
En vanlig argumentasjonslinje er 'disse dataene er verdiløse' eller 'ingen kan gjøre noe med disse dataene'. Dette er ofte en misforståelse. Selv de mest uskyldige dataene kan danne et unikt "fingeravtrykk" og brukes til å gjenidentifisere individer. Det er risikoen som kommer fra troen på at selve dataene er verdiløse, mens de ikke er det.
Risikoen for identifisering vil øke med økningen av data, AI og andre verktøy og algoritmer som gjør det mulig å avdekke komplekse relasjoner i data. Følgelig, selv om datasettet ditt ikke kan avdekkes nå, og antagelig er ubrukelig for uautoriserte personer i dag, er det kanskje ikke i morgen.
Et godt eksempel er tilfellet der Netflix hadde til hensikt å crowdsource sin FoU -avdeling ved å introdusere en åpen Netflix -konkurranse for å forbedre sitt filmanbefalingssystem. 'Den som forbedrer samarbeidsfiltreringsalgoritmen for å forutsi brukervurderinger for filmer, vinner en premie på US $ 1,000,000'. For å støtte publikum publiserte Netflix et datasett som bare inneholder følgende grunnleggende attributter: userID, film, karakterdato og karakter (så ingen ytterligere informasjon om brukeren eller filmen selv).
Illustrasjon 5
| BrukerID | Film | Dato for karakter | Klasse |
| 123456789 | Mission impossible | 10-12-2008 | 4 |
Isolert sett virket dataene meningsløse. Når du stiller spørsmålet 'Er det noen kundeinformasjon i datasettet som bør holdes privat?', Var svaret:
'Nei, all kundeidentifiserende informasjon er fjernet; alt som gjenstår er rangeringer og datoer. Dette følger vår personvernerklæring ... '
Imidlertid beviste Narayanan (2008) fra University of Texas i Austin noe annet. Kombinasjonen av karakterer, karakterdato og film for et individ danner et unikt filmfingeravtrykk. Tenk på din egen Netflix -oppførsel. Hvor mange tror du har sett det samme settet med filmer? Hvor mange så det samme settet med filmer samtidig?
Hovedspørsmålet, hvordan matcher dette fingeravtrykket? Det var ganske enkelt. Basert på informasjon fra det velkjente filmvurderingsnettstedet IMDb (Internet Movie Database), kan et lignende fingeravtrykk dannes. Følgelig kan individer identifiseres på nytt.
Selv om filmoppførsel kanskje ikke antas å være sensitiv informasjon, tenk på din egen oppførsel-ville du ha noe imot det hvis det ble offentliggjort? Eksempler som Narayanan ga i avisen hans er politiske preferanser (rangeringer om 'Jesus fra Nasaret' og 'Johannesevangeliet') og seksuelle preferanser (rangeringer på 'Bent' og 'Queer as folk') som lett kan destilleres.
GDPR er kanskje ikke superspennende, og heller ikke sølvkulen blant bloggtemaer. Likevel er det nyttig å få definisjonene rett når vi behandler personopplysninger. Siden denne bloggen handler om den vanlige misforståelsen om å fjerne kolonner som en måte å anonymisere data og utdanne deg som databehandler på, la oss starte med å utforske definisjonen av anonymisering i henhold til GDPR.
I følge betraktning 26 fra GDPR er anonymisert informasjon definert som:
'informasjon som ikke vedrører en identifisert eller identifiserbar fysisk person eller personopplysninger som er gjort anonyme på en slik måte at den registrerte ikke eller ikke lenger kan identifiseres.'
Siden man behandler personopplysninger som er knyttet til en fysisk person, er bare del 2 av definisjonen relevant. For å overholde definisjonen må man sikre at den registrerte (individuelle) ikke er eller ikke lenger kan identifiseres. Som angitt i denne bloggen, er det imidlertid bemerkelsesverdig enkelt å identifisere individer basert på noen få attributter. Så å fjerne navn fra et datasett er ikke i samsvar med GDPR -definisjonen av anonymisering.
Vi utfordret en vanlig og, dessverre, fortsatt ofte brukt tilnærming til dataanonymisering: fjerning av navn. I Guess Who -spillet og fire andre eksempler om:
det ble vist at fjerning av navn mislykkes som anonymisering. Selv om eksemplene er slående tilfeller, viser hver enkelheten ved omidentifisering og den potensielle negative innvirkningen på personvernet til enkeltpersoner.
Avslutningsvis resulterer ikke fjerning av navn fra datasettet ditt i anonyme data. Derfor unngår vi bedre å bruke begge begrepene om hverandre. Jeg håper inderlig at du ikke vil bruke denne tilnærmingen for anonymisering. Og hvis du fortsatt gjør det, må du sørge for at du og teamet ditt fullt ut forstår personvernrisikoen, og at du har lov til å godta disse risikoene på vegne av de berørte personene.
Kontakt Syntho og en av våre eksperter vil kontakte deg med lysets hastighet for å utforske verdien av syntetiske data!