

ຂໍ້ມູນສັງເຄາະແມ່ນຫຍັງ?
ຄໍາຕອບແມ່ນຂ້ອນຂ້າງງ່າຍດາຍ. ໃນຂະນະທີ່ຂໍ້ມູນຕົ້ນສະບັບໄດ້ຖືກເກັບກໍາໃນການໂຕ້ຕອບທັງຫມົດຂອງທ່ານກັບບຸກຄົນທີ່ແທ້ຈິງ (ເຊັ່ນ: ລູກຄ້າ, ຄົນເຈັບ, ພະນັກງານ, ແລະອື່ນໆ) ແລະໂດຍຜ່ານຂະບວນການພາຍໃນທັງຫມົດຂອງທ່ານ, ຂໍ້ມູນສັງເຄາະແມ່ນສ້າງຂຶ້ນໂດຍລະບົບຄອມພິວເຕີ. ສູດການຄິດໄລ່ຄອມພິວເຕີນີ້ສ້າງຈຸດຂໍ້ມູນໃຫມ່ ແລະປອມ.
ແກ້ໄຂສິ່ງທ້າທາຍດ້ານຄວາມເປັນສ່ວນຕົວຂອງຂໍ້ມູນ
ຂໍ້ມູນທີ່ຖືກສ້າງຂຶ້ນໂດຍສັງເຄາະປະກອບດ້ວຍຈຸດຂໍ້ມູນໃຫມ່ທັງຫມົດແລະປອມໂດຍບໍ່ມີການພົວພັນຫນຶ່ງຕໍ່ຫນຶ່ງກັບຂໍ້ມູນຕົ້ນສະບັບ. ດັ່ງນັ້ນ, ບໍ່ມີຈຸດຂໍ້ມູນສັງເຄາະໃດໆທີ່ສາມາດຕິດຕາມຄືນ ຫຼື ປ່ຽນແປງກັບຂໍ້ມູນຕົ້ນສະບັບໄດ້. ດັ່ງນັ້ນ, ຂໍ້ມູນສັງເຄາະໄດ້ຖືກຍົກເວັ້ນຈາກກົດລະບຽບຄວາມເປັນສ່ວນຕົວ, ເຊັ່ນ GDPR ແລະເຮັດຫນ້າທີ່ເປັນການແກ້ໄຂເພື່ອແກ້ໄຂແລະເອົາຊະນະສິ່ງທ້າທາຍດ້ານຄວາມເປັນສ່ວນຕົວ.
ເພີ່ມຂຶ້ນແລະຈໍາລອງ
ລັກສະນະທົ່ວໄປຂອງການຜະລິດຂໍ້ມູນສັງເຄາະອະນຸຍາດໃຫ້ຂະຫຍາຍແລະຈໍາລອງຂໍ້ມູນໃຫມ່ຢ່າງສົມບູນ. ນີ້ເຮັດຫນ້າທີ່ເປັນການແກ້ໄຂໃນເວລາທີ່ທ່ານມີຂໍ້ມູນບໍ່ພຽງພໍ (ຂໍ້ມູນຂາດແຄນ), ຕ້ອງການຍົກຕົວຢ່າງ edge-cases ຫຼືໃນເວລາທີ່ທ່ານບໍ່ມີຂໍ້ມູນເທື່ອ.
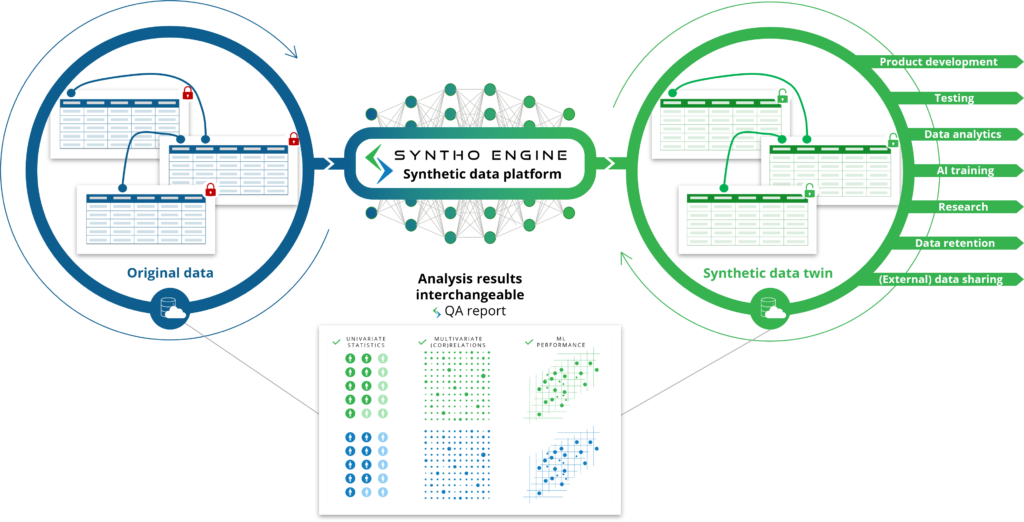
ຢູ່ທີ່ນີ້, ຈຸດສຸມຂອງ Syntho ແມ່ນຂໍ້ມູນທີ່ມີໂຄງສ້າງ (ຂໍ້ມູນຖືກຈັດຮູບແບບຢູ່ໃນຕາຕະລາງທີ່ບັນຈຸແຖວແລະຖັນ, ຄືກັບທີ່ເຈົ້າເຫັນຢູ່ໃນແຜ່ນ Excel), ແຕ່ພວກເຮົາມັກສະແດງແນວຄວາມຄິດຂອງຂໍ້ມູນສັງເຄາະຜ່ານຮູບພາບ, ເພາະວ່າມັນເປັນສິ່ງທີ່ດຶງດູດກວ່າ.
ສາມປະເພດຂອງຂໍ້ມູນສັງເຄາະມີຢູ່ໃນ umbrella ຂໍ້ມູນສັງເຄາະ. ຂໍ້ມູນສັງເຄາະ 3 ປະເພດຄື: ຂໍ້ມູນປອມ, ຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນຕາມກົດເກນ ແລະ ຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນໂດຍປັນຍາປະດິດ (AI). ພວກເຮົາອະທິບາຍສັ້ນໆວ່າ 3 ປະເພດຂໍ້ມູນສັງເຄາະທີ່ແຕກຕ່າງກັນແມ່ນຫຍັງ.
ຂໍ້ມູນ dummy ແມ່ນຂໍ້ມູນທີ່ສ້າງຂຶ້ນແບບສຸ່ມ (ຕົວຢ່າງ: ໂດຍເຄື່ອງສ້າງຂໍ້ມູນ mock).
ດັ່ງນັ້ນ, ຄຸນລັກສະນະ, ການພົວພັນແລະຮູບແບບສະຖິຕິທີ່ມີຢູ່ໃນຂໍ້ມູນຕົ້ນສະບັບບໍ່ໄດ້ຖືກເກັບຮັກສາໄວ້, ຈັບແລະຜະລິດຄືນໃຫມ່ໃນຂໍ້ມູນ dummy ທີ່ສ້າງຂຶ້ນ. ດັ່ງນັ້ນ, ການເປັນຕົວແທນຂອງຂໍ້ມູນ dummy / ຂໍ້ມູນ mock ແມ່ນຫນ້ອຍເມື່ອປຽບທຽບກັບຂໍ້ມູນຕົ້ນສະບັບ.
ຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນຕາມກົດລະບຽບແມ່ນຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນໂດຍກົດລະບຽບທີ່ກໍານົດໄວ້ກ່ອນ. ຕົວຢ່າງຂອງກົດລະບຽບທີ່ໄດ້ກໍານົດໄວ້ລ່ວງຫນ້າອາດຈະເປັນວ່າທ່ານຕ້ອງການຂໍ້ມູນສັງເຄາະທີ່ມີມູນຄ່າຕໍ່າສຸດທີ່ແນ່ນອນ, ຄ່າສູງສຸດຫຼືຄ່າສະເລ່ຍ. ຄຸນລັກສະນະ, ການພົວພັນແລະຮູບແບບສະຖິຕິໃດໆ, ທີ່ທ່ານຕ້ອງການຜະລິດຄືນໃຫມ່ໃນຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນຕາມກົດລະບຽບ, ຈໍາເປັນຕ້ອງໄດ້ກໍານົດໄວ້ລ່ວງຫນ້າ.
ດັ່ງນັ້ນ, ຄຸນນະພາບຂອງຂໍ້ມູນຈະດີເທົ່າກັບກົດລະບຽບທີ່ກໍານົດໄວ້ກ່ອນ. ນີ້ສົ່ງຜົນໃຫ້ສິ່ງທ້າທາຍໃນເວລາທີ່ຄຸນນະພາບຂໍ້ມູນສູງແມ່ນສໍາຄັນ. ກ່ອນອື່ນ ໝົດ, ຄົນເຮົາສາມາດ ກຳ ນົດກົດລະບຽບທີ່ ຈຳ ກັດທີ່ຈະຖືກຈັບໃນຂໍ້ມູນສັງເຄາະ. ນອກຈາກນັ້ນ, ໂດຍທົ່ວໄປແລ້ວ, ການຕັ້ງຄ່າຫຼາຍກົດລະບຽບຈະເຮັດໃຫ້ເກີດການທັບຊ້ອນກັນແລະຂັດແຍ້ງກັນ. ຍິ່ງໄປກວ່ານັ້ນ, ທ່ານຈະບໍ່ເຄີຍກວມເອົາກົດລະບຽບທີ່ກ່ຽວຂ້ອງທັງຫມົດ. ນອກຈາກນັ້ນ, ອາດຈະມີກົດລະບຽບທີ່ກ່ຽວຂ້ອງທີ່ເຈົ້າບໍ່ຮູ້ເຖິງ. ແລະສຸດທ້າຍ (ແລະບໍ່ລືມ), ນີ້ຈະໃຊ້ເວລາຫຼາຍແລະພະລັງງານທີ່ເຮັດໃຫ້ເກີດການແກ້ໄຂທີ່ບໍ່ມີປະສິດທິພາບ.
ຕາມທີ່ທ່ານຄາດຫວັງຈາກຊື່, ຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນໂດຍປັນຍາປະດິດ (AI) ແມ່ນຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນໂດຍລະບົບປັນຍາປະດິດ (AI) algorithm. ຮູບແບບ AI ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນຕົ້ນສະບັບເພື່ອຮຽນຮູ້ຄຸນລັກສະນະ, ການພົວພັນແລະຮູບແບບສະຖິຕິທັງຫມົດ. ຫຼັງຈາກນັ້ນ, ສູດການຄິດໄລ່ AI ນີ້ສາມາດສ້າງຈຸດຂໍ້ມູນໃຫມ່ຢ່າງສົມບູນແລະສ້າງແບບຈໍາລອງຈຸດຂໍ້ມູນໃຫມ່ເຫຼົ່ານັ້ນໃນລັກສະນະທີ່ມັນຜະລິດລັກສະນະ, ຄວາມສໍາພັນແລະຮູບແບບສະຖິຕິຈາກຊຸດຂໍ້ມູນຕົ້ນສະບັບ. ນີ້ແມ່ນສິ່ງທີ່ພວກເຮົາເອີ້ນວ່າຄູ່ແຝດຂໍ້ມູນສັງເຄາະ.
ແບບຈໍາລອງ AI mimics ຂໍ້ມູນຕົ້ນສະບັບເພື່ອສ້າງຄູ່ແຝດຂໍ້ມູນສັງເຄາະທີ່ສາມາດນໍາໃຊ້ໄດ້ຖ້າຫາກວ່າມັນເປັນຂໍ້ມູນຕົ້ນສະບັບ. ນີ້ປົດລັອກກໍລະນີການນໍາໃຊ້ຕ່າງໆທີ່ຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI ສາມາດນໍາໃຊ້ເປັນທາງເລືອກສໍາລັບການນໍາໃຊ້ຂໍ້ມູນຕົ້ນສະບັບ (sensitive), ເຊັ່ນ: ການນໍາໃຊ້ຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນ AI ເປັນຂໍ້ມູນການທົດສອບ, ຂໍ້ມູນຕົວຢ່າງຫຼືສໍາລັບການວິເຄາະ.
ໃນການປຽບທຽບກັບຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນຕາມກົດລະບຽບ: ແທນທີ່ຈະເຈົ້າສຶກສາແລະກໍານົດກົດລະບຽບທີ່ກ່ຽວຂ້ອງ, ສູດການຄິດໄລ່ AI ຈະເຮັດສິ່ງນີ້ໂດຍອັດຕະໂນມັດສໍາລັບທ່ານ. ໃນທີ່ນີ້, ບໍ່ພຽງແຕ່ຄຸນລັກສະນະ, ການພົວພັນແລະຮູບແບບສະຖິຕິທີ່ເຈົ້າຮູ້ຈະຖືກປົກຄຸມ, ຄຸນລັກສະນະ, ການພົວພັນແລະຮູບແບບສະຖິຕິທີ່ເຈົ້າບໍ່ຮູ້ແມ່ນຍັງຈະຖືກປົກຄຸມ.
ອີງຕາມກໍລະນີການນໍາໃຊ້ຂອງທ່ານ, ການປະສົມປະສານຂອງຂໍ້ມູນ dummy / ຂໍ້ມູນ mock, ຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍກົດລະບຽບຫຼືຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນໂດຍປັນຍາປະດິດ (AI) ແມ່ນແນະນໍາ. ພາບລວມນີ້ໃຫ້ຕົວຊີ້ບອກທຳອິດວ່າປະເພດໃດແດ່ຂອງຂໍ້ມູນສັງເຄາະທີ່ຈະໃຊ້. ໃນຖານະເປັນ Syntho ສະຫນັບສະຫນູນພວກເຂົາທັງຫມົດ, ກະລຸນາຕິດຕໍ່ຫາຜູ້ຊ່ຽວຊານຂອງພວກເຮົາເພື່ອເຈາະເລິກກໍລະນີການນໍາໃຊ້ຂອງທ່ານກັບພວກເຮົາ.
