


ຂໍ້ມູນສັງເຄາະທີ່ສ້າງຂຶ້ນໂດຍ Syntho ໄດ້ຖືກປະເມີນ, ກວດສອບ ແລະອະນຸມັດຈາກມຸມເບິ່ງພາຍນອກ ແລະຈຸດປະສົງໂດຍຜູ້ຊ່ຽວຊານດ້ານຂໍ້ມູນຂອງ SAS.
ເຖິງແມ່ນວ່າ Syntho ມີຄວາມພູມໃຈທີ່ຈະສະເຫນີໃຫ້ຜູ້ຊົມໃຊ້ມີບົດລາຍງານການຮັບປະກັນຄຸນນະພາບຂັ້ນສູງ, ພວກເຮົາຍັງເຂົ້າໃຈເຖິງຄວາມສໍາຄັນຂອງການປະເມີນພາຍນອກແລະຈຸດປະສົງຂອງຂໍ້ມູນສັງເຄາະຂອງພວກເຮົາຈາກຜູ້ນໍາອຸດສາຫະກໍາ. ນັ້ນແມ່ນເຫດຜົນທີ່ພວກເຮົາຮ່ວມມືກັບ SAS, ຜູ້ນໍາໃນການວິເຄາະ, ເພື່ອປະເມີນຂໍ້ມູນສັງເຄາະຂອງພວກເຮົາ.
SAS ດໍາເນີນການປະເມີນຜົນຢ່າງລະອຽດຕ່າງໆກ່ຽວກັບຄວາມຖືກຕ້ອງຂອງຂໍ້ມູນ, ການປົກປ້ອງຄວາມເປັນສ່ວນຕົວ, ແລະການນໍາໃຊ້ຂອງຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI ຂອງ Syntho ໃນການປຽບທຽບກັບຂໍ້ມູນຕົ້ນສະບັບ. ເປັນການສະຫລຸບ, SAS ໄດ້ປະເມີນແລະອະນຸມັດຂໍ້ມູນສັງເຄາະຂອງ Syntho ວ່າຖືກຕ້ອງ, ປອດໄພ, ແລະສາມາດໃຊ້ໄດ້ເມື່ອປຽບທຽບກັບຂໍ້ມູນຕົ້ນສະບັບ.
ພວກເຮົາໄດ້ໃຊ້ຂໍ້ມູນໂທລະຄົມທີ່ໃຊ້ສໍາລັບ "churn" ການຄາດຄະເນເປັນຂໍ້ມູນເປົ້າຫມາຍ. ເປົ້າໝາຍຂອງການປະເມີນແມ່ນເພື່ອນຳໃຊ້ຂໍ້ມູນສັງເຄາະເພື່ອຝຶກຝົນແບບຄາດຄະຕິຕ່າງໆ ແລະ ປະເມີນປະສິດທິພາບຂອງແຕ່ລະຕົວແບບ. ເນື່ອງຈາກການຄາດຄະເນການປັ່ນປ່ວນແມ່ນວຽກງານການຈັດປະເພດ, SAS ໄດ້ເລືອກຮູບແບບການຈັດປະເພດທີ່ນິຍົມເພື່ອເຮັດໃຫ້ການຄາດຄະເນ, ລວມທັງ:
ກ່ອນທີ່ຈະສ້າງຂໍ້ມູນສັງເຄາະ, SAS ແບ່ງຊຸດຂໍ້ມູນໂທລະຄົມແບບສຸ່ມອອກເປັນຊຸດລົດໄຟ (ສໍາລັບການຝຶກອົບຮົມແບບຈໍາລອງ) ແລະຊຸດຄ້າງ (ສໍາລັບການໃຫ້ຄະແນນແບບຈໍາລອງ). ການມີຊຸດຄ້າງໄວ້ແຍກຕ່າງຫາກສໍາລັບການໃຫ້ຄະແນນຊ່ວຍໃຫ້ມີການປະເມີນທີ່ບໍ່ເປັນກາງວ່າຮູບແບບການຈັດປະເພດອາດຈະເຮັດແນວໃດດີເມື່ອນໍາໃຊ້ກັບຂໍ້ມູນໃຫມ່.
ໂດຍໃຊ້ຊຸດລົດໄຟເປັນວັດສະດຸປ້ອນ, Syntho ໄດ້ໃຊ້ເຄື່ອງຈັກ Syntho ເພື່ອສ້າງຊຸດຂໍ້ມູນສັງເຄາະ. ສໍາລັບ benchmarking, SAS ຍັງໄດ້ສ້າງສະບັບພາສາທີ່ບໍ່ເປີດເຜີຍຊື່ຂອງລົດໄຟທີ່ກໍານົດໄວ້ຫຼັງຈາກການນໍາໃຊ້ເຕັກນິກການປິດບັງຊື່ຕ່າງໆເພື່ອບັນລຸເປົ້າຫມາຍສະເພາະໃດຫນຶ່ງ (ຂອງ k-anonymity). ຂັ້ນຕອນທີ່ຜ່ານມາໄດ້ເຮັດໃຫ້ມີສີ່ຊຸດຂໍ້ມູນ:
ຊຸດຂໍ້ມູນ 1, 3 ແລະ 4 ໄດ້ຖືກນໍາໃຊ້ເພື່ອຝຶກອົບຮົມແຕ່ລະຮູບແບບການຈັດປະເພດ, ຜົນໄດ້ຮັບ 12 (3 x 4) ແບບຝຶກອົບຮົມ. ຕໍ່ມາ SAS ໄດ້ນໍາໃຊ້ຊຸດຂໍ້ມູນການຍຶດຖືເພື່ອວັດແທກຄວາມຖືກຕ້ອງຂອງແຕ່ລະແບບຈໍາລອງໃນການຄາດຄະເນການປັ່ນປ່ວນຂອງລູກຄ້າ.
SAS ດໍາເນີນການປະເມີນຜົນຢ່າງລະອຽດຕ່າງໆກ່ຽວກັບຄວາມຖືກຕ້ອງຂອງຂໍ້ມູນ, ການປົກປ້ອງຄວາມເປັນສ່ວນຕົວ, ແລະການນໍາໃຊ້ຂອງຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI ຂອງ Syntho ໃນການປຽບທຽບກັບຂໍ້ມູນຕົ້ນສະບັບ. ເປັນການສະຫລຸບ, SAS ໄດ້ປະເມີນແລະອະນຸມັດຂໍ້ມູນສັງເຄາະຂອງ Syntho ວ່າຖືກຕ້ອງ, ປອດໄພ, ແລະສາມາດໃຊ້ໄດ້ເມື່ອປຽບທຽບກັບຂໍ້ມູນຕົ້ນສະບັບ.
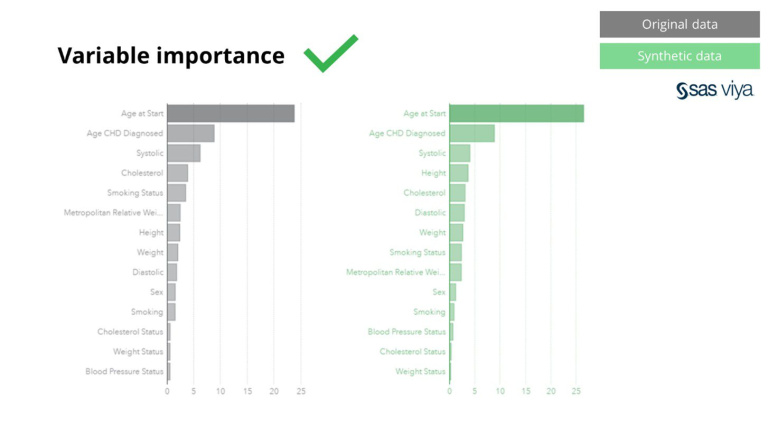
ຂໍ້ມູນສັງເຄາະຈາກ Syntho ຖືບໍ່ພຽງແຕ່ສໍາລັບຮູບແບບພື້ນຖານ, ມັນຍັງເກັບກໍາຮູບແບບສະຖິຕິທີ່ 'ເຊື່ອງໄວ້' ເລິກທີ່ຕ້ອງການສໍາລັບວຽກງານການວິເຄາະຂັ້ນສູງ. ອັນສຸດທ້າຍແມ່ນສະແດງໃຫ້ເຫັນຢູ່ໃນຕາຕະລາງແຖບ, ຊີ້ໃຫ້ເຫັນວ່າຄວາມຖືກຕ້ອງຂອງຕົວແບບທີ່ໄດ້ຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນສັງເຄາະທຽບກັບແບບຈໍາລອງທີ່ໄດ້ຮັບການຝຶກອົບຮົມຈາກຂໍ້ມູນຕົ້ນສະບັບແມ່ນຄ້າຍຄືກັນ. ດັ່ງນັ້ນ, ຂໍ້ມູນສັງເຄາະສາມາດຖືກນໍາໃຊ້ສໍາລັບການຝຶກອົບຮົມຕົວຈິງຂອງຕົວແບບ. ວັດສະດຸປ້ອນ ແລະ ຄວາມສໍາຄັນຕົວປ່ຽນແປງທີ່ເລືອກໂດຍລະບົບສູດການຄິດໄລ່ກ່ຽວກັບຂໍ້ມູນສັງເຄາະທຽບກັບຂໍ້ມູນຕົ້ນສະບັບແມ່ນຄ້າຍຄືກັນຫຼາຍ. ດັ່ງນັ້ນ, ມັນໄດ້ຖືກສະຫຼຸບວ່າຂະບວນການສ້າງແບບຈໍາລອງສາມາດເຮັດໄດ້ໃນຂໍ້ມູນສັງເຄາະ, ເປັນທາງເລືອກສໍາລັບການນໍາໃຊ້ຂໍ້ມູນທີ່ມີຄວາມອ່ອນໄຫວທີ່ແທ້ຈິງ.
ເຕັກນິກການປິດບັງຊື່ແບບຄລາສສິກມີຢູ່ທົ່ວໄປວ່າພວກເຂົາຈັດການຂໍ້ມູນຕົ້ນສະບັບເພື່ອຂັດຂວາງການຕິດຕາມບຸກຄົນ. ພວກເຂົາເຈົ້າ manipulate ຂໍ້ມູນແລະເຮັດໃຫ້ການທໍາລາຍຂໍ້ມູນໃນຂະບວນການ. ຍິ່ງເຈົ້າບໍ່ເປີດເຜີຍຕົວຕົນຫຼາຍເທົ່າໃດ, ຂໍ້ມູນຂອງທ່ານຈະຖືກປົກປ້ອງໄດ້ດີຂຶ້ນ, ແຕ່ກໍ່ຍິ່ງເຮັດໃຫ້ຂໍ້ມູນຂອງທ່ານຖືກທໍາລາຍຫຼາຍເທົ່າທີ່ຄວນ. ນີ້ແມ່ນຄວາມເສຍຫາຍໂດຍສະເພາະສໍາລັບວຽກງານ AI ແລະການສ້າງແບບຈໍາລອງທີ່ "ພະລັງງານການຄາດເດົາ" ເປັນສິ່ງຈໍາເປັນ, ເພາະວ່າຂໍ້ມູນທີ່ມີຄຸນນະພາບທີ່ບໍ່ດີຈະເຮັດໃຫ້ເກີດຄວາມເຂົ້າໃຈທີ່ບໍ່ດີຈາກຕົວແບບ AI. SAS ສະແດງໃຫ້ເຫັນນີ້, ໂດຍມີພື້ນທີ່ພາຍໃຕ້ເສັ້ນໂຄ້ງ (AUC*) ຢູ່ໃກ້ກັບ 0.5, ສະແດງໃຫ້ເຫັນວ່າຕົວແບບທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ປະຕິບັດໄດ້ຮ້າຍແຮງທີ່ສຸດ.
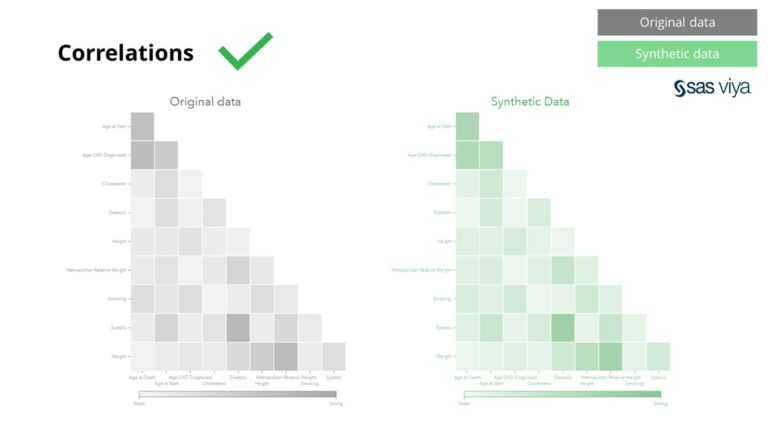
ການພົວພັນແລະຄວາມສໍາພັນລະຫວ່າງຕົວແປໄດ້ຖືກເກັບຮັກສາໄວ້ຢ່າງຖືກຕ້ອງໃນຂໍ້ມູນສັງເຄາະ.
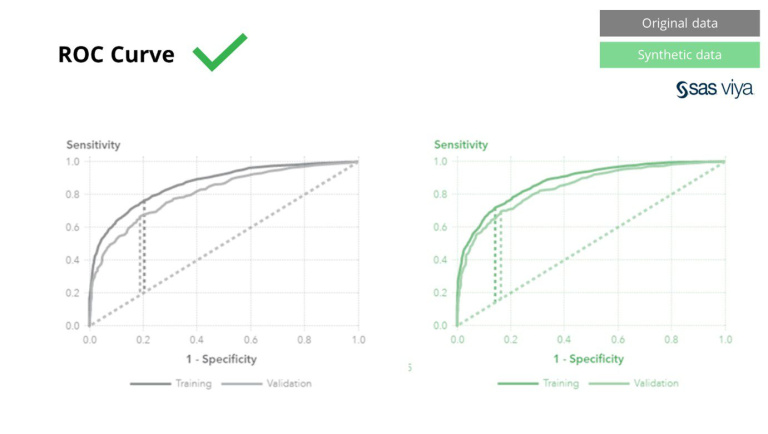
ພື້ນທີ່ພາຍໃຕ້ເສັ້ນໂຄ້ງ (AUC), metric ສໍາລັບການວັດແທກການປະຕິບັດຕົວແບບ, ຍັງຄົງສອດຄ່ອງ.
ຍິ່ງໄປກວ່ານັ້ນ, ຄວາມສໍາຄັນຂອງຕົວແປ, ເຊິ່ງຊີ້ໃຫ້ເຫັນເຖິງອໍານາດຄາດຄະເນຂອງຕົວແປໃນແບບຈໍາລອງ, ຍັງຄົງ intact ເມື່ອປຽບທຽບຂໍ້ມູນສັງເຄາະກັບຊຸດຂໍ້ມູນຕົ້ນສະບັບ.
ອີງຕາມການສັງເກດເຫຼົ່ານີ້ໂດຍ SAS ແລະໂດຍການນໍາໃຊ້ SAS Viya, ພວກເຮົາສາມາດສະຫຼຸບໄດ້ຢ່າງຫມັ້ນໃຈວ່າຂໍ້ມູນສັງເຄາະທີ່ຜະລິດໂດຍ Syntho Engine ແມ່ນທຽບກັບຂໍ້ມູນທີ່ແທ້ຈິງໃນດ້ານຄຸນນະພາບ. ນີ້ຢືນຢັນການນໍາໃຊ້ຂໍ້ມູນສັງເຄາະສໍາລັບການພັດທະນາແບບຈໍາລອງ, ປູທາງສໍາລັບການວິເຄາະຂັ້ນສູງດ້ວຍຂໍ້ມູນສັງເຄາະ.
