ຜູ້ກະທຳຜິດທີ່ບໍ່ເຫັນຂອງ AI: ແກ້ໄຂອະຄະຕິພາຍໃນ
ຊຸດ blog bias: ສ່ວນ 1
ການນໍາສະເຫນີ
ໃນໂລກຂອງພວກເຮົາທີ່ມີຮູບແບບປອມທີ່ນັບມື້ນັບເພີ່ມຂຶ້ນ, ເຄື່ອງຈັກທີ່ມີໜ້າທີ່ໃນການຕັດສິນໃຈທີ່ຊັບຊ້ອນນັບມື້ນັບແຜ່ຫຼາຍຂຶ້ນ. ມີການເຕີບໃຫຍ່ຂອງວັນນະຄະດີທີ່ຊີ້ໃຫ້ເຫັນເຖິງການນໍາໃຊ້ AI ໃນໂດເມນຕ່າງໆເຊັ່ນ: ທຸລະກິດ, ການຕັດສິນໃຈທີ່ມີຮຸ້ນສູງ, ແລະໃນໄລຍະສອງສາມປີຜ່ານມາໃນຂະແຫນງການແພດ. ດ້ວຍອັດຕາການຂະຫຍາຍຕົວນີ້, ຢ່າງໃດກໍຕາມ, ປະຊາຊົນໄດ້ສັງເກດເຫັນກ່ຽວກັບແນວໂນ້ມຂອງລະບົບດັ່ງກ່າວ; ນັ້ນແມ່ນ, ໃນຂະນະທີ່ຖືກອອກແບບໂດຍພື້ນຖານແລ້ວເພື່ອປະຕິບັດຕາມແບບຢ່າງໃນຂໍ້ມູນຢ່າງບໍລິສຸດ, ພວກເຂົາເຈົ້າໄດ້ສະແດງອາການຂອງຄວາມລໍາອຽງ, ໃນຄວາມຮູ້ສຶກວ່າພຶດຕິກໍາທາງເພດແລະການຈໍາແນກຕ່າງໆສາມາດສັງເກດເຫັນໄດ້. ທີ່ຜ່ານມາ ກົດໝາຍວ່າດ້ວຍ AI ຂອງເອີຣົບ, ຍັງກວມເອົາເລື່ອງຂອງຄວາມລໍາອຽງດັ່ງກ່າວຢ່າງກວ້າງຂວາງແລະກໍານົດພື້ນຖານສໍາລັບການແກ້ໄຂບັນຫາທີ່ກ່ຽວຂ້ອງກັບມັນ.
ຕະຫຼອດປີຂອງເອກະສານດ້ານວິຊາການ, ປະຊາຊົນມີແນວໂນ້ມທີ່ຈະໃຊ້ຄໍາວ່າ "ຄວາມລໍາອຽງ" ເພື່ອອະທິບາຍປະເພດຂອງພຶດຕິກໍາທີ່ຫຼອກລວງນີ້ຕໍ່ກັບປະຊາກອນບາງ; ຄໍາທີ່ມີຄວາມຫມາຍແຕກຕ່າງກັນ, ເຮັດໃຫ້ເກີດຄວາມສັບສົນແລະສັບສົນໃນການແກ້ໄຂ.
ບົດຄວາມນີ້ແມ່ນຄັ້ງທໍາອິດໃນຊຸດຂອງບົດຄວາມ blog ທີ່ກວມເອົາຫົວຂໍ້ຂອງຄວາມລໍາອຽງ. ໃນຊຸດນີ້, ພວກເຮົາຈະມຸ່ງເນັ້ນໃຫ້ທ່ານເຂົ້າໃຈຢ່າງຈະແຈ້ງກ່ຽວກັບຄວາມລຳອຽງໃນ AI. ພວກເຮົາຈະແນະນໍາວິທີການວັດແທກແລະຫຼຸດຜ່ອນຄວາມລໍາອຽງແລະຄົ້ນຫາບົດບາດຂອງຂໍ້ມູນສັງເຄາະໃນເສັ້ນທາງນີ້ໄປສູ່ລະບົບຍຸດຕິທໍາຫຼາຍຂຶ້ນ. ນອກຈາກນັ້ນ, ພວກເຮົາຍັງຈະໃຫ້ທ່ານກວດເບິ່ງວ່າ Syntho, ຜູ້ຫຼິ້ນຊັ້ນນໍາໃນການຜະລິດຂໍ້ມູນສັງເຄາະ, ສາມາດປະກອບສ່ວນເຂົ້າໃນຄວາມພະຍາຍາມນີ້ໄດ້ແນວໃດ. ດັ່ງນັ້ນ, ບໍ່ວ່າທ່ານຈະເປັນຜູ້ປະຕິບັດທີ່ຊອກຫາຄວາມເຂົ້າໃຈທີ່ປະຕິບັດໄດ້ຫຼືພຽງແຕ່ຢາກຮູ້ກ່ຽວກັບຫົວຂໍ້ນີ້, ທ່ານຢູ່ໃນສະຖານທີ່ທີ່ເຫມາະສົມ.
ຄວາມລຳອຽງໃນການປະຕິບັດ: ຕົວຢ່າງຂອງໂລກທີ່ແທ້ຈິງ
ທ່ານອາດຈະສົງໄສວ່າ, "ຄວາມລໍາອຽງນີ້ໃນ AI ແມ່ນສໍາຄັນທັງຫມົດ, ແຕ່ມັນຫມາຍຄວາມວ່າແນວໃດສໍາລັບຂ້ອຍ, ສໍາລັບຄົນທໍາມະດາ?" ຄວາມຈິງແມ່ນ, ຜົນກະທົບແມ່ນໄກເຖິງ, ມັກຈະເບິ່ງບໍ່ເຫັນແຕ່ມີທ່າແຮງ. ຄວາມລໍາອຽງໃນ AI ບໍ່ແມ່ນແນວຄວາມຄິດທາງວິຊາການເທົ່ານັ້ນ; ມັນເປັນບັນຫາຂອງໂລກທີ່ແທ້ຈິງທີ່ມີຜົນສະທ້ອນທີ່ຮ້າຍແຮງ.
ເອົາເລື່ອງຫຍໍ້ທໍ້ກ່ຽວກັບສະຫວັດດີການເດັກຊາວໂຮນລັງເປັນຕົວຢ່າງ. ລະບົບອັດຕະໂນມັດ, ຄາດວ່າເປັນເຄື່ອງມືທີ່ສ້າງຂຶ້ນເພື່ອສ້າງຜົນໄດ້ຮັບທີ່ຍຸຕິທໍາແລະມີປະສິດທິພາບດ້ວຍການແຊກແຊງຂອງມະນຸດຫນ້ອຍທີ່ສຸດ, ມີຄວາມລໍາອຽງ. ມັນຕິດທຸງພໍ່ແມ່ຫຼາຍພັນຄົນຢ່າງຜິດໆກ່ຽວກັບການສໍ້ໂກງໂດຍອີງໃສ່ຂໍ້ມູນທີ່ບໍ່ຖືກຕ້ອງ ແລະສົມມຸດຕິຖານ. ຜົນ? ຄອບຄົວທີ່ຕົກຢູ່ໃນຄວາມວຸ້ນວາຍ, ຊື່ສຽງສ່ວນຕົວເສຍຫາຍ, ແລະຄວາມລຳບາກດ້ານການເງິນ, ທັງໝົດແມ່ນຍ້ອນຄວາມລຳອຽງໃນລະບົບ AI. ມັນເປັນຕົວຢ່າງເຊັ່ນນີ້ທີ່ຊີ້ໃຫ້ເຫັນຄວາມຮີບດ່ວນຂອງການແກ້ໄຂຄວາມບໍ່ລໍາອຽງໃນ AI.

ທີ່ມາ: “Compensatie ouders toeslagenaffaire kan zomaar tot 2030 duren”, 2023. ສະຫະລັດ
ແຕ່ໃຫ້ເຮົາບໍ່ຢຸດຢູ່ທີ່ນັ້ນ. ເຫດການນີ້ບໍ່ແມ່ນກໍລະນີທີ່ໂດດດ່ຽວຂອງການມີອະຄະຕິທີ່ເຮັດໃຫ້ເກີດຄວາມເສຍຫາຍ. ຜົນກະທົບຂອງຄວາມລໍາອຽງໃນ AI ຂະຫຍາຍໄປສູ່ທຸກມຸມຂອງຊີວິດຂອງພວກເຮົາ. ຈາກຜູ້ທີ່ໄດ້ຮັບການຈ້າງສໍາລັບວຽກເຮັດງານທໍາ, ຜູ້ທີ່ໄດ້ຮັບການອະນຸມັດສໍາລັບການກູ້ຢືມເງິນ, ກັບຜູ້ທີ່ໄດ້ຮັບການປິ່ນປົວທາງການແພດປະເພດໃດ - ລະບົບ AI ທີ່ມີຄວາມລໍາອຽງສາມາດສືບຕໍ່ຄວາມບໍ່ສະເຫມີພາບທີ່ມີຢູ່ແລະສ້າງໃຫມ່.
ພິຈາລະນາເລື່ອງນີ້: ລະບົບ AI ທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນປະຫວັດສາດທີ່ມີຄວາມລໍາອຽງສາມາດປະຕິເສດຜູ້ສະຫມັກທີ່ມີຄຸນວຸດທິທີ່ດີທີ່ຈະເຮັດວຽກພຽງແຕ່ຍ້ອນເພດຫຼືຊົນເຜົ່າຂອງເຂົາເຈົ້າ. ຫຼືລະບົບ AI ທີ່ມີຄວາມລໍາອຽງອາດຈະປະຕິເສດການກູ້ຢືມເງິນໃຫ້ກັບຜູ້ສະຫມັກທີ່ສົມຄວນຍ້ອນລະຫັດໄປສະນີຂອງພວກເຂົາ. ເຫຼົ່ານີ້ແມ່ນບໍ່ພຽງແຕ່ສະຖານະການສົມມຸດຕິຖານ; ພວກເຂົາກໍາລັງເກີດຂຶ້ນໃນປັດຈຸບັນ.
ປະເພດຄວາມລຳອຽງສະເພາະ, ເຊັ່ນ: ຄວາມລຳອຽງທາງປະຫວັດສາດ ແລະ ຄວາມລຳອຽງໃນການວັດແທກ, ນໍາໄປສູ່ການຕັດສິນໃຈທີ່ຜິດພາດດັ່ງກ່າວ. ພວກເຂົາເຈົ້າແມ່ນປະກົດຂຶ້ນຢູ່ໃນຂໍ້ມູນ, ຮາກຖານຢ່າງເລິກເຊິ່ງຢູ່ໃນຄວາມລໍາອຽງຂອງສັງຄົມ, ແລະສະທ້ອນໃຫ້ເຫັນໃນຜົນໄດ້ຮັບທີ່ບໍ່ເທົ່າທຽມກັນລະຫວ່າງກຸ່ມປະຊາກອນທີ່ແຕກຕ່າງກັນ. ພວກເຂົາສາມາດ skew ການຕັດສິນໃຈຂອງຮູບແບບການຄາດເດົາແລະສົ່ງຜົນໃຫ້ການປິ່ນປົວທີ່ບໍ່ຍຸດຕິທໍາ.
ໃນໂຄງການອັນໃຫຍ່ຫຼວງຂອງສິ່ງຕ່າງໆ, ຄວາມລໍາອຽງໃນ AI ສາມາດເຮັດຫນ້າທີ່ເປັນອິດທິພົນທີ່ງຽບໆ, ການສ້າງສັງຄົມແລະຊີວິດຂອງພວກເຮົາຢ່າງອ່ອນໂຍນ, ເລື້ອຍໆໃນວິທີທີ່ພວກເຮົາບໍ່ຮູ້. ທຸກຈຸດທີ່ກ່າວມາຂ້າງເທິງນີ້ອາດເຮັດໃຫ້ເຈົ້າມີຄຳຖາມວ່າ ເປັນຫຍັງຈິ່ງບໍ່ດຳເນີນການເພື່ອຢຸດ, ແລະມັນເປັນໄປໄດ້ບໍ່.
ແທ້ຈິງແລ້ວ, ດ້ວຍຄວາມກ້າວຫນ້າທາງດ້ານເຕັກໂນໂລຢີໃຫມ່, ມັນໄດ້ກາຍເປັນການເຂົ້າເຖິງຫຼາຍກວ່າເກົ່າເພື່ອແກ້ໄຂບັນຫາດັ່ງກ່າວ. ຂັ້ນຕອນທໍາອິດເພື່ອແກ້ໄຂບັນຫານີ້, ຢ່າງໃດກໍຕາມ, ແມ່ນເພື່ອເຂົ້າໃຈແລະຮັບຮູ້ການມີຢູ່ແລະຜົນກະທົບຂອງມັນ. ສໍາລັບໃນປັດຈຸບັນ, ການຮັບຮູ້ເຖິງການມີຢູ່ຂອງມັນໄດ້ຖືກສ້າງຂື້ນ, ເຮັດໃຫ້ເລື່ອງຂອງ "ຄວາມເຂົ້າໃຈ" ຍັງຄົງຂ້ອນຂ້າງບໍ່ຊັດເຈນ.
ຄວາມເຂົ້າໃຈ Bias
ໃນຂະນະທີ່ຄໍານິຍາມຕົ້ນສະບັບຂອງຄວາມລໍາອຽງທີ່ນໍາສະເຫນີໂດຍ ວັດຈະນານຸກົມ Cambridge ບໍ່ stray ໄກເກີນໄປຈາກຈຸດປະສົງຕົ້ນຕໍຂອງຄໍາສັບຕ່າງໆຍ້ອນວ່າມັນກ່ຽວຂ້ອງກັບ AI, ການຕີຄວາມຫມາຍທີ່ແຕກຕ່າງກັນຫຼາຍແມ່ນຈະຕ້ອງເຮັດໃຫ້ເຖິງແມ່ນຄໍານິຍາມຄໍານີ້. Taxonomies, ເຊັ່ນທີ່ນໍາສະເຫນີໂດຍນັກຄົ້ນຄວ້າເຊັ່ນ: Hellström et al (2020) ແລະ Kliegr (2021), ສະຫນອງຄວາມເຂົ້າໃຈເລິກເຂົ້າໄປໃນຄໍານິຍາມຂອງຄວາມລໍາອຽງ. ການເບິ່ງທີ່ງ່າຍດາຍຢູ່ໃນເອກະສານເຫຼົ່ານີ້ຈະເປີດເຜີຍໃຫ້ເຫັນ, ແນວໃດກໍ່ຕາມ, ການຈໍາກັດຄວາມຫນາແຫນ້ນຂອງຄໍານິຍາມຂອງຄໍາສັບແມ່ນຈໍາເປັນເພື່ອແກ້ໄຂບັນຫາປະສິດທິຜົນ.
ໃນຂະນະທີ່ເປັນການປ່ຽນແປງຂອງກິດຈະກໍາ, ໃນຄໍາສັ່ງທີ່ດີທີ່ສຸດກໍານົດແລະສະແດງຄວາມຫມາຍຂອງອະຄະຕິທີ່ສາມາດກໍານົດທີ່ກົງກັນຂ້າມໄດ້ດີກວ່າ, ນັ້ນແມ່ນຄວາມຍຸດຕິທໍາ.
ນິຍາມຄວາມຍຸດຕິທຳ
ຍ້ອນວ່າມັນຖືກກໍານົດໄວ້ໃນວັນນະຄະດີທີ່ຜ່ານມາຕ່າງໆເຊັ່ນ: Castelnovo et al. (2022), ຄວາມຍຸຕິທໍາສາມາດໄດ້ຮັບການອະທິບາຍລະອຽດຕາມຄວາມເຂົ້າໃຈຂອງຄໍາວ່າພື້ນທີ່ທີ່ມີທ່າແຮງ. ຍ້ອນວ່າມັນມີຢູ່, ພື້ນທີ່ທີ່ມີທ່າແຮງ (PS) ຫມາຍເຖິງຂອບເຂດຄວາມສາມາດແລະຄວາມຮູ້ຂອງບຸກຄົນໂດຍບໍ່ຄໍານຶງເຖິງກຸ່ມປະຊາກອນທີ່ແນ່ນອນ. ດ້ວຍຄໍານິຍາມຂອງແນວຄວາມຄິດຂອງ PS ນີ້, ຄົນເຮົາສາມາດກໍານົດຄວາມຍຸຕິທໍາໄດ້ຢ່າງງ່າຍດາຍເພື່ອຄວາມສະເຫມີພາບຂອງການປິ່ນປົວລະຫວ່າງສອງບຸກຄົນທີ່ມີ PS ເທົ່າທຽມກັນ, ໂດຍບໍ່ຄໍານຶງເຖິງຄວາມແຕກຕ່າງທີ່ສັງເກດເຫັນແລະເຊື່ອງໄວ້ໃນຄວາມລໍາອຽງ inducing ພາລາມິເຕີ (ເຊັ່ນ: ເຊື້ອຊາດ, ອາຍຸ, ຫຼືເພດ). ການຫັນປ່ຽນໃດໆຈາກຄໍານິຍາມນີ້, ຍັງເອີ້ນວ່າຄວາມສະເຫມີພາບຂອງໂອກາດ, ເປັນຕົວຊີ້ບອກທີ່ຊັດເຈນຂອງຄວາມລໍາອຽງແລະຄວາມດີທີ່ຈະສືບສວນຕື່ມອີກ.
ຜູ້ປະຕິບັດໃນບັນດາຜູ້ອ່ານອາດຈະສັງເກດເຫັນວ່າການບັນລຸບາງສິ່ງບາງຢ່າງຕາມທີ່ໄດ້ກໍານົດໄວ້ໃນທີ່ນີ້ອາດຈະເປັນໄປບໍ່ໄດ້ຢ່າງສົມບູນຍ້ອນຄວາມລໍາອຽງທີ່ມີຢູ່ແລ້ວໃນໂລກຂອງພວກເຮົາ. ນັ້ນແມ່ນຄວາມຈິງ! ໂລກທີ່ພວກເຮົາອາໄສຢູ່, ພ້ອມກັບຂໍ້ມູນທັງຫມົດທີ່ເກັບກໍາຈາກການປະກົດຕົວໃນໂລກນີ້, ແມ່ນຂຶ້ນກັບຄວາມລໍາອຽງທາງປະຫວັດສາດແລະສະຖິຕິຫຼາຍ. ນີ້, ແທ້ຈິງແລ້ວ, ຫຼຸດຜ່ອນຄວາມຫມັ້ນໃຈໃນມື້ຫນຶ່ງຢ່າງເຕັມສ່ວນຫຼຸດຜ່ອນຜົນກະທົບຂອງຄວາມລໍາອຽງຕໍ່ຕົວແບບຄາດຄະເນທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນ "ອະຄະຕິ" ດັ່ງກ່າວ. ຢ່າງໃດກໍ່ຕາມ, ໂດຍຜ່ານການນໍາໃຊ້ວິທີການຕ່າງໆ, ຫນຶ່ງສາມາດພະຍາຍາມຫຼຸດຜ່ອນຜົນກະທົບຂອງຄວາມລໍາອຽງ. ນີ້ແມ່ນກໍລະນີ, ຄໍາທີ່ໃຊ້ໃນສ່ວນທີ່ເຫຼືອຂອງບົດຄວາມ blog ນີ້ຈະປ່ຽນໄປສູ່ຄວາມຄິດຂອງການຫຼຸດຜ່ອນຜົນກະທົບຂອງຄວາມລໍາອຽງແທນທີ່ຈະຫຼຸດຜ່ອນມັນຢ່າງເຕັມສ່ວນ.
ໂອເຄ! ສະນັ້ນ, ຕອນນີ້ແນວຄວາມຄິດໄດ້ຖືກນໍາອອກມາວ່າຄວາມລໍາອຽງແມ່ນຫຍັງແລະວິທີທີ່ຄົນເຮົາສາມາດປະເມີນຄວາມເປັນໄປໄດ້ຂອງມັນ; ຢ່າງໃດກໍຕາມ, ຖ້າພວກເຮົາຕ້ອງການແກ້ໄຂບັນຫາຢ່າງຖືກຕ້ອງ, ພວກເຮົາຈໍາເປັນຕ້ອງຮູ້ວ່າຄວາມລໍາອຽງທັງຫມົດເຫຼົ່ານີ້ມາຈາກໃສ.
ເຂົ້າໃຈແຫຼ່ງແລະປະເພດ
ການຄົ້ນຄວ້າທີ່ມີຢູ່ແລ້ວໃຫ້ຄວາມເຂົ້າໃຈທີ່ມີຄຸນຄ່າໃນປະເພດຂອງຄວາມລໍາອຽງທີ່ແຕກຕ່າງກັນໃນການຮຽນຮູ້ເຄື່ອງຈັກ. ເປັນ Mehrabi ແລະ. al. (2019) ໄດ້ດໍາເນີນການແບ່ງຄວາມລໍາອຽງໃນການຮຽນຮູ້ເຄື່ອງຈັກ, ຫນຶ່ງສາມາດແບ່ງອະຄະຕິເປັນ 3 ປະເພດໃຫຍ່. ຄືຂອງ:
- Data to Algorithm: a category encomapssing biases ທີ່ມາຈາກຂໍ້ມູນເອງ. ອາດເກີດມາຈາກການເກັບກຳຂໍ້ມູນທີ່ບໍ່ດີ, ຄວາມລຳອຽງທີ່ມີຢູ່ແລ້ວໃນໂລກ, ແລະອື່ນໆ.
- Algorithm ກັບຜູ້ໃຊ້: ປະເພດທີ່ເນັ້ນໃສ່ຄວາມລໍາອຽງທີ່ມາຈາກການອອກແບບແລະການເຮັດວຽກຂອງ algorithms. ມັນລວມເຖິງວິທີການຕີຄວາມໝາຍ, ການຊັ່ງນໍ້າໜັກ, ຫຼືພິຈາລະນາຈຸດຂໍ້ມູນບາງຢ່າງຫຼາຍກວ່າອັນອື່ນ, ເຊິ່ງສາມາດນຳໄປສູ່ຜົນໄດ້ຮັບທີ່ບໍ່ລຳອຽງ.
- ຜູ້ໃຊ້ກັບຂໍ້ມູນ: ກ່ຽວຂ້ອງກັບຄວາມລໍາອຽງທີ່ເກີດຂື້ນຈາກການໂຕ້ຕອບຂອງຜູ້ໃຊ້ກັບລະບົບ. ລັກສະນະທີ່ຜູ້ໃຊ້ປ້ອນຂໍ້ມູນ, ຄວາມລໍາອຽງທີ່ເກີດມາຂອງເຂົາເຈົ້າ, ຫຼືແມ້ກະທັ້ງຄວາມໄວ້ວາງໃຈຂອງເຂົາເຈົ້າໃນຜົນໄດ້ຮັບຂອງລະບົບສາມາດມີອິດທິພົນຕໍ່ຜົນໄດ້ຮັບ.
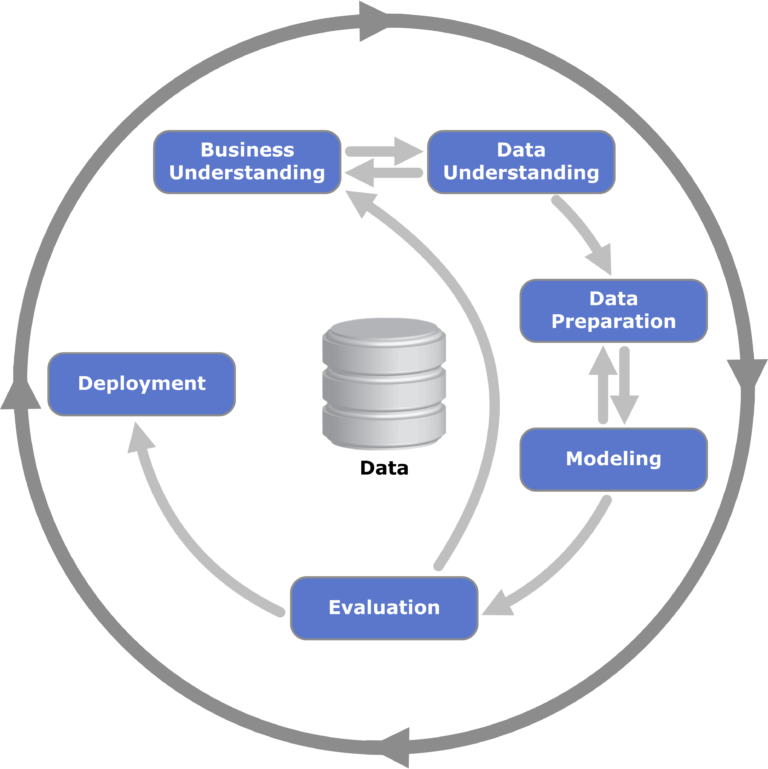
ຮູບທີ 1: ການສະແດງພາບຂອງກອບ CRISP-DM ສຳລັບການຂຸດຄົ້ນຂໍ້ມູນ; ຖືກນໍາໃຊ້ທົ່ວໄປໃນການຂຸດຄົ້ນຂໍ້ມູນແລະກ່ຽວຂ້ອງກັບຂະບວນການກໍານົດຂັ້ນຕອນທີ່ຄວາມລໍາອຽງສາມາດເກີດຂື້ນໄດ້.
ໃນຂະນະທີ່ຊື່ແມ່ນຊີ້ໃຫ້ເຫັນເຖິງຮູບແບບຂອງຄວາມລໍາອຽງ, ຄົນເຮົາອາດຍັງມີຄໍາຖາມກ່ຽວກັບປະເພດຂອງຄວາມລໍາອຽງທີ່ຫນຶ່ງອາດຈະຈັດປະເພດພາຍໃຕ້ຂໍ້ກໍານົດເຫຼົ່ານີ້. ສໍາລັບຜູ້ທີ່ກະຕືລືລົ້ນໃນບັນດາຜູ້ອ່ານຂອງພວກເຮົາ, ພວກເຮົາໄດ້ໃຫ້ການເຊື່ອມຕໍ່ກັບວັນນະຄະດີບາງຢ່າງທີ່ກ່ຽວຂ້ອງກັບຄໍາສັບແລະການຈັດປະເພດນີ້. ເພື່ອປະໂຫຍດຂອງຄວາມງ່າຍດາຍໃນການຕອບ blog ນີ້, ພວກເຮົາຈະກວມເອົາຄວາມລໍາອຽງທີ່ເລືອກຈໍານວນຫນ້ອຍທີ່ກ່ຽວຂ້ອງກັບສະຖານະການ (ເກືອບທັງຫມົດແມ່ນຂໍ້ມູນປະເພດກັບ algorithm). ປະເພດຂອງອະຄະຕິສະເພາະມີດັ່ງນີ້:
- ອະຄະຕິທາງປະຫວັດສາດ: ປະເພດຂອງຄວາມລໍາອຽງທີ່ເກີດຂື້ນກັບຂໍ້ມູນທີ່ເກີດຈາກຄວາມລໍາອຽງທໍາມະຊາດທີ່ມີຢູ່ໃນໂລກໃນກຸ່ມສັງຄົມທີ່ແຕກຕ່າງກັນແລະສັງຄົມໂດຍທົ່ວໄປ. ມັນແມ່ນຍ້ອນການປະກົດຕົວຂອງຂໍ້ມູນນີ້ໃນໂລກທີ່ມັນບໍ່ສາມາດຖືກຫຼຸດຜ່ອນໂດຍຜ່ານວິທີການຕ່າງໆຂອງການເກັບຕົວຢ່າງແລະການຄັດເລືອກຄຸນສົມບັດ.
- ການວັດແທກຄວາມລຳອຽງ & ຄວາມລຳອຽງທີ່ເປັນຕົວແທນ: ສອງຄວາມລຳອຽງທີ່ກ່ຽວພັນກັນຢ່າງໃກ້ຊິດເກີດຂຶ້ນເມື່ອກຸ່ມຍ່ອຍທີ່ແຕກຕ່າງກັນຂອງຊຸດຂໍ້ມູນມີຈຳນວນບໍ່ເທົ່າກັນຂອງຜົນໄດ້ຮັບ "ທີ່ເອື້ອອໍານວຍ". ປະເພດຂອງຄວາມລໍາອຽງນີ້ສາມາດ skew ຜົນໄດ້ຮັບຂອງຕົວແບບຄາດຄະເນ
- ຄວາມລຳອຽງຂອງ Algorithmic: Bias ກ່ຽວຂ້ອງກັບສູດການຄິດໄລ່ທີ່ນຳໃຊ້. ດັ່ງທີ່ສັງເກດເຫັນໃນການທົດສອບ (ລາຍລະອຽດເພີ່ມເຕີມໃນບົດຄວາມ), ປະເພດຂອງຄວາມລໍາອຽງນີ້ສາມາດມີຜົນກະທົບຢ່າງຫຼວງຫຼາຍຕໍ່ຄວາມຍຸດຕິທໍາຂອງສູດການຄິດໄລ່.
ຄວາມເຂົ້າໃຈພື້ນຖານເຫຼົ່ານີ້ກ່ຽວກັບຄວາມລໍາອຽງໃນການຮຽນຮູ້ເຄື່ອງຈັກຈະຖືກນໍາໄປໃຊ້ເພື່ອແກ້ໄຂບັນຫາຢ່າງມີປະສິດທິພາບຫຼາຍຂຶ້ນໃນຫົວຂໍ້ຕໍ່ມາ.
ຄວາມຄິດສຸດທ້າຍ
ໃນການສຳຫຼວດຄວາມລຳອຽງພາຍໃນປັນຍາປະດິດນີ້, ພວກເຮົາໄດ້ສ່ອງແສງເຖິງຜົນສະທ້ອນອັນເລິກຊຶ້ງທີ່ມັນຢູ່ໃນໂລກທີ່ຂັບເຄື່ອນດ້ວຍ AI ຂອງພວກເຮົາເພີ່ມຂຶ້ນ. ຈາກຕົວຢ່າງໃນໂລກຕົວຈິງເຊັ່ນເລື່ອງອື້ສາວດ້ານສະຫວັດດີການເດັກຂອງຊາວໂຮນລັງເຖິງຄວາມເຄັ່ງຄັດຂອງປະເພດອະຄະຕິ ແລະປະເພດ, ມັນເຫັນໄດ້ຊັດເຈນວ່າການຮັບຮູ້ ແລະເຂົ້າໃຈຄວາມລໍາອຽງແມ່ນສໍາຄັນທີ່ສຸດ.
ໃນຂະນະທີ່ສິ່ງທ້າທາຍທີ່ເກີດຈາກຄວາມລໍາອຽງ - ບໍ່ວ່າຈະເປັນປະຫວັດສາດ, ສູດການຄິດໄລ່, ຫຼືການກະຕຸ້ນຂອງຜູ້ໃຊ້ - ມີຄວາມສໍາຄັນ, ພວກມັນບໍ່ສາມາດເອົາຊະນະໄດ້. ດ້ວຍຄວາມເຂົ້າໃຈຢ່າງແໜ້ນແຟ້ນກ່ຽວກັບຕົ້ນກຳເນີດ ແລະ ການສະແດງອອກຂອງຄວາມລຳອຽງ, ພວກເຮົາພ້ອມທີ່ຈະແກ້ໄຂມັນໄດ້ດີກວ່າ. ຢ່າງໃດກໍຕາມ, ການຮັບຮູ້ແລະຄວາມເຂົ້າໃຈແມ່ນພຽງແຕ່ຈຸດເລີ່ມຕົ້ນ.
ໃນຂະນະທີ່ພວກເຮົາກ້າວໄປຂ້າງຫນ້າໃນຊຸດນີ້, ຈຸດສຸມຕໍ່ໄປຂອງພວກເຮົາຈະຢູ່ໃນເຄື່ອງມືທີ່ເຫັນໄດ້ຊັດເຈນແລະກອບການກໍາຈັດຂອງພວກເຮົາ. ພວກເຮົາຈະວັດແທກຂອບເຂດຄວາມລໍາອຽງໃນແບບຈໍາລອງ AI ແນວໃດ? ແລະສໍາຄັນກວ່ານັ້ນ, ພວກເຮົາຈະຫຼຸດຜ່ອນຜົນກະທົບຂອງມັນແນວໃດ? ນີ້ແມ່ນ ຄຳ ຖາມທີ່ຮີບດ່ວນທີ່ພວກເຮົາຈະພິຈາລະນາຕໍ່ໄປ, ຮັບປະກັນວ່າ AI ສືບຕໍ່ພັດທະນາ, ມັນເຮັດໄດ້ໃນທິດທາງທີ່ທັງຍຸດຕິ ທຳ ແລະການປະຕິບັດ.

ຂໍ້ມູນແມ່ນສັງເຄາະ, ແຕ່ທີມງານຂອງພວກເຮົາແມ່ນຈິງ!
ຕິດຕໍ່ Syntho ແລະຫນຶ່ງໃນຜູ້ຊ່ຽວຊານຂອງພວກເຮົາຈະຕິດຕໍ່ກັບທ່ານດ້ວຍຄວາມໄວຂອງແສງເພື່ອຄົ້ນຫາມູນຄ່າຂອງຂໍ້ມູນສັງເຄາະ!