ຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI, ການເຂົ້າເຖິງງ່າຍແລະໄວເພື່ອຂໍ້ມູນຄຸນນະພາບສູງ?
AI ສ້າງຂໍ້ມູນສັງເຄາະໃນການປະຕິບັດ
Syntho, ຜູ້ຊ່ຽວຊານດ້ານຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI, ມີຈຸດປະສົງເພື່ອຫັນ privacy by design ໄປສູ່ຄວາມໄດ້ປຽບໃນການແຂ່ງຂັນກັບຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI. ພວກເຂົາຊ່ວຍອົງການຈັດຕັ້ງໃນການສ້າງພື້ນຖານຂໍ້ມູນທີ່ເຂັ້ມແຂງດ້ວຍການເຂົ້າເຖິງຂໍ້ມູນທີ່ມີຄຸນນະພາບສູງແລະງ່າຍດາຍແລະບໍ່ດົນມານີ້ໄດ້ຮັບລາງວັນ Philips Innovation Award.
ຢ່າງໃດກໍຕາມ, ການຜະລິດຂໍ້ມູນສັງເຄາະດ້ວຍ AI ແມ່ນການແກ້ໄຂໃຫມ່ທີ່ຂ້ອນຂ້າງແນະນໍາຄໍາຖາມທີ່ຖືກຖາມເລື້ອຍໆ. ເພື່ອຕອບຄໍາຖາມເຫຼົ່ານີ້, Syntho ໄດ້ເລີ່ມຕົ້ນການສຶກສາກໍລະນີຮ່ວມກັນກັບ SAS, ຜູ້ນໍາຕະຫຼາດໃນ Advanced Analytics ແລະຊອບແວ AI.
ໃນການຮ່ວມມືກັບ Dutch AI Coalition (NL AIC), ພວກເຂົາເຈົ້າໄດ້ສືບສວນມູນຄ່າຂອງຂໍ້ມູນສັງເຄາະໂດຍການປຽບທຽບຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI ທີ່ຜະລິດໂດຍ Syntho Engine ກັບຂໍ້ມູນຕົ້ນສະບັບຜ່ານການປະເມີນຕ່າງໆກ່ຽວກັບຄຸນນະພາບຂໍ້ມູນ, ຄວາມຖືກຕ້ອງທາງດ້ານກົດຫມາຍແລະການນໍາໃຊ້.
ການປິດບັງຂໍ້ມູນບໍ່ແມ່ນການແກ້ໄຂບໍ?
ເຕັກນິກການປິດບັງຊື່ແບບຄລາສສິກມີຢູ່ທົ່ວໄປວ່າພວກເຂົາຈັດການຂໍ້ມູນຕົ້ນສະບັບເພື່ອຂັດຂວາງການຕິດຕາມບຸກຄົນ. ຕົວຢ່າງແມ່ນການເຮັດໃຫ້ທົ່ວໄປ, ການສະກັດກັ້ນ, ການເຊັດ, ການໃສ່ນາມສະກຸນ, ການປິດບັງຂໍ້ມູນ, ແລະການສະຫຼັບແຖວ ແລະຖັນ. ທ່ານສາມາດຊອກຫາຕົວຢ່າງໃນຕາຕະລາງຂ້າງລຸ່ມນີ້.
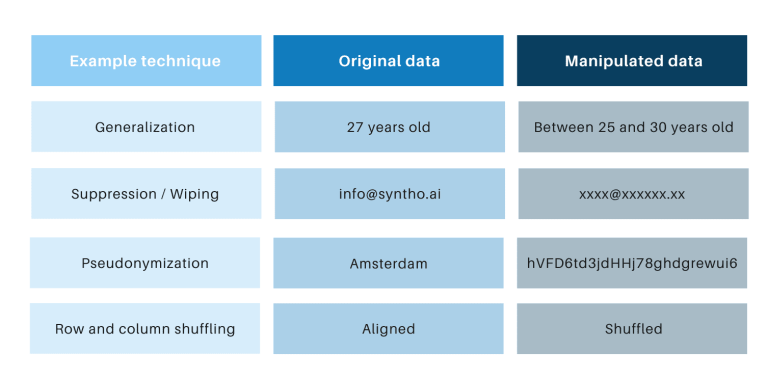
ເຕັກນິກເຫຼົ່ານັ້ນນໍາສະເຫນີ 3 ສິ່ງທ້າທາຍທີ່ສໍາຄັນ:
- ພວກເຂົາເຮັດວຽກແຕກຕ່າງກັນຕໍ່ປະເພດຂໍ້ມູນແລະຕໍ່ຊຸດຂໍ້ມູນ, ເຮັດໃຫ້ມັນຍາກທີ່ຈະປັບຂະຫນາດ. ນອກຈາກນັ້ນ, ຍ້ອນວ່າພວກເຂົາເຮັດວຽກແຕກຕ່າງກັນ, ສະເຫມີຈະມີການໂຕ້ວາທີກ່ຽວກັບວິທີທີ່ຈະນໍາໃຊ້ແລະເຕັກນິກການລວມກັນທີ່ຈໍາເປັນ.
- ມີການພົວພັນຫນຶ່ງຕໍ່ຫນຶ່ງສະເຫມີກັບຂໍ້ມູນຕົ້ນສະບັບ. ນີ້ຫມາຍຄວາມວ່າຈະມີຄວາມສ່ຽງດ້ານຄວາມເປັນສ່ວນຕົວສະເຫມີ, ໂດຍສະເພາະເນື່ອງຈາກຊຸດຂໍ້ມູນເປີດທັງຫມົດແລະເຕັກນິກທີ່ມີຢູ່ເພື່ອເຊື່ອມຕໍ່ຊຸດຂໍ້ມູນເຫຼົ່ານັ້ນ.
- ພວກເຂົາເຈົ້າ manipulate ຂໍ້ມູນແລະເຮັດໃຫ້ການທໍາລາຍຂໍ້ມູນໃນຂະບວນການ. ນີ້ແມ່ນຄວາມເສຍຫາຍໂດຍສະເພາະສໍາລັບວຽກງານ AI ທີ່ "ພະລັງງານການຄາດເດົາ" ເປັນສິ່ງຈໍາເປັນ, ເພາະວ່າຂໍ້ມູນທີ່ມີຄຸນນະພາບທີ່ບໍ່ດີຈະເຮັດໃຫ້ເກີດຄວາມເຂົ້າໃຈທີ່ບໍ່ດີຈາກຕົວແບບ AI (ການຂີ້ເຫຍື້ອຈະສົ່ງຜົນໃຫ້ຂີ້ເຫຍື້ອ).
ຈຸດເຫຼົ່ານີ້ຍັງຖືກປະເມີນຜ່ານກໍລະນີສຶກສານີ້.
ບົດແນະນໍາກ່ຽວກັບກໍລະນີສຶກສາ
ສໍາລັບກໍລະນີສຶກສາ, ຊຸດຂໍ້ມູນເປົ້າໝາຍແມ່ນຊຸດຂໍ້ມູນໂທລະຄົມທີ່ສະໜອງໃຫ້ໂດຍ SAS ທີ່ມີຂໍ້ມູນຂອງລູກຄ້າ 56.600 ຄົນ. ຊຸດຂໍ້ມູນປະກອບມີ 128 ຖັນ, ລວມທັງຖັນໜຶ່ງທີ່ຊີ້ບອກວ່າລູກຄ້າໄດ້ອອກຈາກບໍລິສັດແລ້ວ (ເຊັ່ນ: 'ປັ່ນປ່ວນ') ຫຼືບໍ່. ເປົ້າຫມາຍຂອງກໍລະນີສຶກສາແມ່ນການນໍາໃຊ້ຂໍ້ມູນສັງເຄາະເພື່ອຝຶກອົບຮົມບາງຕົວແບບເພື່ອຄາດຄະເນການປັ່ນປ່ວນຂອງລູກຄ້າແລະການປະເມີນການປະຕິບັດຂອງຕົວແບບທີ່ໄດ້ຮັບການຝຶກອົບຮົມເຫຼົ່ານັ້ນ. ເນື່ອງຈາກການຄາດຄະເນການປັ່ນປ່ວນແມ່ນວຽກງານການຈັດປະເພດ, SAS ໄດ້ເລືອກຮູບແບບການຈັດປະເພດທີ່ນິຍົມ XNUMX ແບບເພື່ອເຮັດໃຫ້ການຄາດຄະເນ, ລວມທັງ:
- ປ່າສຸ່ມ
- ການເພີ່ມລະດັບສີ
- ການຖົດຖອຍ logistic
- Neural network
ກ່ອນທີ່ຈະສ້າງຂໍ້ມູນສັງເຄາະ, SAS ແບ່ງຊຸດຂໍ້ມູນໂທລະຄົມແບບສຸ່ມອອກເປັນຊຸດລົດໄຟ (ສໍາລັບການຝຶກອົບຮົມແບບຈໍາລອງ) ແລະຊຸດຄ້າງ (ສໍາລັບການໃຫ້ຄະແນນແບບຈໍາລອງ). ການມີຊຸດຄ້າງໄວ້ແຍກຕ່າງຫາກສໍາລັບການໃຫ້ຄະແນນຊ່ວຍໃຫ້ມີການປະເມີນທີ່ບໍ່ເປັນກາງວ່າຮູບແບບການຈັດປະເພດອາດຈະປະຕິບັດໄດ້ດີປານໃດເມື່ອນໍາໃຊ້ກັບຂໍ້ມູນໃຫມ່.
ໂດຍໃຊ້ຊຸດລົດໄຟເປັນວັດສະດຸປ້ອນ, Syntho ໄດ້ໃຊ້ເຄື່ອງຈັກ Syntho ເພື່ອສ້າງຊຸດຂໍ້ມູນສັງເຄາະ. ສໍາລັບ benchmarking, SAS ຍັງໄດ້ສ້າງສະບັບ manipulated ຂອງຊຸດລົດໄຟຫຼັງຈາກການນໍາໃຊ້ເຕັກນິກການປິດບັງຊື່ຕ່າງໆເພື່ອບັນລຸເປົ້າຫມາຍສະເພາະໃດຫນຶ່ງ (ຂອງ k-anonimity). ຂັ້ນຕອນທີ່ຜ່ານມາໄດ້ເຮັດໃຫ້ມີສີ່ຊຸດຂໍ້ມູນ:
- ຊຸດຂໍ້ມູນລົດໄຟ (ເຊັ່ນຊຸດຂໍ້ມູນຕົ້ນສະບັບລົບຊຸດຂໍ້ມູນການຖືເອົາ)
- ຊຸດຂໍ້ມູນທີ່ຄ້າງໄວ້ (ເຊັ່ນຊຸດຍ່ອຍຂອງຊຸດຂໍ້ມູນຕົ້ນສະບັບ)
- ຊຸດຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ (ອີງຕາມຊຸດຂໍ້ມູນລົດໄຟ)
- ຊຸດຂໍ້ມູນສັງເຄາະ (ອີງຕາມຊຸດຂໍ້ມູນລົດໄຟ)
ຊຸດຂໍ້ມູນ 1, 3 ແລະ 4 ໄດ້ຖືກນໍາໃຊ້ເພື່ອຝຶກອົບຮົມແຕ່ລະແບບຈໍາແນກ, ຜົນໄດ້ຮັບ 12 (3 x 4) ແບບຝຶກອົບຮົມ. ຕໍ່ມາ SAS ໄດ້ໃຊ້ຊຸດຂໍ້ມູນການຍຶດຖືເພື່ອວັດແທກຄວາມຖືກຕ້ອງຂອງແຕ່ລະແບບທີ່ຄາດຄະເນການປັ່ນປ່ວນຂອງລູກຄ້າ. ຜົນໄດ້ຮັບໄດ້ຖືກນໍາສະເຫນີຂ້າງລຸ່ມນີ້, ເລີ່ມຕົ້ນດ້ວຍສະຖິຕິພື້ນຖານບາງຢ່າງ.
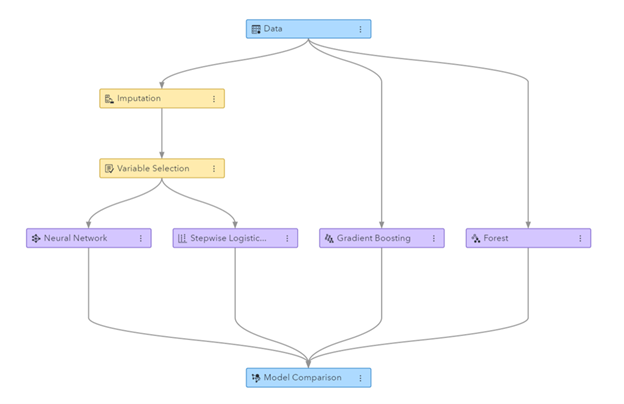
ຮູບ: ທໍ່ການຮຽນຮູ້ເຄື່ອງຈັກທີ່ສ້າງຂຶ້ນໃນ SAS Visual Data Mining ແລະ Machine Learning
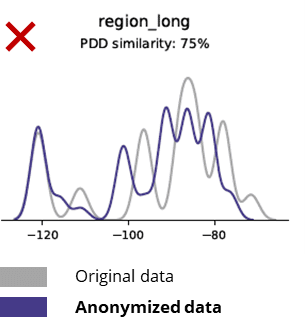
ສະຖິຕິພື້ນຖານເມື່ອປຽບທຽບຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ກັບຂໍ້ມູນຕົ້ນສະບັບ
ເຕັກນິກການປິດບັງຊື່ທໍາລາຍເຖິງແມ່ນຮູບແບບພື້ນຖານ, ເຫດຜົນທາງທຸລະກິດ, ຄວາມສໍາພັນແລະສະຖິຕິ (ໃນຕົວຢ່າງຂ້າງລຸ່ມນີ້). ການນໍາໃຊ້ຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ສໍາລັບການວິເຄາະພື້ນຖານດັ່ງນັ້ນຈຶ່ງເຮັດໃຫ້ຜົນໄດ້ຮັບທີ່ບໍ່ຫນ້າເຊື່ອຖື. ໃນຄວາມເປັນຈິງ, ຄຸນນະພາບທີ່ບໍ່ດີຂອງຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ເຮັດໃຫ້ມັນເກືອບເປັນໄປບໍ່ໄດ້ທີ່ຈະໃຊ້ມັນສໍາລັບວຽກງານການວິເຄາະຂັ້ນສູງ (ເຊັ່ນ: ການສ້າງແບບຈໍາລອງ AI / ML ແລະ dashboarding).
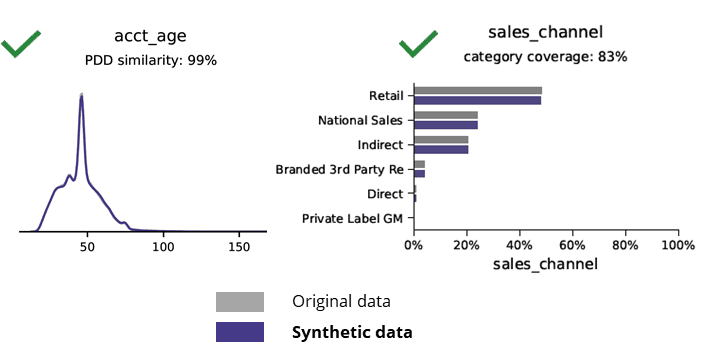
ສະຖິຕິພື້ນຖານເມື່ອປຽບທຽບຂໍ້ມູນສັງເຄາະກັບຂໍ້ມູນຕົ້ນສະບັບ
ການຜະລິດຂໍ້ມູນສັງເຄາະດ້ວຍ AI ຮັກສາຮູບແບບພື້ນຖານ, ເຫດຜົນທາງທຸລະກິດ, ຄວາມສໍາພັນແລະສະຖິຕິ (ເຊັ່ນໃນຕົວຢ່າງຂ້າງລຸ່ມນີ້). ການນໍາໃຊ້ຂໍ້ມູນສັງເຄາະສໍາລັບການວິເຄາະພື້ນຖານດັ່ງນັ້ນຈຶ່ງເຮັດໃຫ້ຜົນໄດ້ຮັບທີ່ຫນ້າເຊື່ອຖື. ຄໍາຖາມທີ່ສໍາຄັນ, ຂໍ້ມູນສັງເຄາະມີສໍາລັບວຽກງານການວິເຄາະຂັ້ນສູງ (ເຊັ່ນ: ການສ້າງແບບຈໍາລອງ AI / ML ແລະ dashboarding) ບໍ?
ຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI ແລະການວິເຄາະຂັ້ນສູງ
ຂໍ້ມູນສັງເຄາະຖືບໍ່ພຽງແຕ່ສໍາລັບຮູບແບບພື້ນຖານ (ດັ່ງທີ່ສະແດງຢູ່ໃນແຜນທີ່ໃນອະດີດ), ມັນຍັງເກັບກໍາຮູບແບບສະຖິຕິທີ່ເລິກເຊິ່ງ 'ເຊື່ອງໄວ້' ທີ່ຈໍາເປັນສໍາລັບວຽກງານການວິເຄາະຂັ້ນສູງ. ອັນສຸດທ້າຍແມ່ນສະແດງໃຫ້ເຫັນຢູ່ໃນຕາຕະລາງແຖບຂ້າງລຸ່ມນີ້, ສະແດງໃຫ້ເຫັນວ່າຄວາມຖືກຕ້ອງຂອງຕົວແບບທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນສັງເຄາະທຽບກັບແບບຈໍາລອງທີ່ໄດ້ຮັບການຝຶກອົບຮົມຈາກຂໍ້ມູນຕົ້ນສະບັບແມ່ນຄ້າຍຄືກັນ. ຍິ່ງໄປກວ່ານັ້ນ, ດ້ວຍພື້ນທີ່ພາຍໃຕ້ເສັ້ນໂຄ້ງ (AUC*) ໃກ້ກັບ 0.5, ແບບຈໍາລອງທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ປະຕິບັດໄດ້ຮ້າຍແຮງທີ່ສຸດ. ບົດລາຍງານສະບັບເຕັມທີ່ມີການປະເມີນການວິເຄາະຂັ້ນສູງທັງຫມົດກ່ຽວກັບຂໍ້ມູນສັງເຄາະໃນການປຽບທຽບກັບຂໍ້ມູນຕົ້ນສະບັບແມ່ນມີຢູ່ໃນຄໍາຮ້ອງຂໍ.
* AUC: ພື້ນທີ່ພາຍໃຕ້ເສັ້ນໂຄ້ງແມ່ນມາດຕະການສໍາລັບຄວາມຖືກຕ້ອງຂອງແບບຈໍາລອງການວິເຄາະແບບພິເສດ, ໂດຍຄໍານຶງເຖິງຈຸດບວກທີ່ແທ້ຈິງ, ບວກທີ່ບໍ່ຖືກຕ້ອງ, ລົບທີ່ບໍ່ຖືກຕ້ອງແລະທາງລົບທີ່ແທ້ຈິງ. 0,5 ຫມາຍຄວາມວ່າຕົວແບບຄາດຄະເນແບບສຸ່ມແລະບໍ່ມີອໍານາດຄາດຄະເນແລະ 1 ຫມາຍຄວາມວ່າຕົວແບບທີ່ຖືກຕ້ອງສະເຫມີແລະມີອໍານາດການຄາດເດົາຢ່າງເຕັມທີ່.
ນອກຈາກນັ້ນ, ຂໍ້ມູນສັງເຄາະນີ້ສາມາດຖືກນໍາໃຊ້ເພື່ອເຂົ້າໃຈລັກສະນະຂໍ້ມູນແລະຕົວແປຕົ້ນຕໍທີ່ຈໍາເປັນສໍາລັບການຝຶກອົບຮົມຕົວຈິງຂອງຕົວແບບ. ວັດສະດຸປ້ອນທີ່ເລືອກໂດຍ algorithms ກ່ຽວກັບຂໍ້ມູນສັງເຄາະທຽບກັບຂໍ້ມູນຕົ້ນສະບັບແມ່ນຄ້າຍຄືກັນຫຼາຍ. ດັ່ງນັ້ນ, ຂະບວນການສ້າງແບບຈໍາລອງສາມາດເຮັດໄດ້ໃນສະບັບສັງເຄາະນີ້, ເຊິ່ງຫຼຸດຜ່ອນຄວາມສ່ຽງຕໍ່ການລະເມີດຂໍ້ມູນ. ຢ່າງໃດກໍຕາມ, ໃນເວລາທີ່ inferencing ບັນທຶກສ່ວນບຸກຄົນ (ເຊັ່ນ: ລູກຄ້າ telco) retraining ກ່ຽວກັບຂໍ້ມູນຕົ້ນສະບັບແມ່ນແນະນໍາໃຫ້ອະທິບາຍ, ເພີ່ມຂຶ້ນການຍອມຮັບຫຼືພຽງແຕ່ເນື່ອງຈາກວ່າລະບຽບການ.
AUC ໂດຍ Algorithm ຈັດກຸ່ມໂດຍວິທີການ
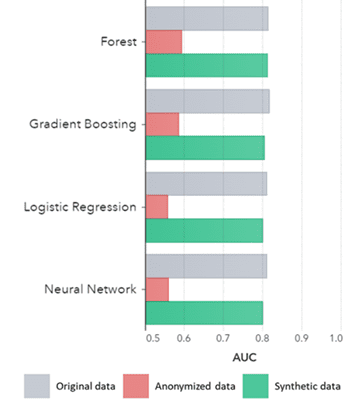
ຂໍ້ສະຫຼຸບ:
- ແບບຈໍາລອງທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນສັງເຄາະທຽບກັບຕົວແບບທີ່ໄດ້ຮັບການຝຶກອົບຮົມຈາກຂໍ້ມູນຕົ້ນສະບັບສະແດງໃຫ້ເຫັນປະສິດທິພາບທີ່ຄ້າຍຄືກັນສູງ
- ແບບຈໍາລອງທີ່ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ທີ່ມີ 'ເຕັກນິກການປິດບັງຊື່ແບບຄລາສສິກ' ສະແດງໃຫ້ເຫັນປະສິດທິພາບທີ່ຕໍ່າກວ່າເມື່ອປຽບທຽບກັບຕົວແບບທີ່ໄດ້ຮັບການຝຶກອົບຮົມຈາກຂໍ້ມູນຕົ້ນສະບັບ ຫຼືຂໍ້ມູນສັງເຄາະ
- ການຜະລິດຂໍ້ມູນສັງເຄາະແມ່ນງ່າຍແລະໄວເນື່ອງຈາກວ່າເຕັກນິກການເຮັດວຽກແທ້ດຽວກັນຕໍ່ຊຸດຂໍ້ມູນແລະຕໍ່ປະເພດຂໍ້ມູນ.
ກໍລະນີການນໍາໃຊ້ຂໍ້ມູນສັງເຄາະເພີ່ມມູນຄ່າ
ການນໍາໃຊ້ກໍລະນີ 1: ຂໍ້ມູນສັງເຄາະສໍາລັບການພັດທະນາຕົວແບບແລະການວິເຄາະຂັ້ນສູງ
ມີພື້ນຖານຂໍ້ມູນທີ່ເຂັ້ມແຂງທີ່ມີການເຂົ້າເຖິງງ່າຍແລະໄວເພື່ອໃຊ້ໄດ້, ຂໍ້ມູນທີ່ມີຄຸນນະພາບສູງແມ່ນມີຄວາມຈໍາເປັນໃນການພັດທະນາຕົວແບບ (ເຊັ່ນ: dashboards [BI] ແລະການວິເຄາະຂັ້ນສູງ [AI & ML]). ຢ່າງໃດກໍຕາມ, ອົງການຈັດຕັ້ງຈໍານວນຫຼາຍປະສົບກັບພື້ນຖານຂໍ້ມູນທີ່ດີທີ່ສຸດທີ່ເຮັດໃຫ້ເກີດ 3 ສິ່ງທ້າທາຍທີ່ສໍາຄັນ:
- ການເຂົ້າເຖິງຂໍ້ມູນຕ້ອງໃຊ້ເວລາຫຼາຍອາຍຸເນື່ອງຈາກກົດລະບຽບ (ຄວາມເປັນສ່ວນຕົວ), ຂະບວນການພາຍໃນຫຼື silo ຂໍ້ມູນ
- ເຕັກນິກການເປີດເຜີຍຊື່ແບບຄລາສສິກທໍາລາຍຂໍ້ມູນ, ເຮັດໃຫ້ຂໍ້ມູນບໍ່ເຫມາະສົມສໍາລັບການວິເຄາະແລະການວິເຄາະຂັ້ນສູງ (ຂີ້ເຫຍື້ອໃນ = ຂີ້ເຫຍື້ອອອກ)
- ການແກ້ໄຂທີ່ມີຢູ່ແມ່ນບໍ່ສາມາດຂະຫຍາຍໄດ້ເພາະວ່າພວກມັນເຮັດວຽກແຕກຕ່າງກັນຕໍ່ຊຸດຂໍ້ມູນແລະຕໍ່ປະເພດຂໍ້ມູນແລະບໍ່ສາມາດຈັດການກັບຖານຂໍ້ມູນຫຼາຍຕາຕະລາງຂະຫນາດໃຫຍ່.
ວິທີການຂໍ້ມູນສັງເຄາະ: ການພັດທະນາຕົວແບບທີ່ມີຂໍ້ມູນສັງເຄາະທີ່ດີທີ່ເປັນຈິງເພື່ອ:
- ຫຼຸດການໃຊ້ຂໍ້ມູນຕົ້ນສະບັບລົງ, ໂດຍບໍ່ຂັດຂວາງຜູ້ພັດທະນາຂອງເຈົ້າ
- ປົດລັອກຂໍ້ມູນສ່ວນຕົວແລະມີການເຂົ້າເຖິງຂໍ້ມູນເພີ່ມເຕີມທີ່ຖືກຈໍາກັດໄວ້ກ່ອນ ໜ້າ ນີ້ (ຕົວຢ່າງເນື່ອງຈາກຄວາມເປັນສ່ວນຕົວ)
- ເຂົ້າເຖິງຂໍ້ມູນໄດ້ງ່າຍແລະໄວເພື່ອເຂົ້າເຖິງຂໍ້ມູນທີ່ກ່ຽວຂ້ອງ
- ການແກ້ໄຂທີ່ຂະຫຍາຍໄດ້ທີ່ເຮັດວຽກອັນດຽວກັນສໍາລັບແຕ່ລະຊຸດຂໍ້ມູນ, ປະເພດປະເພດແລະສໍາລັບຖານຂໍ້ມູນໃຫຍ່
ນີ້ອະນຸຍາດໃຫ້ອົງການຈັດຕັ້ງສ້າງພື້ນຖານຂໍ້ມູນທີ່ເຂັ້ມແຂງທີ່ມີການເຂົ້າເຖິງງ່າຍແລະໄວໃນການນໍາໃຊ້, ຂໍ້ມູນທີ່ມີຄຸນນະພາບສູງເພື່ອປົດລັອກຂໍ້ມູນແລະໂອກາດຂໍ້ມູນ.
ການນໍາໃຊ້ກໍລະນີ 2: ຂໍ້ມູນການທົດສອບສັງເຄາະອັດສະລິຍະສໍາລັບການທົດສອບຊອບແວ, ການພັດທະນາແລະການຈັດສົ່ງ
ການທົດສອບແລະການພັດທະນາດ້ວຍຂໍ້ມູນການທົດສອບທີ່ມີຄຸນນະພາບສູງເປັນສິ່ງຈໍາເປັນເພື່ອສະຫນອງການແກ້ໄຂຊອບແວທີ່ທັນສະໄຫມ. ການນໍາໃຊ້ຂໍ້ມູນການຜະລິດຕົ້ນສະບັບເບິ່ງຄືວ່າຈະແຈ້ງ, ແຕ່ບໍ່ໄດ້ຮັບອະນຸຍາດເນື່ອງຈາກ (ຄວາມເປັນສ່ວນຕົວ) ກົດລະບຽບ. ທາງເລືອກ Test Data Management (TDM) ເຄື່ອງມືແນະນໍາ "legacy-by-design” ໃນການໄດ້ຮັບຂໍ້ມູນການທົດສອບທີ່ຖືກຕ້ອງ:
- ບໍ່ສະທ້ອນຂໍ້ມູນການຜະລິດແລະເຫດຜົນທາງທຸລະກິດແລະຄວາມຊື່ສັດຂອງການອ້າງອິງບໍ່ໄດ້ຖືກຮັກສາໄວ້
- ເຮັດວຽກຊ້າ ແລະໃຊ້ເວລາຫຼາຍ
- ການເຮັດວຽກຄູ່ມືແມ່ນຕ້ອງການ
ວິທີການຂໍ້ມູນສັງເຄາະ: ການທົດສອບແລະການພັດທະນາກັບຂໍ້ມູນການທົດສອບສັງເຄາະທີ່ສ້າງໂດຍ AI ເພື່ອໃຫ້ການແກ້ໄຂຊອບແວທີ່ທັນສະໄຫມທີ່ສະຫລາດກັບ:
- ຂໍ້ມູນຄ້າຍຄືການຜະລິດທີ່ມີເຫດຜົນທາງທຸລະກິດທີ່ຮັກສາໄວ້ ແລະຄວາມຊື່ສັດຂອງການອ້າງອີງ
- ສ້າງຂໍ້ມູນໄດ້ງ່າຍແລະໄວດ້ວຍ AI ທີ່ທັນສະໄ
- ຄວາມເປັນສ່ວນຕົວໂດຍການອອກແບບ
- ງ່າຍ, ໄວແລະ agile
ນີ້ອະນຸຍາດໃຫ້ອົງການຈັດຕັ້ງສາມາດທົດສອບແລະພັດທະນາກັບຂໍ້ມູນການທົດສອບລະດັບຕໍ່ໄປເພື່ອສະຫນອງການແກ້ໄຂຊອບແວທີ່ທັນສະໄຫມ!
ຂໍ້ມູນເພີ່ມເຕີມ
ສົນໃຈ? ສໍາລັບຂໍ້ມູນເພີ່ມເຕີມກ່ຽວກັບຂໍ້ມູນສັງເຄາະ, ໄປຢ້ຽມຢາມເວັບໄຊທ໌ Syntho ຫຼືຕິດຕໍ່ Wim Kees Janssen. ສໍາລັບຂໍ້ມູນເພີ່ມເຕີມກ່ຽວກັບ SAS, ໄປຢ້ຽມຢາມ www.sas.com ຫຼືຕິດຕໍ່ kees@syntho.ai.
ໃນກໍລະນີນີ້, Syntho, SAS ແລະ NL AIC ເຮັດວຽກຮ່ວມກັນເພື່ອບັນລຸຜົນໄດ້ຮັບທີ່ຕັ້ງໄວ້. Syntho ເປັນຜູ້ຊ່ຽວຊານໃນຂໍ້ມູນສັງເຄາະທີ່ສ້າງໂດຍ AI ແລະ SAS ເປັນຜູ້ນໍາຕະຫຼາດໃນການວິເຄາະແລະສະເຫນີຊອບແວສໍາລັບການສໍາຫຼວດ, ການວິເຄາະແລະການສະແດງຂໍ້ມູນ.
* ຄາດຄະເນປີ 2021 – ຂໍ້ມູນ ແລະຍຸດທະສາດການວິເຄາະເພື່ອຄຸ້ມຄອງ, ປັບຂະໜາດ ແລະຫັນປ່ຽນທຸລະກິດດິຈິຕອລ, Gartner, 2020.

ບັນທຶກຄູ່ມືຂໍ້ມູນສັງເຄາະຂອງເຈົ້າດຽວນີ້!
- ຂໍ້ມູນສັງເຄາະແມ່ນຫຍັງ?
- ເປັນຫຍັງອົງການຈັດຕັ້ງຈຶ່ງໃຊ້ມັນ?
- ການເພີ່ມມູນຄ່າກໍລະນີລູກຄ້າຂໍ້ມູນສັງເຄາະ
- ວິທີການເລີ່ມຕົ້ນ
