ຮີດໃຜ? 5 ຕົວຢ່າງວ່າເປັນຫຍັງການຖອນຊື່ບໍ່ແມ່ນທາງເລືອກ



ຮີດໃຜ? ເຖິງແມ່ນວ່າຂ້ອຍແນ່ໃຈວ່າພວກເຈົ້າເກືອບທັງknowົດຮູ້ຈັກເກມນີ້ຈາກສະໄກ່ອນ, ຢູ່ທີ່ນີ້ເປັນສະຫຼຸບໂດຍຫຍໍ້. ເປົ້າofາຍຂອງເກມ: ຄົ້ນພົບຊື່ຂອງຕົວລະຄອນກາຕູນທີ່ຄັດເລືອກໂດຍຄູ່ແຂ່ງຂອງເຈົ້າໂດຍການຖາມ ຄຳ ຖາມ 'ແມ່ນ' ແລະ 'ບໍ່', ຄືກັບວ່າ "ຄົນໃສ່hatວກບໍ?" ຫຼື 'ຄົນຜູ້ນັ້ນໃສ່ແວ່ນຕາ' ບໍ? ຜູ້ຫຼິ້ນ ກຳ ຈັດຜູ້ສະbasedັກໂດຍອີງໃສ່ການຕອບສະ ໜອງ ຂອງຄູ່ແຂ່ງແລະຮຽນຮູ້ຄຸນລັກສະນະທີ່ກ່ຽວຂ້ອງກັບລັກສະນະລຶກລັບຂອງຄູ່ແຂ່ງ. ຜູ້ຫຼິ້ນຄົນ ທຳ ອິດທີ່ຄິດໄລ່ລັກສະນະລຶກລັບຂອງຜູ້ຫຼິ້ນຄົນອື່ນຊະນະເກມ.
ເຈົ້າເຂົ້າໃຈແລ້ວ. ຄົນ ໜຶ່ງ ຕ້ອງລະບຸບຸກຄົນອອກຈາກຊຸດຂໍ້ມູນໂດຍການເຂົ້າເຖິງພຽງແຕ່ຄຸນລັກສະນະທີ່ສອດຄ້ອງກັນ. ໃນຄວາມເປັນຈິງ, ພວກເຮົາເຫັນແນວຄິດຂອງ Guess Who ປະຍຸກໃຊ້ເປັນປະຈໍາ, ແຕ່ຫຼັງຈາກນັ້ນໄດ້ນໍາໃຊ້ເຂົ້າໃນຊຸດຂໍ້ມູນທີ່ມີຮູບແບບເປັນແຖວແລະຖັນທີ່ມີຄຸນລັກສະນະຂອງຄົນແທ້. ຄວາມແຕກຕ່າງຕົ້ນຕໍໃນເວລາເຮັດວຽກກັບຂໍ້ມູນແມ່ນວ່າຜູ້ຄົນມີແນວໂນ້ມທີ່ຈະປະເມີນຄ່າຄວາມງ່າຍເຊິ່ງບຸກຄົນທີ່ແທ້ຈິງສາມາດເປີດເຜີຍໄດ້ໂດຍການເຂົ້າເຖິງພຽງແຕ່ສອງສາມຄຸນລັກສະນະເທົ່ານັ້ນ.
ດັ່ງທີ່ເກມ Guess Who ສະແດງໃຫ້ເຫັນ, ບາງຄົນສາມາດລະບຸບຸກຄົນໂດຍການເຂົ້າເຖິງພຽງແຕ່ຄຸນລັກສະນະສອງສາມຢ່າງ. ມັນໃຊ້ເປັນຕົວຢ່າງອັນງ່າຍ simple ວ່າເປັນຫຍັງການເອົາພຽງແຕ່ 'ຊື່' (ຫຼືຕົວລະບຸຕົວຕົນອື່ນ)) ອອກຈາກຊຸດຂໍ້ມູນຂອງເຈົ້າຈິ່ງບໍ່ສໍາເລັດເປັນເຕັກນິກການປິດບັງຊື່. ໃນ blog ນີ້, ພວກເຮົາໃຫ້ສີ່ກໍລະນີພາກປະຕິບັດເພື່ອແຈ້ງໃຫ້ເຈົ້າຮູ້ກ່ຽວກັບຄວາມສ່ຽງດ້ານຄວາມເປັນສ່ວນຕົວທີ່ກ່ຽວຂ້ອງກັບການກໍາຈັດຖັນທີ່ເປັນວິທີການປິດບັງຂໍ້ມູນ.
ຄວາມສ່ຽງຂອງການໂຈມຕີການເຊື່ອມໂຍງແມ່ນເຫດຜົນສໍາຄັນທີ່ສຸດວ່າເປັນຫຍັງການເອົາຊື່ແຕ່ພຽງຜູ້ດຽວອອກບໍ່ໄດ້ຜົນ (ອີກຕໍ່ໄປ) ເປັນວິທີການປິດບັງຊື່. ດ້ວຍການໂຈມຕີແບບເຊື່ອມໂຍງ, ຜູ້ໂຈມຕີໄດ້ລວມເອົາຂໍ້ມູນຕົ້ນສະບັບກັບແຫຼ່ງຂໍ້ມູນອື່ນທີ່ສາມາດເຂົ້າເຖິງໄດ້ເພື່ອລະບຸບຸກຄົນທີ່ບໍ່ຊໍ້າກັນແລະຮຽນຮູ້ຂໍ້ມູນ (ມັກຈະມີຄວາມອ່ອນໄຫວ) ກ່ຽວກັບບຸກຄົນນີ້.
ກຸນແຈຢູ່ທີ່ນີ້ແມ່ນການມີຊັບພະຍາກອນຂໍ້ມູນອື່ນທີ່ມີຢູ່ໃນປະຈຸບັນ, ຫຼືອາດຈະກາຍເປັນປະຈຸບັນໃນອະນາຄົດ. ຄິດກ່ຽວກັບຕົວທ່ານເອງ. ຂໍ້ມູນສ່ວນຕົວຂອງເຈົ້າເອງຫຼາຍປານໃດທີ່ສາມາດພົບໄດ້ຢູ່ໃນ Facebook, Instagram ຫຼື LinkedIn ທີ່ສາມາດຖືກທາລຸນເພື່ອໂຈມຕີການເຊື່ອມໂຍງ?
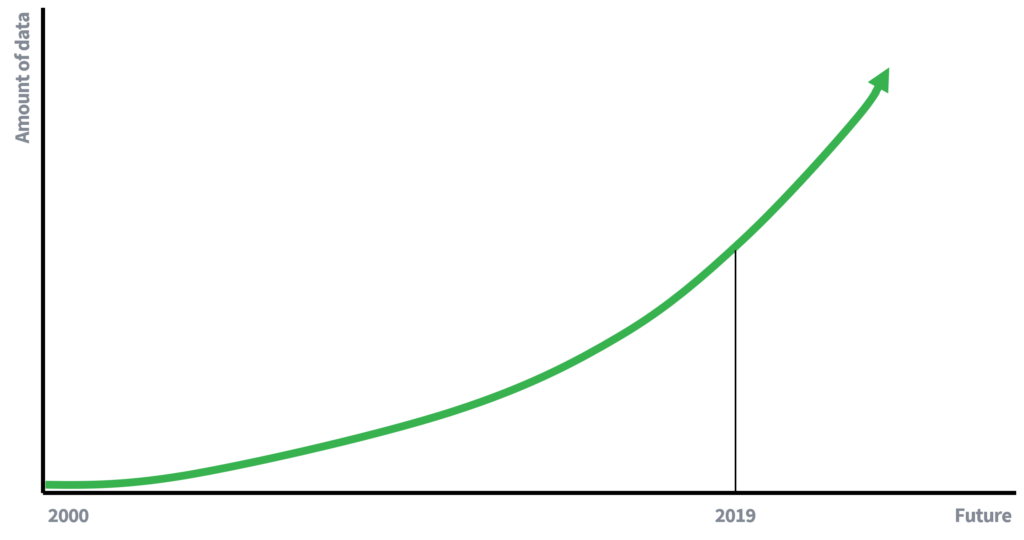
ໃນສະໄກ່ອນ, ການມີຂໍ້ມູນແມ່ນມີ ຈຳ ກັດຫຼາຍ, ເຊິ່ງບາງສ່ວນອະທິບາຍວ່າເປັນຫຍັງການລຶບຊື່ແມ່ນພຽງພໍເພື່ອຮັກສາຄວາມເປັນສ່ວນຕົວຂອງບຸກຄົນ. ຂໍ້ມູນທີ່ມີ ໜ້ອຍ ກວ່າmeansາຍເຖິງໂອກາດ ໜ້ອຍ ລົງ ສຳ ລັບການເຊື່ອມຕໍ່ຂໍ້ມູນ. ແນວໃດກໍ່ຕາມ, ດຽວນີ້ພວກເຮົາເປັນຜູ້ເຂົ້າຮ່ວມ (ຫ້າວຫັນ) ເຂົ້າໄປໃນເສດຖະກິດທີ່ອີງໃສ່ຂໍ້ມູນ, ບ່ອນທີ່ປະລິມານຂໍ້ມູນກໍາລັງເຕີບໂຕໃນອັດຕາການຂະຫຍາຍຕົວ. ຂໍ້ມູນເພີ່ມເຕີມ, ແລະການປັບປຸງເຕັກໂນໂລຍີສໍາລັບການເກັບກໍາຂໍ້ມູນຈະນໍາໄປສູ່ທ່າແຮງເພີ່ມຂຶ້ນສໍາລັບການໂຈມຕີການເຊື່ອມໂຍງ. ຄົນ ໜຶ່ງ ຈະຂຽນອັນໃດໃນ 10 ປີກ່ຽວກັບຄວາມສ່ຽງຂອງການໂຈມຕີການເຊື່ອມໂຍງ?
ພາບປະກອບ 1
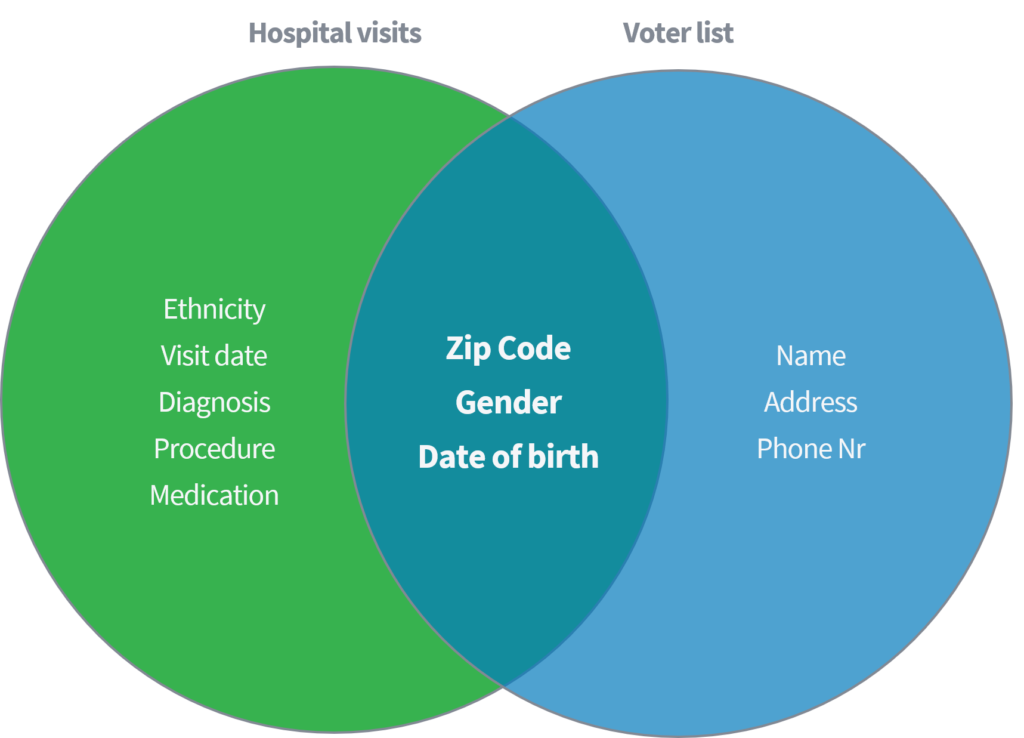
Sweeney (2002) ໄດ້ສະແດງໃຫ້ເຫັນຢູ່ໃນເອກະສານທາງວິຊາການວ່ານາງສາມາດກໍານົດແລະເກັບເອົາຂໍ້ມູນທາງການແພດທີ່ລະອຽດອ່ອນໄດ້ຈາກບຸກຄົນໂດຍອີງໃສ່ການເຊື່ອມຕໍ່ຊຸດຂໍ້ມູນສາທາລະນະຂອງ 'ການໄປຢ້ຽມຢາມໂຮງ'ໍ' ກັບຜູ້ລົງທະບຽນລົງຄະແນນສຽງທີ່ມີຢູ່ໃນສະຫະລັດ. ທັງສອງຊຸດຂໍ້ມູນທີ່ສົມມຸດວ່າຈະບໍ່ເປີດເຜີຍຊື່ຢ່າງຖືກຕ້ອງຜ່ານການລຶບຊື່ແລະຕົວລະບຸໂດຍກົງອື່ນ other.
ພາບປະກອບ 2
ອີງໃສ່ພຽງແຕ່ສາມຕົວກໍານົດການ (1) ລະຫັດໄປສະນີ, (2) ເພດແລະ (3) ວັນເດືອນປີເກີດ, ນາງໄດ້ສະແດງໃຫ້ເຫັນວ່າ 87% ຂອງປະຊາກອນທັງUSົດຂອງສະຫະລັດສາມາດຖືກກໍານົດຄືນໃby່ໄດ້ໂດຍການຈັບຄູ່ຄຸນສົມບັດທີ່ກ່າວມາຂ້າງເທິງຈາກທັງສອງຊຸດຂໍ້ມູນ. ຫຼັງຈາກນັ້ນ Sweeney ໄດ້ເຮັດວຽກຊໍ້າຄືນກັບການມີ 'ປະເທດ' ເປັນທາງເລືອກໃຫ້ກັບ 'ລະຫັດໄປສະນີ'. ນອກຈາກນັ້ນ, ນາງໄດ້ສະແດງໃຫ້ເຫັນວ່າ 18% ຂອງປະຊາກອນທັງUSົດຂອງສະຫະລັດສາມາດຖືກລະບຸໄດ້ໂດຍການເຂົ້າເຖິງຊຸດຂໍ້ມູນທີ່ບັນຈຸຂໍ້ມູນກ່ຽວກັບ (1) ປະເທດ, (2) ເພດແລະ (3) ວັນເດືອນປີເກີດ. ຄິດກ່ຽວກັບແຫຼ່ງຂໍ້ມູນສາທາລະນະທີ່ໄດ້ກ່າວມາຂ້າງເທິງ, ເຊັ່ນ: Facebook, LinkedIn ຫຼື Instagram. ປະເທດ, ເພດແລະວັນເດືອນປີເກີດຂອງເຈົ້າສາມາດເບິ່ງເຫັນໄດ້, ຫຼືຜູ້ໃຊ້ຄົນອື່ນສາມາດຫັກມັນໄດ້ບໍ?
ພາບປະກອບ 3
| ຕົວລະບຸ Quasi | % ລະບຸ ຈຳ ນວນປະຊາກອນສະຫະລັດເປັນເອກະລັກ (248 ລ້ານຄົນ) |
| ລະຫັດໄປສະນີ 5 ຕົວເລກ, ເພດ, ວັນເດືອນປີເກີດ | 87% |
| ສະຖານທີ່, ເພດ, ວັນເດືອນປີເກີດ | 53% |
| ປະເທດ, ເພດ, ວັນເດືອນປີເກີດ | 18% |
ຕົວຢ່າງນີ້ສະແດງໃຫ້ເຫັນວ່າມັນສາມາດເຮັດໃຫ້ບຸກຄົນໃນຂໍ້ມູນທີ່ບໍ່ເປີດເຜີຍຊື່ເປັນເລື່ອງງ່າຍຫຼາຍ. ທຳ ອິດ, ການສຶກສານີ້ຊີ້ບອກເຖິງຄວາມສ່ຽງອັນໃຫຍ່ຫຼວງ, ຄືກັບ 87% ຂອງປະຊາກອນສະຫະລັດສາມາດລະບຸໄດ້ງ່າຍໂດຍໃຊ້ ລັກສະນະບໍ່ຫຼາຍປານໃດ. ອັນທີສອງ, ຂໍ້ມູນທາງການແພດທີ່ເປີດເຜີຍຢູ່ໃນການສຶກສານີ້ແມ່ນມີຄວາມອ່ອນໄຫວສູງ. ຕົວຢ່າງຂອງຂໍ້ມູນບຸກຄົນທີ່ຖືກເປີດເຜີຍຈາກຊຸດຂໍ້ມູນການໄປຢ້ຽມຢາມໂຮງincludeໍປະກອບມີເຊື້ອຊາດ, ການກວດພະຍາດແລະການປິ່ນປົວ. ຄຸນລັກສະນະທີ່ຄົນເຮົາອາດຈະຮັກສາເປັນຄວາມລັບ, ຕົວຢ່າງ, ຈາກບໍລິສັດປະກັນໄພ.
ຄວາມສ່ຽງອີກອັນ ໜຶ່ງ ໃນການລຶບພຽງແຕ່ຕົວລະບຸຊື່ໂດຍກົງ, ເຊັ່ນ: ຊື່, ເກີດຂື້ນເມື່ອບຸກຄົນທີ່ມີຂໍ້ມູນຂ່າວສານມີຄວາມຮູ້ຫຼືຂໍ້ມູນດີກວ່າກ່ຽວກັບລັກສະນະຫຼືພຶດຕິ ກຳ ຂອງບຸກຄົນສະເພາະໃນຊຸດຂໍ້ມູນ. ອີງຕາມຄວາມຮູ້ຂອງເຂົາເຈົ້າ, ຈາກນັ້ນຜູ້ໂຈມຕີອາດຈະສາມາດເຊື່ອມຕໍ່ບັນທຶກຂໍ້ມູນສະເພາະກັບຄົນຕົວຈິງ.
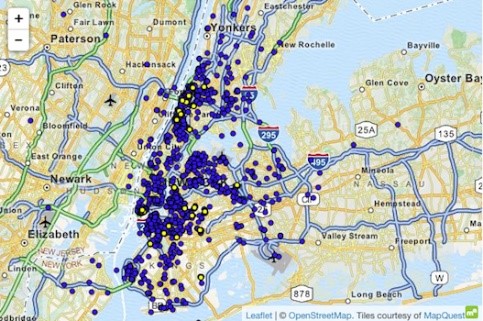
ຕົວຢ່າງຂອງການໂຈມຕີຊຸດຂໍ້ມູນໂດຍໃຊ້ຄວາມຮູ້ທີ່ ເໜືອກ ວ່າແມ່ນກໍລະນີລົດແທັກຊີ້ນິວຢອກ, ບ່ອນທີ່ Atockar (2014) ສາມາດເປີດເຜີຍບຸກຄົນສະເພາະ. ຊຸດຂໍ້ມູນທີ່ຈ້າງເຂົ້າເຮັດວຽກມີການເດີນທາງ taxi ທັງinົດຢູ່ໃນນິວຢອກ, ອຸດົມໄປດ້ວຍຄຸນລັກສະນະພື້ນຖານເຊັ່ນ: ຈຸດປະສານງານເລີ່ມຕົ້ນ, ຈຸດປະສານງານສຸດທ້າຍ, ລາຄາແລະປາຍທາງຂອງການຂີ່.
ບຸກຄົນທີ່ມີຂໍ້ມູນທີ່ຮູ້ວ່ານິວຢອກສາມາດເດີນທາງໄປ taxi ກັບສະໂມສອນຜູ້ໃຫຍ່ 'Hustler'. ໂດຍການກັ່ນຕອງ 'ສະຖານທີ່ສຸດ', ລາວໄດ້ຫັກເອົາທີ່ຢູ່ເລີ່ມຕົ້ນທີ່ແນ່ນອນແລະດ້ວຍເຫດນັ້ນຈຶ່ງໄດ້ລະບຸຜູ້ມາຢ້ຽມຢາມເລື້ອຍ various. ໃນ ທຳ ນອງດຽວກັນ, ຄົນ ໜຶ່ງ ສາມາດຫັກຄ່າຂີ່ລົດແທັກຊີເມື່ອທີ່ຢູ່ເຮືອນຂອງບຸກຄົນດັ່ງກ່າວຮູ້. ເວລາແລະສະຖານທີ່ຂອງດາລາ ໜັງ ທີ່ມີຊື່ສຽງຫຼາຍຄົນໄດ້ຖືກຄົ້ນພົບຢູ່ໃນເວັບໄຊທນິນທາ. ຫຼັງຈາກເຊື່ອມຕໍ່ຂໍ້ມູນນີ້ກັບຂໍ້ມູນລົດແທັກຊີ NYC, ມັນງ່າຍທີ່ຈະໄດ້ມາການຂີ່ລົດແທັກຊີ່ຂອງເຂົາເຈົ້າ, ຈໍານວນທີ່ເຂົາເຈົ້າໄດ້ຈ່າຍ, ແລະວ່າເຂົາເຈົ້າໄດ້ໃຫ້ຄໍາແນະນໍາຫຼືບໍ່.
ພາບປະກອບ 4
ການປະສານງານຫຼຸດລົງຂອງ Hustler
Bradley Cooper
Jessica Alba
ສາຍການໂຕ້ຖຽງທົ່ວໄປແມ່ນ 'ຂໍ້ມູນນີ້ບໍ່ມີຄ່າ' ຫຼື 'ບໍ່ມີໃຜສາມາດເຮັດອັນໃດກັບຂໍ້ມູນນີ້'. ອັນນີ້ມັກຈະເປັນຄວາມເຂົ້າໃຈຜິດ. ແມ່ນແຕ່ຂໍ້ມູນທີ່ບໍລິສຸດທີ່ສຸດສາມາດປະກອບເປັນລາຍນິ້ວມືທີ່ບໍ່ຊໍ້າກັນແລະຖືກໃຊ້ເພື່ອລະບຸບຸກຄົນຄືນໃ່. ມັນແມ່ນຄວາມສ່ຽງທີ່ໄດ້ມາຈາກການເຊື່ອວ່າຂໍ້ມູນຕົວມັນເອງບໍ່ມີຄ່າ, ໃນຂະນະທີ່ມັນບໍ່ແມ່ນ.
ຄວາມສ່ຽງຂອງການລະບຸຕົວຕົນຈະເພີ່ມຂຶ້ນດ້ວຍການເພີ່ມຂໍ້ມູນ, AI, ແລະເຄື່ອງມືແລະວິທີການອື່ນ other ທີ່ຊ່ວຍເປີດເຜີຍຄວາມສໍາພັນທີ່ຊັບຊ້ອນຢູ່ໃນຂໍ້ມູນ. ດັ່ງນັ້ນ, ເຖິງແມ່ນວ່າຊຸດຂໍ້ມູນຂອງເຈົ້າບໍ່ສາມາດຖືກເປີດເຜີຍໄດ້ໃນຕອນນີ້, ແລະອາດຈະບໍ່ມີປະໂຫຍດສໍາລັບບຸກຄົນທີ່ບໍ່ໄດ້ຮັບອະນຸຍາດໃນມື້ນີ້, ມັນອາດຈະບໍ່ແມ່ນມື້ອື່ນ.
ຕົວຢ່າງທີ່ດີແມ່ນກໍລະນີທີ່ Netflix ມີຈຸດປະສົງເພື່ອເຕົ້າໂຮມພະແນກ R&D ຂອງຕົນໂດຍການນໍາສະ ເໜີ ການແຂ່ງຂັນ Netflix ເປີດເພື່ອປັບປຸງລະບົບການແນະນໍາຮູບເງົາຂອງເຂົາເຈົ້າ. 'ອັນທີ່ປັບປຸງລະບົບການກັ່ນຕອງການຮ່ວມມືເພື່ອຄາດຄະເນການຈັດອັນດັບຜູ້ໃຊ້ສໍາລັບຮູບເງົາຊະນະລາງວັນ 1,000,000 ໂດລາສະຫະລັດ'. ເພື່ອສະ ໜັບ ສະ ໜູນ crowdູງຊົນ, Netflix ໄດ້ເຜີຍແຜ່ຊຸດຂໍ້ມູນທີ່ປະກອບມີພຽງແຕ່ຄຸນລັກສະນະພື້ນຖານດັ່ງຕໍ່ໄປນີ້: ຜູ້ໃຊ້, ຮູບເງົາ, ວັນທີແລະຊັ້ນຮຽນ (ດັ່ງນັ້ນບໍ່ມີຂໍ້ມູນເພີ່ມເຕີມກ່ຽວກັບຜູ້ໃຊ້ຫຼືຮູບເງົາເອງ).
ພາບປະກອບ 5
| ຜູ້ໃຊ້ | ຮູບເງົາ | ວັນທີຮຽນ | Grade |
| 123456789 | ພາລະກິດເປັນໄປບໍ່ໄດ້ | 10-12-2008 | 4 |
ຢູ່ໂດດດ່ຽວ, ຂໍ້ມູນປະກົດວ່າບໍ່ມີປະໂຫຍດ. ເມື່ອຖາມຄໍາຖາມ 'ມີຂໍ້ມູນລູກຄ້າຢູ່ໃນຊຸດຂໍ້ມູນທີ່ຄວນເກັບຮັກສາເປັນສ່ວນຕົວບໍ?', ຄໍາຕອບແມ່ນ:
'ບໍ່, ຂໍ້ມູນລະບຸຕົວຕົນລູກຄ້າທັງhasົດໄດ້ຖືກເອົາອອກໄປແລ້ວ; ສິ່ງທີ່ຍັງເຫຼືອແມ່ນການຈັດອັນດັບແລະວັນທີ. ອັນນີ້ປະຕິບັດຕາມນະໂຍບາຍຄວາມເປັນສ່ວນຕົວຂອງພວກເຮົາ ... '
ແນວໃດກໍ່ຕາມ, Narayanan (2008) ຈາກມະຫາວິທະຍາໄລ Texas ໃນ Austin ໄດ້ພິສູດຢ່າງອື່ນ. ການປະສົມປະສານຂອງຊັ້ນຮຽນ, ວັນທີຂອງຊັ້ນຮຽນແລະຮູບເງົາຂອງແຕ່ລະບຸກຄົນສ້າງເປັນລາຍນິ້ວມືຂອງຮູບເງົາທີ່ເປັນເອກະລັກ. ຄິດກ່ຽວກັບພຶດຕິກໍາ Netflix ຂອງເຈົ້າເອງ. ເຈົ້າຄິດວ່າມີຈັກຄົນທີ່ໄດ້ເບິ່ງຮູບເງົາຊຸດດຽວກັນ? ມີຈັກຄົນທີ່ໄດ້ເບິ່ງຮູບເງົາຊຸດດຽວກັນໃນເວລາດຽວກັນ?
ຄໍາຖາມຫຼັກ, ວິທີການຈັບຄູ່ລາຍນີ້ວມື? ມັນງ່າຍດາຍຫຼາຍ. ອີງຕາມຂໍ້ມູນຈາກເວັບໄຊທ rating ຈັດອັນດັບຮູບເງົາທີ່ມີຊື່ສຽງ IMDb (ຖານຂໍ້ມູນຮູບເງົາອິນເຕີເນັດ), ສາມາດສ້າງລາຍນິ້ວມືທີ່ຄ້າຍຄືກັນໄດ້. ຜົນສະທ້ອນ, ບຸກຄົນສາມາດໄດ້ຮັບການກໍານົດຄືນ.
ໃນຂະນະທີ່ພຶດຕິກໍາການເບິ່ງຮູບເງົາອາດຈະບໍ່ຖືວ່າເປັນຂໍ້ມູນທີ່ອ່ອນໄຫວ, ຄິດກ່ຽວກັບພຶດຕິກໍາຂອງເຈົ້າເອງ-ເຈົ້າຈະຄິດບໍຖ້າມັນຖືກເປີດເຜີຍຕໍ່ສາທາລະນະ? ຕົວຢ່າງທີ່ Narayanan ສະ ໜອງ ໃຫ້ໃນເຈ້ຍຂອງລາວແມ່ນຄວາມມັກທາງດ້ານການເມືອງ (ການຈັດອັນດັບ 'Jesus of Nazareth' ແລະ 'The Gospel of John') ແລະຄວາມມັກທາງເພດ (ການໃຫ້ຄະແນນ 'Bent' ແລະ 'Queer as folk') ທີ່ສາມາດກັ່ນໄດ້ງ່າຍ.
GDPR ອາດຈະບໍ່ເປັນສິ່ງທີ່ຕື່ນເຕັ້ນຫຼາຍ, ທັງບໍ່ແມ່ນຫົວຂໍ້ເງິນໃນບັນດາຫົວຂໍ້ blog. ແນວໃດກໍ່ຕາມ, ມັນເປັນປະໂຫຍດທີ່ຈະເຮັດໃຫ້ຄໍານິຍາມກົງໄປກົງມາເມື່ອປະມວນຜົນຂໍ້ມູນສ່ວນຕົວ. ເນື່ອງຈາກບລັອກນີ້ແມ່ນກ່ຽວກັບຄວາມເຂົ້າໃຈຜິດທົ່ວໄປຂອງການລຶບຖັນເພື່ອເປັນວິທີການປິດບັງຂໍ້ມູນແລະເພື່ອໃຫ້ຄວາມຮູ້ແກ່ເຈົ້າເປັນຜູ້ປະມວນຜົນຂໍ້ມູນ, ໃຫ້ພວກເຮົາເລີ່ມຕົ້ນດ້ວຍການສໍາຫຼວດຄໍານິຍາມຂອງການປິດບັງຊື່ຕາມ GDPR.
ອີງຕາມການເລົ່າຄືນ 26 ຈາກ GDPR, ຂໍ້ມູນທີ່ບໍ່ລະບຸຕົວຕົນໄດ້ຖືກກໍານົດເປັນ:
'ຂໍ້ມູນທີ່ບໍ່ກ່ຽວຂ້ອງກັບບຸກຄົນທໍາມະຊາດທີ່ໄດ້ກໍານົດຫຼືກໍານົດຕົນຕົວໄດ້ຫຼືຂໍ້ມູນສ່ວນຕົວທີ່ສະແດງອອກໂດຍບໍ່ເປີດເຜີຍຊື່ໃນລັກສະນະທີ່ຫົວຂໍ້ຂໍ້ມູນບໍ່ສາມາດຖືກກໍານົດຫຼືບໍ່ມີຕໍ່ໄປອີກແລ້ວ.'
ເນື່ອງຈາກວ່າຄົນ ໜຶ່ງ ປະມວນຜົນຂໍ້ມູນສ່ວນຕົວທີ່ກ່ຽວຂ້ອງກັບບຸກຄົນ ທຳ ມະດາ, ມີພຽງແຕ່ພາກສ່ວນ 2 ຂອງ ຄຳ ນິຍາມເທົ່ານັ້ນທີ່ກ່ຽວຂ້ອງ. ເພື່ອປະຕິບັດຕາມຄໍານິຍາມ, ຄົນເຮົາຕ້ອງຮັບປະກັນວ່າວິຊາຂໍ້ມູນ (ບຸກຄົນ) ບໍ່ສາມາດຖືກກໍານົດຫຼືບໍ່ມີອີກຕໍ່ໄປ. ແນວໃດກໍ່ຕາມທີ່ໄດ້ບົ່ງໄວ້ໃນ blog ນີ້, ມັນເປັນເລື່ອງງ່າຍດາຍຫຼາຍທີ່ຈະລະບຸບຸກຄົນໂດຍອີງຕາມຄຸນລັກສະນະບາງຢ່າງ. ສະນັ້ນ, ການລຶບຊື່ອອກຈາກຊຸດຂໍ້ມູນບໍ່ເປັນໄປຕາມຄໍານິຍາມ GDPR ຂອງການປິດບັງຊື່.
ພວກເຮົາໄດ້ທ້າທາຍອັນທີ່ພິຈາລະນາທົ່ວໄປແລະ, ແຕ່ ໜ້າ ເສຍດາຍ, ຍັງມີວິທີການທີ່ໃຊ້ເລື້ອຍ of ຂອງການປິດບັງຂໍ້ມູນການປິດບັງຊື່: ການລຶບຊື່. ໃນເກມ Guess Who ແລະຕົວຢ່າງອີກສີ່ຢ່າງກ່ຽວກັບ:
ມັນໄດ້ສະແດງໃຫ້ເຫັນວ່າການລຶບຊື່ລົ້ມເຫລວເປັນການປິດບັງຊື່. ເຖິງແມ່ນວ່າຕົວຢ່າງຕ່າງ cases ແມ່ນເປັນກໍລະນີທີ່ພົ້ນເດັ່ນ, ແຕ່ລະອັນສະແດງໃຫ້ເຫັນຄວາມງ່າຍຂອງການລະບຸຕົວຕົນຄືນໃ່ ແລະຜົນກະທົບທາງລົບທີ່ເປັນໄປໄດ້ຕໍ່ກັບຄວາມເປັນສ່ວນຕົວຂອງບຸກຄົນ.
ສະຫຼຸບແລ້ວ, ການລຶບຊື່ອອກຈາກຊຸດຂໍ້ມູນຂອງເຈົ້າບໍ່ໄດ້ສົ່ງຜົນໃຫ້ຂໍ້ມູນບໍ່ເປີດເຜີຍຊື່. ສະນັ້ນ, ພວກເຮົາຫຼີກລ້ຽງການ ນຳ ໃຊ້ທັງສອງ ຄຳ ສັບແລກປ່ຽນກັນດີກວ່າ. ຂ້ອຍຫວັງຢ່າງຈິງໃຈວ່າເຈົ້າຈະບໍ່ ນຳ ໃຊ້ວິທີການນີ້ເພື່ອການປິດບັງຊື່. ແລະຖ້າເຈົ້າຍັງເຮັດຢູ່, ຮັບປະກັນວ່າເຈົ້າແລະທີມງານຂອງເຈົ້າເຂົ້າໃຈຢ່າງເຕັມສ່ວນຄວາມສ່ຽງດ້ານຄວາມເປັນສ່ວນຕົວ, ແລະໄດ້ຮັບອະນຸຍາດໃຫ້ຍອມຮັບຄວາມສ່ຽງເຫຼົ່ານັ້ນໃນນາມຂອງບຸກຄົນທີ່ໄດ້ຮັບຜົນກະທົບ.
ຕິດຕໍ່ Syntho ແລະຫນຶ່ງໃນຜູ້ຊ່ຽວຊານຂອງພວກເຮົາຈະຕິດຕໍ່ກັບທ່ານດ້ວຍຄວາມໄວຂອງແສງເພື່ອຄົ້ນຫາມູນຄ່າຂອງຂໍ້ມູນສັງເຄາະ!