


સિન્થો દ્વારા જનરેટ કરવામાં આવેલ સિન્થેટિક ડેટા SAS ના ડેટા નિષ્ણાતો દ્વારા બાહ્ય અને ઉદ્દેશ્ય દૃષ્ટિકોણથી મૂલ્યાંકન, માન્ય અને મંજૂર કરવામાં આવે છે.
જોકે સિન્થો તેના વપરાશકર્તાઓને અદ્યતન ગુણવત્તા ખાતરી અહેવાલ પ્રદાન કરવા માટે ગર્વ અનુભવે છે, અમે ઉદ્યોગના નેતાઓ પાસેથી અમારા સિન્થેટિક ડેટાનું બાહ્ય અને ઉદ્દેશ્ય મૂલ્યાંકન કરવાના મહત્વને પણ સમજીએ છીએ. તેથી જ અમે અમારા સિન્થેટિક ડેટાનું મૂલ્યાંકન કરવા માટે SAS, વિશ્લેષણમાં અગ્રેસર, સાથે સહયોગ કરીએ છીએ.
SAS મૂળ ડેટાની સરખામણીમાં સિન્થોના AI-જનરેટેડ સિન્થેટિક ડેટાની ડેટા-ચોક્કસતા, ગોપનીયતા સુરક્ષા અને ઉપયોગિતા પર વિવિધ સંપૂર્ણ મૂલ્યાંકન કરે છે. નિષ્કર્ષ તરીકે, SAS એ સિન્થોના સિન્થેટિક ડેટાનું મૂલ્યાંકન કર્યું અને મંજૂર કર્યું કારણ કે મૂળ ડેટાની સરખામણીમાં સચોટ, સુરક્ષિત અને ઉપયોગી છે.
અમે ટેલિકોમ ડેટાનો ઉપયોગ કર્યો જેનો ઉપયોગ લક્ષ્ય ડેટા તરીકે "મંથન" આગાહી માટે થાય છે. મૂલ્યાંકનનો ધ્યેય વિવિધ મંથન અનુમાન મોડેલોને તાલીમ આપવા અને દરેક મોડેલની કામગીરીનું મૂલ્યાંકન કરવા માટે સિન્થેટિક ડેટાનો ઉપયોગ કરવાનો હતો. જેમ કે મંથન આગાહી એ વર્ગીકરણ કાર્ય છે, SAS એ આગાહી કરવા માટે લોકપ્રિય વર્ગીકરણ મોડલ પસંદ કર્યા, જેમાં નીચેનાનો સમાવેશ થાય છે:
સિન્થેટીક ડેટા જનરેટ કરતા પહેલા, SAS એ ટેલિકોમ ડેટાસેટને રેન્ડમલી ટ્રેન સેટ (મોડલ્સની તાલીમ માટે) અને હોલ્ડઆઉટ સેટ (મોડલ્સ સ્કોર કરવા માટે) માં વિભાજિત કરે છે. સ્કોરિંગ માટે અલગ હોલ્ડઆઉટ સેટ રાખવાથી નવા ડેટા પર લાગુ કરવામાં આવે ત્યારે વર્ગીકરણ મોડલ કેટલું સારું કરી શકે છે તેના નિષ્પક્ષ મૂલ્યાંકન માટે પરવાનગી આપે છે.
ઇનપુટ તરીકે ટ્રેન સેટનો ઉપયોગ કરીને, સિન્થોએ સિન્થેટિક ડેટાસેટ જનરેટ કરવા માટે તેના સિન્થો એન્જિનનો ઉપયોગ કર્યો. બેન્ચમાર્કિંગ માટે, SAS એ ચોક્કસ થ્રેશોલ્ડ (k-અનામીની) સુધી પહોંચવા માટે વિવિધ અનામી તકનીકો લાગુ કર્યા પછી ટ્રેન સેટનું એક અનામી સંસ્કરણ પણ બનાવ્યું છે. અગાઉના પગલાં ચાર ડેટાસેટ્સમાં પરિણમ્યા:
ડેટાસેટ્સ 1, 3 અને 4 નો ઉપયોગ દરેક વર્ગીકરણ મોડેલને તાલીમ આપવા માટે કરવામાં આવ્યો હતો, જેના પરિણામે 12 (3 x 4) પ્રશિક્ષિત મોડલ બન્યા હતા. SAS એ પછીથી ગ્રાહક મંથનની આગાહીમાં દરેક મોડેલની ચોકસાઈને માપવા માટે હોલ્ડઆઉટ ડેટાસેટનો ઉપયોગ કર્યો.
SAS મૂળ ડેટાની સરખામણીમાં સિન્થોના AI-જનરેટેડ સિન્થેટિક ડેટાની ડેટા-ચોક્કસતા, ગોપનીયતા સુરક્ષા અને ઉપયોગિતા પર વિવિધ સંપૂર્ણ મૂલ્યાંકન કરે છે. નિષ્કર્ષ તરીકે, SAS એ સિન્થોના સિન્થેટિક ડેટાનું મૂલ્યાંકન કર્યું અને મંજૂર કર્યું કારણ કે મૂળ ડેટાની સરખામણીમાં સચોટ, સુરક્ષિત અને ઉપયોગી છે.
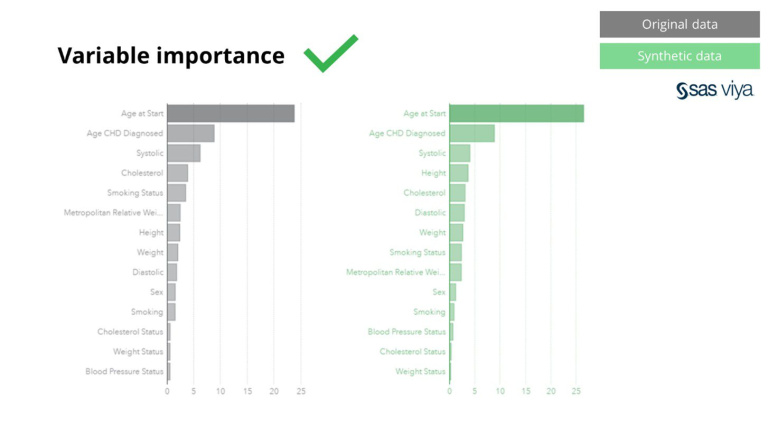
સિન્થોમાંથી કૃત્રિમ ડેટા માત્ર મૂળભૂત પેટર્ન માટે જ નથી, તે અદ્યતન વિશ્લેષણાત્મક કાર્યો માટે જરૂરી ઊંડા 'છુપાયેલા' આંકડાકીય દાખલાઓ પણ ધરાવે છે. બાદમાં બાર ચાર્ટમાં દર્શાવવામાં આવ્યું છે, જે દર્શાવે છે કે સિન્થેટીક ડેટા પર પ્રશિક્ષિત મોડલની ચોકસાઈ વિરુદ્ધ મૂળ ડેટા પર પ્રશિક્ષિત મોડલ્સ સમાન છે. તેથી, કૃત્રિમ ડેટાનો ઉપયોગ મોડેલોની વાસ્તવિક તાલીમ માટે થઈ શકે છે. મૂળ ડેટાની તુલનામાં સિન્થેટીક ડેટા પર અલ્ગોરિધમ્સ દ્વારા પસંદ કરાયેલ ઇનપુટ્સ અને ચલ મહત્વ ખૂબ સમાન હતા. આથી, એવું તારણ કાઢવામાં આવે છે કે વાસ્તવિક સંવેદનશીલ ડેટાનો ઉપયોગ કરવાના વિકલ્પ તરીકે, મોડેલિંગ પ્રક્રિયા સિન્થેટીક ડેટા પર કરી શકાય છે.
ક્લાસિક અનામીકરણ તકનીકોમાં સામાન્ય છે કે તેઓ વ્યક્તિઓને શોધી કાઢવામાં અવરોધ લાવવા માટે મૂળ ડેટાની હેરફેર કરે છે. તેઓ ડેટાની હેરફેર કરે છે અને પ્રક્રિયામાં ડેટાનો નાશ કરે છે. તમે જેટલા વધુ અનામી કરશો, તમારો ડેટા વધુ સારી રીતે સુરક્ષિત રહેશે, પરંતુ તેટલો તમારો ડેટા નાશ પામશે. આ ખાસ કરીને AI અને મોડેલિંગ કાર્યો માટે વિનાશક છે જ્યાં "અનુમાનિત શક્તિ" આવશ્યક છે, કારણ કે ખરાબ ગુણવત્તાવાળા ડેટાના પરિણામે AI મોડેલની ખરાબ આંતરદૃષ્ટિ થશે. SAS એ 0.5 ની નજીકના વળાંક (AUC*) હેઠળના વિસ્તાર સાથે આ દર્શાવ્યું છે, જે દર્શાવે છે કે અનામી ડેટા પર પ્રશિક્ષિત મોડલ્સ સૌથી ખરાબ પ્રદર્શન કરે છે.
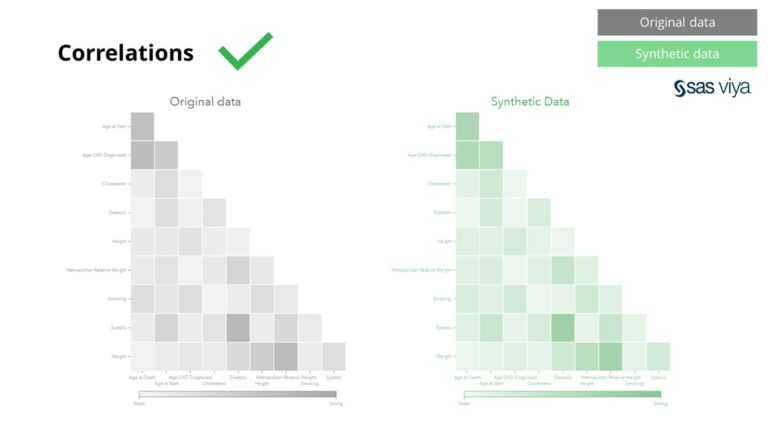
ચલો વચ્ચેના સહસંબંધો અને સંબંધો સિન્થેટિક ડેટામાં સચોટ રીતે સાચવવામાં આવ્યા હતા.
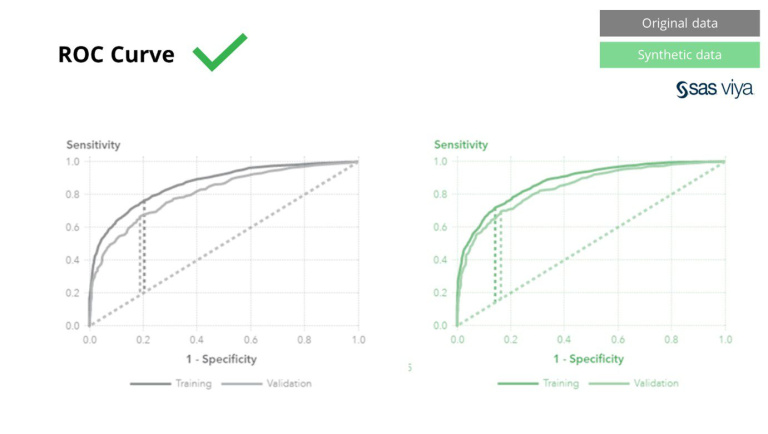
એરિયા અંડર ધ કર્વ (AUC), મોડલની કામગીરીને માપવા માટેનું એક મેટ્રિક, સુસંગત રહ્યું.
વધુમાં, ચલ મહત્વ, જે મોડેલમાં ચલોની આગાહી શક્તિ દર્શાવે છે, જ્યારે સિન્થેટીક ડેટાને મૂળ ડેટાસેટ સાથે સરખાવવામાં આવે ત્યારે અકબંધ રહે છે.
SAS દ્વારા અને SAS Viya નો ઉપયોગ કરીને આ અવલોકનોના આધારે, અમે વિશ્વાસપૂર્વક નિષ્કર્ષ પર આવી શકીએ છીએ કે સિન્થો એન્જિન દ્વારા જનરેટ કરવામાં આવેલ સિન્થેટિક ડેટા ખરેખર ગુણવત્તાની દ્રષ્ટિએ વાસ્તવિક ડેટાની સમકક્ષ છે. આ મોડેલ ડેવલપમેન્ટ માટે સિન્થેટિક ડેટાના ઉપયોગને માન્ય કરે છે, સિન્થેટિક ડેટા સાથે એડવાન્સ એનાલિટિક્સ માટે માર્ગ મોકળો કરે છે.
