AI-જનરેટેડ સિન્થેટિક ડેટા, ઉચ્ચ ગુણવત્તાવાળા ડેટાની સરળ અને ઝડપી ઍક્સેસ?
AI વ્યવહારમાં કૃત્રિમ ડેટા જનરેટ કરે છે
સિન્થો, AI-જનરેટેડ સિન્થેટિક ડેટાના નિષ્ણાત છે, તેનો હેતુ ચાલુ કરવાનો છે privacy by design AI-જનરેટેડ સિન્થેટિક ડેટા સાથે સ્પર્ધાત્મક લાભમાં. તેઓ સંસ્થાઓને ઉચ્ચ ગુણવત્તાવાળા ડેટાની સરળ અને ઝડપી ઍક્સેસ સાથે મજબૂત ડેટા ફાઉન્ડેશન બનાવવામાં મદદ કરે છે અને તાજેતરમાં ફિલિપ્સ ઇનોવેશન એવોર્ડ જીત્યો હતો.
જો કે, AI સાથે સિન્થેટીક ડેટા જનરેશન એ પ્રમાણમાં નવો ઉકેલ છે જે સામાન્ય રીતે વારંવાર પૂછાતા પ્રશ્નો રજૂ કરે છે. આનો જવાબ આપવા માટે, સિન્થોએ એડવાન્સ્ડ એનાલિટિક્સ અને AI સોફ્ટવેરમાં માર્કેટ લીડર SAS સાથે મળીને કેસ-સ્ટડી શરૂ કરી.
ડચ AI ગઠબંધન (NL AIC) ના સહયોગમાં, તેઓએ ડેટા ગુણવત્તા, કાનૂની માન્યતા અને ઉપયોગિતા પરના વિવિધ મૂલ્યાંકનો દ્વારા સિન્થો એન્જિન દ્વારા જનરેટ કરાયેલ AI-જનરેટેડ સિન્થેટિક ડેટાની મૂળ ડેટા સાથે સરખામણી કરીને સિન્થેટિક ડેટાના મૂલ્યની તપાસ કરી.
શું ડેટા અનામીકરણ એ ઉકેલ નથી?
ક્લાસિક અનામીકરણ તકનીકોમાં સામાન્ય છે કે તેઓ વ્યક્તિઓને શોધી કાઢવામાં અવરોધ લાવવા માટે મૂળ ડેટાની હેરફેર કરે છે. ઉદાહરણો સામાન્યીકરણ, દમન, વાઇપિંગ, સ્યુડોનામાઇઝેશન, ડેટા માસ્કિંગ અને પંક્તિઓ અને કૉલમનું શફલિંગ છે. તમે નીચેના કોષ્ટકમાં ઉદાહરણો શોધી શકો છો.
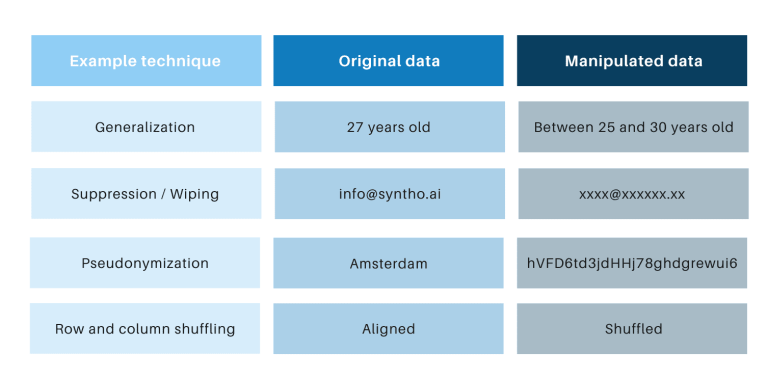
તે તકનીકો 3 મુખ્ય પડકારો રજૂ કરે છે:
- તેઓ ડેટા પ્રકાર અને ડેટાસેટ દીઠ અલગ રીતે કાર્ય કરે છે, જેનાથી તેમને માપવામાં મુશ્કેલી પડે છે. વધુમાં, તેઓ અલગ રીતે કામ કરતા હોવાથી, કઈ પદ્ધતિઓ લાગુ કરવી અને કઈ તકનીકોના સંયોજનની જરૂર છે તે વિશે હંમેશા ચર્ચા થશે.
- મૂળ ડેટા સાથે હંમેશા એક-થી-એક સંબંધ હોય છે. આનો અર્થ એ છે કે ત્યાં હંમેશા ગોપનીયતાનું જોખમ રહેશે, ખાસ કરીને તમામ ખુલ્લા ડેટાસેટ્સ અને તે ડેટાસેટ્સને લિંક કરવાની ઉપલબ્ધ તકનીકોને કારણે.
- તેઓ ડેટાની હેરફેર કરે છે અને પ્રક્રિયામાં ડેટાનો નાશ કરે છે. આ ખાસ કરીને AI કાર્યો માટે વિનાશક છે જ્યાં "અનુમાનિત શક્તિ" આવશ્યક છે, કારણ કે ખરાબ ગુણવત્તાનો ડેટા AI મોડલની ખરાબ આંતરદૃષ્ટિમાં પરિણમશે (ગાર્બેજ-ઇન કચરામાં પરિણમશે).
આ મુદ્દાઓનું મૂલ્યાંકન પણ આ કેસ સ્ટડી દ્વારા કરવામાં આવે છે.
કેસ સ્ટડીનો પરિચય
કેસ સ્ટડી માટે, લક્ષ્ય ડેટાસેટ SAS દ્વારા પ્રદાન કરવામાં આવેલ ટેલિકોમ ડેટાસેટ હતો જેમાં 56.600 ગ્રાહકોનો ડેટા હતો. ડેટાસેટમાં 128 કૉલમ છે, જેમાં એક કૉલમનો સમાવેશ થાય છે જે દર્શાવે છે કે ગ્રાહકે કંપની છોડી દીધી છે (એટલે કે 'મંથન') કે નહીં. કેસ સ્ટડીનો ધ્યેય ગ્રાહક મંથનનું અનુમાન કરવા અને તે પ્રશિક્ષિત મોડેલોના પ્રદર્શનનું મૂલ્યાંકન કરવા માટે કેટલાક મોડેલોને તાલીમ આપવા માટે સિન્થેટિક ડેટાનો ઉપયોગ કરવાનો હતો. જેમ કે મંથન આગાહી એ વર્ગીકરણ કાર્ય છે, SAS એ આગાહી કરવા માટે ચાર લોકપ્રિય વર્ગીકરણ મોડલ પસંદ કર્યા, જેમાં નીચેનાનો સમાવેશ થાય છે:
- રેન્ડમ વન
- ગ્રેડિયન્ટ બુસ્ટિંગ
- લોજિસ્ટિક રીગ્રેસન
- ન્યુરલ નેટવર્ક
સિન્થેટીક ડેટા જનરેટ કરતા પહેલા, SAS એ ટેલિકોમ ડેટાસેટને રેન્ડમલી ટ્રેન સેટ (મોડલ્સની તાલીમ માટે) અને હોલ્ડઆઉટ સેટ (મોડલ્સ સ્કોર કરવા માટે) માં વિભાજિત કરે છે. સ્કોરિંગ માટે અલગ હોલ્ડઆઉટ સેટ રાખવાથી નવા ડેટા પર લાગુ કરવામાં આવે ત્યારે વર્ગીકરણ મોડલ કેટલું સારું પ્રદર્શન કરી શકે છે તેના નિષ્પક્ષ મૂલ્યાંકન માટે પરવાનગી આપે છે.
ઇનપુટ તરીકે ટ્રેન સેટનો ઉપયોગ કરીને, સિન્થોએ સિન્થેટિક ડેટાસેટ જનરેટ કરવા માટે તેના સિન્થો એન્જિનનો ઉપયોગ કર્યો. બેન્ચમાર્કિંગ માટે, SAS એ ચોક્કસ થ્રેશોલ્ડ (k-અનામીતાની) સુધી પહોંચવા માટે વિવિધ અનામી તકનીકો લાગુ કર્યા પછી ટ્રેન સેટનું એક હેરફેર વર્ઝન પણ બનાવ્યું હતું. અગાઉના પગલાં ચાર ડેટાસેટ્સમાં પરિણમ્યા:
- ટ્રેન ડેટાસેટ (એટલે કે મૂળ ડેટાસેટ હોલ્ડઆઉટ ડેટાસેટ બાદ)
- હોલ્ડઆઉટ ડેટાસેટ (એટલે કે મૂળ ડેટાસેટનો સબસેટ)
- એક અનામી ડેટાસેટ (ટ્રેન ડેટાસેટ પર આધારિત)
- સિન્થેટિક ડેટાસેટ (ટ્રેન ડેટાસેટ પર આધારિત)
ડેટાસેટ્સ 1, 3 અને 4 નો ઉપયોગ દરેક વર્ગીકરણ મોડેલને તાલીમ આપવા માટે કરવામાં આવ્યો હતો, જેના પરિણામે 12 (3 x 4) પ્રશિક્ષિત મોડલ બન્યા હતા. ત્યારબાદ SAS એ ચોકસાઈને માપવા માટે હોલ્ડઆઉટ ડેટાસેટનો ઉપયોગ કર્યો હતો જેની સાથે દરેક મોડેલ ગ્રાહક મંથનની આગાહી કરે છે. કેટલાક મૂળભૂત આંકડાઓથી શરૂ કરીને પરિણામો નીચે પ્રસ્તુત છે.
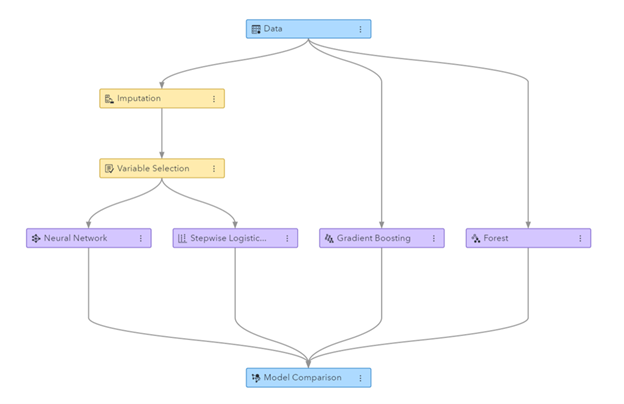
આકૃતિ: SAS વિઝ્યુઅલ ડેટા માઇનિંગ અને મશીન લર્નિંગમાં જનરેટ થયેલ મશીન લર્નિંગ પાઇપલાઇન
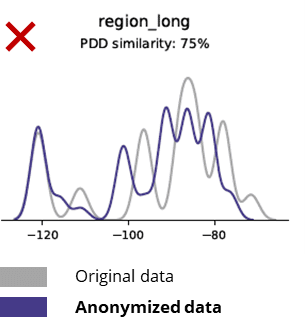
મૂળ ડેટા સાથે અનામી ડેટાની સરખામણી કરતી વખતે મૂળભૂત આંકડા
અનામીકરણ તકનીકો મૂળભૂત પેટર્ન, વ્યવસાય તર્ક, સંબંધો અને આંકડાઓનો પણ નાશ કરે છે (નીચેના ઉદાહરણમાં). મૂળભૂત એનાલિટિક્સ માટે અનામી ડેટાનો ઉપયોગ આમ અવિશ્વસનીય પરિણામો ઉત્પન્ન કરે છે. વાસ્તવમાં, અનામી ડેટાની નબળી ગુણવત્તાએ તેને અદ્યતન વિશ્લેષણાત્મક કાર્યો (દા.ત. AI/ML મોડેલિંગ અને ડેશબોર્ડિંગ) માટે વાપરવાનું લગભગ અશક્ય બનાવી દીધું હતું.
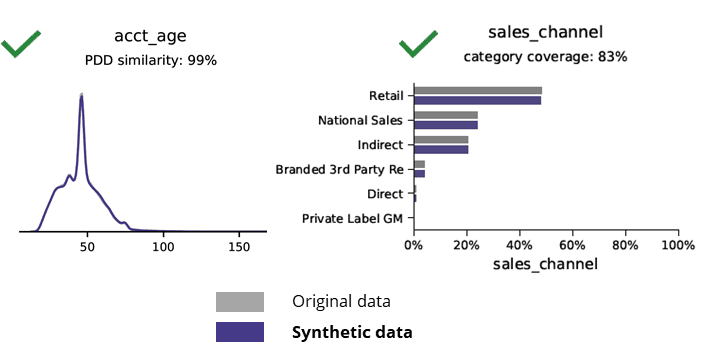
મૂળ ડેટા સાથે સિન્થેટિક ડેટાની સરખામણી કરતી વખતે મૂળભૂત આંકડા
AI સાથે કૃત્રિમ ડેટા જનરેશન મૂળભૂત પેટર્ન, વ્યવસાયિક તર્ક, સંબંધો અને આંકડાઓ (નીચેના ઉદાહરણ તરીકે) સાચવે છે. મૂળભૂત વિશ્લેષણ માટે કૃત્રિમ ડેટાનો ઉપયોગ આમ વિશ્વસનીય પરિણામો ઉત્પન્ન કરે છે. મુખ્ય પ્રશ્ન, શું અદ્યતન એનાલિટિક્સ કાર્યો (દા.ત. AI/ML મોડેલિંગ અને ડેશબોર્ડિંગ) માટે સિન્થેટિક ડેટા ધરાવે છે?
AI-જનરેટેડ સિન્થેટિક ડેટા અને એડવાન્સ એનાલિટિક્સ
સિન્થેટિક ડેટા માત્ર મૂળભૂત પેટર્ન માટે જ નહીં (ભૂતપૂર્વ પ્લોટમાં બતાવ્યા પ્રમાણે), તે અદ્યતન વિશ્લેષણાત્મક કાર્યો માટે જરૂરી ઊંડા 'છુપાયેલા' આંકડાકીય પેટર્નને પણ કબજે કરે છે. બાદમાં નીચેના બાર ચાર્ટમાં દર્શાવવામાં આવ્યું છે, જે દર્શાવે છે કે સિન્થેટીક ડેટા પર પ્રશિક્ષિત મોડલની ચોકસાઈ વિરુદ્ધ મૂળ ડેટા પર પ્રશિક્ષિત મોડલ્સ સમાન છે. વધુમાં, વળાંક (AUC*) હેઠળ 0.5 ની નજીકના વિસ્તાર સાથે, અનામી ડેટા પર પ્રશિક્ષિત મોડલ્સ અત્યાર સુધી સૌથી ખરાબ પ્રદર્શન કરે છે. મૂળ ડેટાની તુલનામાં સિન્થેટિક ડેટા પરના તમામ અદ્યતન વિશ્લેષણાત્મક મૂલ્યાંકનો સાથેનો સંપૂર્ણ અહેવાલ વિનંતી પર ઉપલબ્ધ છે.
*AUC: વળાંક હેઠળનો વિસ્તાર એ અદ્યતન એનાલિટિક્સ મોડલ્સની ચોકસાઈ માટેનું માપ છે, જેમાં સાચા હકારાત્મક, ખોટા હકારાત્મક, ખોટા નકારાત્મક અને સાચા નકારાત્મકને ધ્યાનમાં લેવામાં આવે છે. 0,5 નો અર્થ એ છે કે મોડેલ રેન્ડમલી આગાહી કરે છે અને તેમાં કોઈ આગાહી શક્તિ નથી અને 1 નો અર્થ છે કે મોડેલ હંમેશા સાચું હોય છે અને સંપૂર્ણ આગાહી શક્તિ ધરાવે છે.
વધુમાં, આ કૃત્રિમ ડેટાનો ઉપયોગ ડેટા લાક્ષણિકતાઓ અને મોડેલોની વાસ્તવિક તાલીમ માટે જરૂરી મુખ્ય ચલોને સમજવા માટે કરી શકાય છે. મૂળ ડેટાની તુલનામાં સિન્થેટીક ડેટા પર અલ્ગોરિધમ્સ દ્વારા પસંદ કરાયેલ ઇનપુટ્સ ખૂબ સમાન હતા. આથી, આ કૃત્રિમ સંસ્કરણ પર મોડેલિંગ પ્રક્રિયા કરી શકાય છે, જે ડેટા ભંગનું જોખમ ઘટાડે છે. જો કે, જ્યારે વ્યક્તિગત રેકોર્ડ્સ (દા.ત. ટેલ્કો ગ્રાહક) નો અનુમાન લગાવવામાં આવે છે, ત્યારે સ્પષ્ટતા, સ્વીકૃતિમાં વધારો અથવા માત્ર નિયમનના કારણે મૂળ ડેટા પર ફરીથી તાલીમ આપવાની ભલામણ કરવામાં આવે છે.
પદ્ધતિ દ્વારા જૂથબદ્ધ અલ્ગોરિધમ દ્વારા AUC
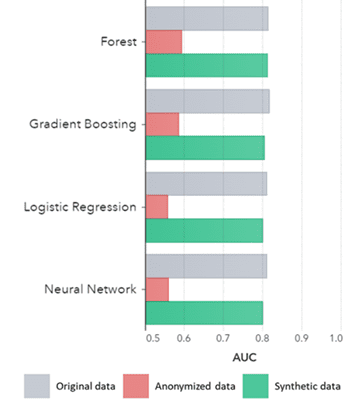
તારણો:
- મૂળ ડેટા પર પ્રશિક્ષિત મૉડલ્સની સરખામણીમાં સિન્થેટિક ડેટા પર પ્રશિક્ષિત મૉડલ્સ ખૂબ સમાન કામગીરી દર્શાવે છે
- 'ક્લાસિક અનામીકરણ તકનીકો' સાથે અનામી ડેટા પર પ્રશિક્ષિત મૉડલ્સ મૂળ ડેટા અથવા સિન્થેટિક ડેટા પર પ્રશિક્ષિત મૉડલ્સની સરખામણીમાં હલકી ગુણવત્તાનું પ્રદર્શન દર્શાવે છે.
- સિન્થેટીક ડેટા જનરેશન સરળ અને ઝડપી છે કારણ કે ટેકનીક પ્રતિ ડેટાસેટ અને ડેટા પ્રકાર દીઠ બરાબર સમાન કામ કરે છે.
મૂલ્ય-ઉમેરતી સિન્થેટિક ડેટાના ઉપયોગના કિસ્સાઓ
કેસ 1 નો ઉપયોગ કરો: મોડેલ ડેવલપમેન્ટ અને એડવાન્સ એનાલિટિક્સ માટે સિન્થેટિક ડેટા
મૉડલ્સ (દા.ત. ડેશબોર્ડ [BI] અને અદ્યતન એનાલિટિક્સ [AI અને ML]) વિકસાવવા માટે વાપરી શકાય તેવા, ઉચ્ચ ગુણવત્તાવાળા ડેટાની સરળ અને ઝડપી ઍક્સેસ સાથે મજબૂત ડેટા ફાઉન્ડેશન હોવું આવશ્યક છે. જો કે, ઘણી સંસ્થાઓ સબઓપ્ટીમલ ડેટા ફાઉન્ડેશનથી પીડાય છે જેના પરિણામે 3 મુખ્ય પડકારો છે:
- ડેટાની accessક્સેસ મેળવવા માટે (ગોપનીયતા) નિયમો, આંતરિક પ્રક્રિયાઓ અથવા ડેટા સિલોને કારણે વય લાગે છે
- ક્લાસિક અનામીકરણ તકનીકો ડેટાનો નાશ કરે છે, જેનાથી ડેટા વિશ્લેષણ અને અદ્યતન વિશ્લેષણ માટે યોગ્ય નથી (કચરામાં = ગાર્બેજ આઉટ)
- હાલના સોલ્યુશન્સ સ્કેલેબલ નથી કારણ કે તે ડેટાસેટ દીઠ અને ડેટા પ્રકાર દીઠ અલગ રીતે કાર્ય કરે છે અને મોટા મલ્ટી-ટેબલ ડેટાબેઝને હેન્ડલ કરી શકતા નથી
સિન્થેટીક ડેટા અભિગમ: વાસ્તવિક સિન્થેટીક ડેટા જેવા-સારા-સારા સાથે મોડલ વિકસાવો:
- તમારા વિકાસકર્તાઓને અવરોધ્યા વિના, મૂળ ડેટાનો ઉપયોગ ઓછો કરો
- વ્યક્તિગત ડેટાને અનલlockક કરો અને વધુ ડેટાની accessક્સેસ રાખો જે અગાઉ પ્રતિબંધિત હતી (દા.ત. ગોપનીયતાને કારણે)
- સંબંધિત ડેટામાં સરળ અને ઝડપી ડેટા ક્સેસ
- સ્કેલેબલ સોલ્યુશન જે દરેક ડેટાસેટ, ડેટાટાઇપ અને મોટા ડેટાબેઝ માટે સમાન કામ કરે છે
આ સંસ્થાને ડેટા અનલૉક કરવા અને ડેટાની તકોનો લાભ લેવા માટે ઉપયોગી, ઉચ્ચ ગુણવત્તાવાળા ડેટાની સરળ અને ઝડપી ઍક્સેસ સાથે મજબૂત ડેટા ફાઉન્ડેશન બનાવવાની મંજૂરી આપે છે.
કેસ 2 નો ઉપયોગ કરો: સોફ્ટવેર પરીક્ષણ, વિકાસ અને વિતરણ માટે સ્માર્ટ સિન્થેટિક ટેસ્ટ ડેટા
અત્યાધુનિક સોફ્ટવેર સોલ્યુશન્સ વિતરિત કરવા માટે ઉચ્ચ ગુણવત્તાવાળા પરીક્ષણ ડેટા સાથે પરીક્ષણ અને વિકાસ જરૂરી છે. મૂળ ઉત્પાદન ડેટાનો ઉપયોગ સ્પષ્ટ લાગે છે, પરંતુ (ગોપનીયતા) નિયમોને કારણે તેને મંજૂરી નથી. વૈકલ્પિક Test Data Management (TDM) સાધનો રજૂ કરે છે "legacy-by-design"પરીક્ષણ ડેટા યોગ્ય રીતે મેળવવામાં:
- ઉત્પાદન ડેટાને પ્રતિબિંબિત કરશો નહીં અને વ્યવસાયિક તર્ક અને સંદર્ભની અખંડિતતા સચવાઈ નથી
- ધીમું અને સમય માંગી લે તેવું કામ કરો
- મેન્યુઅલ વર્ક જરૂરી છે
સિન્થેટિક ડેટા અભિગમ: અત્યાધુનિક સોફ્ટવેર સોલ્યુશન્સ સ્માર્ટ વિતરિત કરવા માટે AI-જનરેટેડ સિન્થેટિક ટેસ્ટ ડેટા સાથે પરીક્ષણ અને વિકાસ કરો:
- સાચવેલ વ્યવસાય તર્ક અને સંદર્ભની અખંડિતતા સાથે ઉત્પાદન જેવો ડેટા
- અત્યાધુનિક AI સાથે સરળ અને ઝડપી ડેટા જનરેશન
- ગોપનીયતા દ્વારા ડિઝાઇન
- સરળ, ઝડપી અને agile
આ સંસ્થાને અત્યાધુનિક સૉફ્ટવેર સોલ્યુશન્સ વિતરિત કરવા માટે આગલા-સ્તરના પરીક્ષણ ડેટા સાથે પરીક્ષણ અને વિકાસ કરવાની મંજૂરી આપે છે!
વધુ મહિતી
રસ? સિન્થેટિક ડેટા વિશે વધુ માહિતી માટે, સિન્થો વેબસાઇટની મુલાકાત લો અથવા Wim Kees Janssen નો સંપર્ક કરો. SAS વિશે વધુ માહિતી માટે, મુલાકાત લો www.sas.com અથવા kees@syntho.ai નો સંપર્ક કરો.
આ ઉપયોગના કિસ્સામાં, સિન્થો, SAS અને NL AIC ઇચ્છિત પરિણામો પ્રાપ્ત કરવા માટે સાથે મળીને કામ કરે છે. સિન્થો AI-જનરેટેડ સિન્થેટિક ડેટામાં નિષ્ણાત છે અને SAS એ એનાલિટિક્સમાં માર્કેટ લીડર છે અને ડેટાની શોધ, વિશ્લેષણ અને વિઝ્યુઅલાઈઝિંગ માટે સૉફ્ટવેર ઑફર કરે છે.
* 2021 ની આગાહી કરે છે - ડિજિટલ બિઝનેસ, ગાર્ટનર, 2020 ને સંચાલિત કરવા, સ્કેલ અને ટ્રાન્સફોર્મ કરવા માટે ડેટા અને એનાલિટિક્સ વ્યૂહરચના.

તમારી કૃત્રિમ ડેટા માર્ગદર્શિકા હવે સાચવો!
- કૃત્રિમ ડેટા શું છે?
- શા માટે સંસ્થાઓ તેનો ઉપયોગ કરે છે?
- સિન્થેટીક ડેટા ક્લાયંટ કેસોનું મૂલ્ય ઉમેરવું
- કેવી રીતે શરૂ કરવું
