કોણ ધારી? 5 ઉદાહરણો શા માટે નામો દૂર કરવા એ વિકલ્પ નથી



ધારી કોણ? તેમ છતાં મને ખાતરી છે કે તમારામાંના મોટાભાગના લોકો આ રમતને પાછલા દિવસોથી જાણે છે, અહીં ટૂંકું સંક્ષિપ્ત વર્ણન છે. રમતનો ધ્યેય: 'હા' અને 'ના' પ્રશ્નો પૂછીને તમારા વિરોધી દ્વારા પસંદ કરાયેલા કાર્ટૂન પાત્રનું નામ શોધો, જેમ કે 'વ્યક્તિ ટોપી પહેરે છે?' અથવા 'વ્યક્તિ ચશ્મા પહેરે છે'? ખેલાડીઓ પ્રતિસ્પર્ધીના પ્રતિભાવના આધારે ઉમેદવારોને દૂર કરે છે અને તેમના વિરોધીના રહસ્ય પાત્ર સાથે સંબંધિત લક્ષણો શીખે છે. પહેલો ખેલાડી જે અન્ય ખેલાડીના રહસ્ય પાત્રને બહાર કાે છે તે રમત જીતે છે.
તને સમજાઈ ગયું. વ્યક્તિએ ડેટાસેટમાંથી ફક્ત સંબંધિત લક્ષણોની byક્સેસ મેળવીને ઓળખવી જોઈએ. હકીકતમાં, અમે નિયમિતપણે અનુમાન લગાવતા આ ખ્યાલને જોતા હોઈએ છીએ જે વ્યવહારમાં લાગુ થાય છે, પરંતુ પછી વાસ્તવિક લોકોના લક્ષણો ધરાવતી પંક્તિઓ અને કumલમ સાથે ફોર્મેટ કરેલા ડેટાસેટ્સ પર કાર્યરત છે. ડેટા સાથે કામ કરતી વખતે મુખ્ય તફાવત એ છે કે લોકો સરળતાને ઓછો અંદાજ આપે છે જેના દ્વારા વાસ્તવિક વ્યક્તિઓને માત્ર થોડા લક્ષણોની byક્સેસ આપીને છૂટા કરી શકાય છે.
જેમ ગેસ હૂ ગેમ બતાવે છે, કોઈ વ્યક્તિ માત્ર થોડા લક્ષણોની byક્સેસ દ્વારા વ્યક્તિઓને ઓળખી શકે છે. તે તમારા ડેટાસેટમાંથી માત્ર 'નામો' (અથવા અન્ય સીધા ઓળખકર્તાઓ) ને કા removingી નાખવાનું એક સરળ ઉદાહરણ તરીકે સેવા આપે છે, અનામીકરણ તકનીક તરીકે નિષ્ફળ જાય છે. આ બ્લોગમાં, ડેટા અનામીકરણના સાધન તરીકે ક colલમ દૂર કરવા સાથે સંકળાયેલા ગોપનીયતા જોખમો વિશે તમને જાણ કરવા માટે અમે ચાર પ્રાયોગિક કેસો પ્રદાન કરીએ છીએ.
જોડાણના હુમલાનું જોખમ એ સૌથી મહત્વનું કારણ છે કે માત્ર નામ કા removingી નાખવું (હવે) અનામીકરણની પદ્ધતિ તરીકે કામ કરતું નથી. લિંકેજ એટેક સાથે, હુમલાખોર મૂળ માહિતીને અન્ય સુલભ ડેટા સ્રોતો સાથે જોડે છે જેથી વ્યક્તિને અનન્ય રીતે ઓળખવામાં આવે અને આ વ્યક્તિ વિશેની માહિતી (ઘણી વખત સંવેદનશીલ) શીખે.
અહીં મુખ્ય છે અન્ય ડેટા સંસાધનોની ઉપલબ્ધતા જે હાલમાં હાજર છે, અથવા ભવિષ્યમાં હાજર થઈ શકે છે. તમારા વિશે વિચારો. ફેસબુક, ઇન્સ્ટાગ્રામ અથવા લિંક્ડઇન પર તમારો કેટલો વ્યક્તિગત ડેટા મળી શકે છે જે સંભવિત રૂપે લિંકેજ હુમલા માટે દુરુપયોગ થઈ શકે?
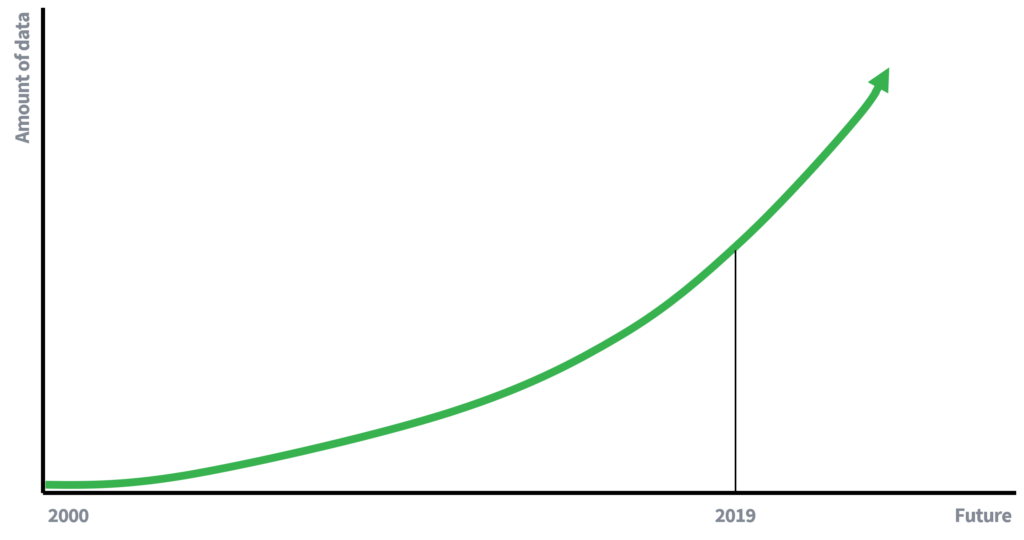
પહેલાના દિવસોમાં, ડેટાની ઉપલબ્ધતા ઘણી વધારે મર્યાદિત હતી, જે અંશત સમજાવે છે કે વ્યક્તિઓની ગોપનીયતા જાળવવા માટે નામો કા removalી નાખવા કેમ પૂરતા હતા. ઓછા ઉપલબ્ધ ડેટા એટલે ડેટા લિંક કરવાની ઓછી તકો. જો કે, અમે હવે ડેટા આધારિત અર્થતંત્રમાં (સક્રિય) સહભાગીઓ છીએ, જ્યાં ડેટાનો જથ્થો ઘાતાંકીય દરે વધી રહ્યો છે. વધુ ડેટા, અને ડેટા એકત્રિત કરવા માટેની ટેકનોલોજીમાં સુધારો કરવાથી જોડાણના હુમલાની સંભાવના વધશે. લિન્કેજ એટેકના જોખમ વિશે 10 વર્ષમાં કોઈ શું લખશે?
ચિત્ર 1
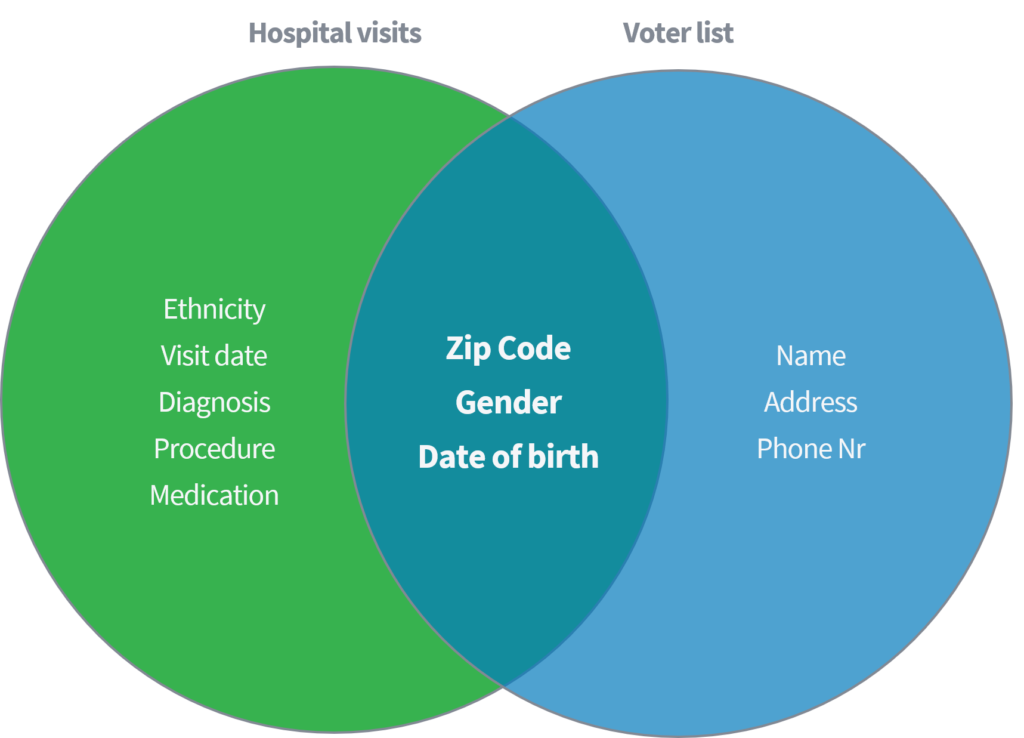
સ્વીની (2002) એ એક શૈક્ષણિક પેપરમાં દર્શાવ્યું હતું કે તે યુનાઇટેડ સ્ટેટ્સમાં સાર્વજનિક રૂપે ઉપલબ્ધ વોટિંગ રજિસ્ટ્રાર સાથે 'હોસ્પિટલ મુલાકાતો' ના જાહેર ઉપલબ્ધ ડેટા સેટને જોડવાને આધારે વ્યક્તિઓ પાસેથી સંવેદનશીલ તબીબી ડેટાને ઓળખવા અને પુન retrieveપ્રાપ્ત કરવામાં સક્ષમ હતી. બંને ડેટાસેટ્સ જ્યાં નામો અને અન્ય સીધા ઓળખકર્તાઓને કા throughી નાખીને યોગ્ય રીતે અનામી હોવાનું માનવામાં આવે છે.
ચિત્ર 2
માત્ર ત્રણ પરિમાણો (1) પિન કોડ, (2) જાતિ અને (3) જન્મ તારીખના આધારે, તેણીએ દર્શાવ્યું કે સમગ્ર યુએસ વસ્તીના 87% બંને ડેટાસેટ્સમાંથી ઉપરોક્ત વિશેષતાઓ સાથે મેળ ખાતા ફરીથી ઓળખી શકાય છે. ત્યારબાદ સ્વીનીએ 'ઝિપ કોડ'ના વિકલ્પ તરીકે' દેશ 'ધરાવવાનું કામ પુનરાવર્તન કર્યું. વધુમાં, તેણીએ દર્શાવ્યું કે સમગ્ર યુ.એસ. વસ્તીના 18% (1) વતન દેશ, (2) લિંગ અને (3) જન્મ તારીખ વિશે માહિતી ધરાવતા ડેટાસેટની havingક્સેસ મેળવીને જ ઓળખી શકાય છે. ઉપરોક્ત જાહેર સ્રોતો, જેમ કે ફેસબુક, લિંક્ડઇન અથવા ઇન્સ્ટાગ્રામ વિશે વિચારો. શું તમારો દેશ, લિંગ અને જન્મ તારીખ દેખાય છે, અથવા અન્ય વપરાશકર્તાઓ તેને કાપી શકે છે?
ચિત્ર 3
| અર્ધ-ઓળખકર્તા | યુ.એસ. વસ્તીની વિશિષ્ટ રીતે ઓળખાતી % (248 મિલિયન) |
| 5-અંકનું ઝીપ, લિંગ, જન્મ તારીખ | 87% |
| સ્થળ, લિંગ, જન્મ તારીખ | 53% |
| દેશ, લિંગ, જન્મ તારીખ | 18% |
આ ઉદાહરણ દર્શાવે છે કે મોટે ભાગે અનામી ડેટામાં વ્યક્તિઓને ડિ-અનામી રાખવું નોંધપાત્ર રીતે સરળ હોઈ શકે છે. પ્રથમ, આ અભ્યાસ જોખમની વિશાળ તીવ્રતા સૂચવે છે, જેમ કે 87% યુ.એસ. વસ્તીનો ઉપયોગ કરીને સરળતાથી ઓળખી શકાય છે થોડા લક્ષણો. બીજું, આ અભ્યાસમાં ખુલ્લી તબીબી માહિતી અત્યંત સંવેદનશીલ હતી. હોસ્પિટલની મુલાકાત ડેટાસેટમાંથી ખુલ્લા વ્યક્તિઓના ડેટાના ઉદાહરણોમાં વંશીયતા, નિદાન અને દવાઓનો સમાવેશ થાય છે. ગુણો કે જે કોઈ વ્યક્તિ ગુપ્ત રાખી શકે છે, ઉદાહરણ તરીકે, વીમા કંપનીઓ તરફથી.
માત્ર સીધા ઓળખકર્તાઓને દૂર કરવાનું બીજું જોખમ, જેમ કે નામો, જ્યારે જાણકાર વ્યક્તિઓ પાસે ડેટાસેટમાં વિશિષ્ટ વ્યક્તિઓના લક્ષણો અથવા વર્તન વિશે શ્રેષ્ઠ જ્ knowledgeાન અથવા માહિતી હોય ત્યારે ભી થાય છે.. તેમના જ્ knowledgeાનના આધારે, હુમલાખોર પછી ચોક્કસ ડેટા રેકોર્ડ્સને વાસ્તવિક લોકો સાથે લિંક કરી શકશે.
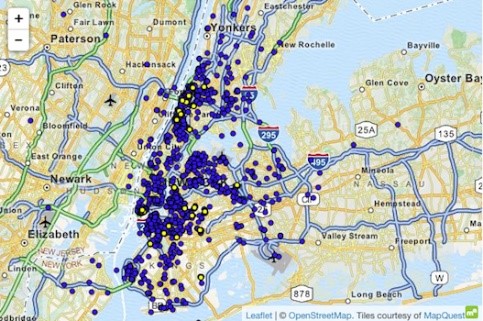
શ્રેષ્ઠ જ્ knowledgeાનનો ઉપયોગ કરીને ડેટાસેટ પર હુમલાનું ઉદાહરણ ન્યુ યોર્ક ટેક્સી કેસ છે, જ્યાં અટોકર (2014) ચોક્કસ વ્યક્તિઓને છૂટા કરવામાં સક્ષમ હતા. કાર્યરત ડેટાસેટમાં ન્યૂ યોર્કની તમામ ટેક્સી મુસાફરીઓ શામેલ છે, જે પ્રારંભિક કોઓર્ડિનેટ્સ, અંતિમ કોઓર્ડિનેટ્સ, રાઇડની કિંમત અને ટીપ જેવા મૂળભૂત લક્ષણોથી સમૃદ્ધ છે.
એક જાણકાર વ્યક્તિ જે ન્યુ યોર્ક જાણે છે તે પુખ્ત ક્લબ 'હસ્ટલર' માટે ટેક્સીની સફર કરવામાં સક્ષમ હતો. 'એન્ડ લોકેશન' ફિલ્ટર કરીને, તેણે શરૂઆતના ચોક્કસ સરનામાં કા ded્યા અને ત્યાંથી વારંવાર આવતા મુલાકાતીઓની ઓળખ કરી. તેવી જ રીતે, જ્યારે કોઈ વ્યક્તિનું ઘરનું સરનામું જાણીતું હોય ત્યારે કોઈ ટેક્સીની સવારી કાી શકે છે. ઘણા સેલિબ્રિટી મૂવી સ્ટાર્સનો સમય અને સ્થાન ગપસપ સાઇટ્સ પર શોધવામાં આવ્યું હતું. આ માહિતીને એનવાયસી ટેક્સી ડેટા સાથે લિંક કર્યા પછી, તેમની ટેક્સી સવારી, તેઓએ ચૂકવેલી રકમ અને તેઓએ ટિપ આપી હતી કે કેમ તે મેળવવાનું સરળ હતું.
ચિત્ર 4
ડ્રોપ-ઓફ કોઓર્ડિનેટ્સ હસ્ટલર
બ્રેડલી કૂપર
જેસિકા આલ્બા
દલીલની સામાન્ય લાઇન છે 'આ ડેટા નકામો છે' અથવા 'આ ડેટા સાથે કોઈ પણ કંઈ કરી શકતું નથી'. આ ઘણી વખત ગેરસમજ છે. સૌથી નિર્દોષ ડેટા પણ અનન્ય 'ફિંગરપ્રિન્ટ' બનાવી શકે છે અને તેનો ઉપયોગ વ્યક્તિઓને ફરીથી ઓળખવા માટે કરી શકાય છે. તે ડેટા પોતે નકામું છે એવું માનવાથી ઉદ્ભવેલું જોખમ છે, જ્યારે તે નથી.
ડેટા, AI અને અન્ય સાધનો અને અલ્ગોરિધમ્સના વધારા સાથે ઓળખનું જોખમ વધશે જે ડેટામાં જટિલ સંબંધોને ઉજાગર કરવામાં સક્ષમ બનાવે છે. પરિણામે, જો તમારો ડેટાસેટ હમણાં ખુલ્લો કરી શકાતો નથી, અને આજે અનધિકૃત વ્યક્તિઓ માટે સંભવત use નકામું છે, તો તે કાલે ન પણ હોઈ શકે.
એક શ્રેષ્ઠ ઉદાહરણ એ છે કે જ્યાં નેટફ્લિક્સ તેના આર એન્ડ ડી વિભાગને તેમની ફિલ્મ ભલામણ પ્રણાલીમાં સુધારો કરવા માટે ખુલ્લી નેટફ્લિક્સ સ્પર્ધા રજૂ કરીને ક્રાઉડસોર્સ કરવાનો ઇરાદો ધરાવે છે. 'જે ફિલ્મો માટે યુઝર રેટિંગની આગાહી કરવા માટે સહયોગી ફિલ્ટરિંગ એલ્ગોરિધમમાં સુધારો કરે છે તે US $ 1,000,000 નું ઇનામ જીતે છે'. ભીડને ટેકો આપવા માટે, નેટફ્લિક્સે એક ડેટાસેટ પ્રકાશિત કર્યો છે જેમાં ફક્ત નીચેના મૂળભૂત લક્ષણો છે: યુઝર આઈડી, મૂવી, ગ્રેડની તારીખ અને ગ્રેડ (તેથી વપરાશકર્તા અથવા ફિલ્મ વિશે વધુ માહિતી નથી).
ચિત્ર 5
| યુઝરઆઈડી | ફિલ્મ | ગ્રેડની તારીખ | ગ્રેડ |
| 123456789 | અશક્ય મિશન | 10-12-2008 | 4 |
અલગતામાં, ડેટા નિરર્થક દેખાયો. પ્રશ્ન પૂછતી વખતે 'શું ડેટાસેટમાં કોઈ ગ્રાહક માહિતી છે જે ખાનગી રાખવી જોઈએ?', જવાબ હતો:
'ના, ગ્રાહકની ઓળખ કરતી તમામ માહિતી દૂર કરવામાં આવી છે; રેટિંગ્સ અને તારીખો બાકી છે. આ અમારી ગોપનીયતા નીતિને અનુસરે છે ... '
જો કે, ઓસ્ટિન ખાતે ટેક્સાસ યુનિવર્સિટીના નારાયણન (2008) અન્યથા સાબિત થયા. ગ્રેડ, ગ્રેડની તારીખ અને વ્યક્તિની ફિલ્મનું સંયોજન એક અનન્ય મૂવી-ફિંગરપ્રિન્ટ બનાવે છે. તમારા પોતાના નેટફ્લિક્સ વર્તન વિશે વિચારો. તમારા મતે કેટલા લોકોએ સમાન ફિલ્મોનો સેટ જોયો છે? એક જ સમયે કેટલી ફિલ્મોનો સેટ જોયો?
મુખ્ય પ્રશ્ન, આ ફિંગરપ્રિન્ટને કેવી રીતે મેચ કરવી? તે એકદમ સરળ હતું. જાણીતી ફિલ્મ-રેટિંગ વેબસાઇટ IMDb (ઇન્ટરનેટ મૂવી ડેટાબેઝ) ની માહિતીના આધારે, સમાન ફિંગરપ્રિન્ટની રચના થઈ શકે છે. પરિણામે, વ્યક્તિઓને ફરીથી ઓળખી શકાય છે.
જ્યારે મૂવી જોવાની વર્તણૂક સંવેદનશીલ માહિતી તરીકે માનવામાં ન આવે, તમારા પોતાના વર્તન વિશે વિચારો-જો તે જાહેરમાં જાય તો તમને વાંધો છે? નારાયણને તેના પેપરમાં આપેલા ઉદાહરણો રાજકીય પસંદગીઓ ('ઈસુ ઓફ નાઝારેથ' અને 'ધ ગોસ્પેલ ઓફ જ્હોન' પર રેટિંગ્સ) અને જાતીય પસંદગીઓ ('બેન્ટ' અને 'ક્વીર એઝ ફોક') છે જે સરળતાથી નિસ્યંદિત થઈ શકે છે.
જીડીપીઆર સુપર-રોમાંચક ન હોઈ શકે, ન તો બ્લોગ વિષયોમાં ચાંદીની બુલેટ. તેમ છતાં, વ્યક્તિગત ડેટાની પ્રક્રિયા કરતી વખતે સીધી વ્યાખ્યાઓ મેળવવામાં મદદરૂપ થાય છે. આ બ્લોગ ડેટાને અનામી રાખવા અને તમને ડેટા પ્રોસેસર તરીકે શિક્ષિત કરવાના માર્ગ તરીકે કumલમ દૂર કરવાની સામાન્ય ગેરસમજ વિશે હોવાથી, ચાલો જીડીપીઆર અનુસાર અનામીકરણની વ્યાખ્યા અન્વેષણ કરીએ.
જીડીપીઆરના 26 પાઠ અનુસાર, અનામી માહિતીને આ રીતે વ્યાખ્યાયિત કરવામાં આવી છે:
'જે માહિતી ઓળખી શકાય તેવા અથવા ઓળખી શકાય તેવા કુદરતી વ્યક્તિ અથવા વ્યક્તિગત ડેટાને અનામી રીતે રજૂ કરવામાં આવી હોય તે રીતે સંબંધિત નથી કે માહિતીનો વિષય નથી અથવા હવે ઓળખી શકાતો નથી.'
કુદરતી વ્યક્તિ સાથે સંબંધિત વ્યક્તિગત ડેટા પર પ્રક્રિયા કરતી હોવાથી, વ્યાખ્યાનો માત્ર ભાગ 2 સંબંધિત છે. વ્યાખ્યાનું પાલન કરવા માટે, કોઈએ સુનિશ્ચિત કરવું પડશે કે ડેટા વિષય (વ્યક્તિગત) હવે ઓળખી શકાતો નથી અથવા નથી. આ બ્લોગમાં દર્શાવ્યા મુજબ, જો કે, કેટલાક લક્ષણોના આધારે વ્યક્તિઓને ઓળખવા માટે તે નોંધપાત્ર રીતે સરળ છે. તેથી, ડેટાસેટમાંથી નામો દૂર કરવાથી અનામીકરણની જીડીપીઆર વ્યાખ્યાનું પાલન થતું નથી.
અમે સામાન્ય રીતે માનવામાં આવતા એક અને, કમનસીબે, હજુ પણ ડેટા અનામીકરણના વારંવાર લાગુ પડતા અભિગમને પડકાર્યો: નામો દૂર કરવા. અનુમાન કોણ રમતમાં અને તેના વિશે ચાર અન્ય ઉદાહરણો:
તે બતાવવામાં આવ્યું હતું કે નામ કા removingી નાખવું અનામીકરણ તરીકે નિષ્ફળ જાય છે. જો કે ઉદાહરણો આઘાતજનક કિસ્સાઓ છે, દરેક ફરીથી ઓળખની સરળતા દર્શાવે છે અને વ્યક્તિઓની ગોપનીયતા પર સંભવિત નકારાત્મક અસર.
નિષ્કર્ષમાં, તમારા ડેટાસેટમાંથી નામો કા removalી નાખવાથી અનામી ડેટા મળતો નથી. તેથી, અમે બંને શબ્દો એકબીજાના બદલે વાપરવાનું ટાળીએ છીએ. હું નિષ્ઠાપૂર્વક આશા રાખું છું કે તમે અનામીકરણ માટે આ અભિગમ લાગુ કરશો નહીં. અને, જો તમે હજી પણ કરો છો, તો ખાતરી કરો કે તમે અને તમારી ટીમ ગોપનીયતાના જોખમોને સંપૂર્ણ રીતે સમજો છો, અને અસરગ્રસ્ત વ્યક્તિઓ વતી તે જોખમો સ્વીકારવાની મંજૂરી છે.
સિન્થોનો સંપર્ક કરો અને અમારા એક નિષ્ણાત કૃત્રિમ ડેટાના મૂલ્યનું અન્વેષણ કરવા માટે પ્રકાશની ઝડપે તમારી સાથે સંપર્ક કરશે!