As mellores ferramentas de anonimización de datos para o cumprimento da protección da privacidade
As organizacións usan ferramentas de anonimización de datos para eliminar información de identificación persoal dos seus conxuntos de datos. O incumprimento pode levar a fortes multas dos organismos reguladores e infraccións de datos. Sen datos anónimos, non pode utilizar nin compartir os conxuntos de datos ao máximo.
Moitos ferramentas de anonimización non pode garantir o cumprimento total. Os métodos de xeración pasada poden deixar a información persoal vulnerable á desidentificación por parte de actores maliciosos. Algunhas métodos estatísticos de anonimización reducir a calidade do conxunto de datos ata un punto no que non é fiable analítica de datos.
Nós, da Sinto presentarache os métodos de anonimización e as principais diferenzas entre as ferramentas de xeración pasada e próxima. Informarémosche das mellores ferramentas de anonimización de datos e suxerémosche as consideracións fundamentais para escollelas.
Índice analítico
- Que son datos sintéticos
- Como funciona
- Por que o utilizan as organizacións
- Como comezar

Que son as ferramentas de anonimización de datos?
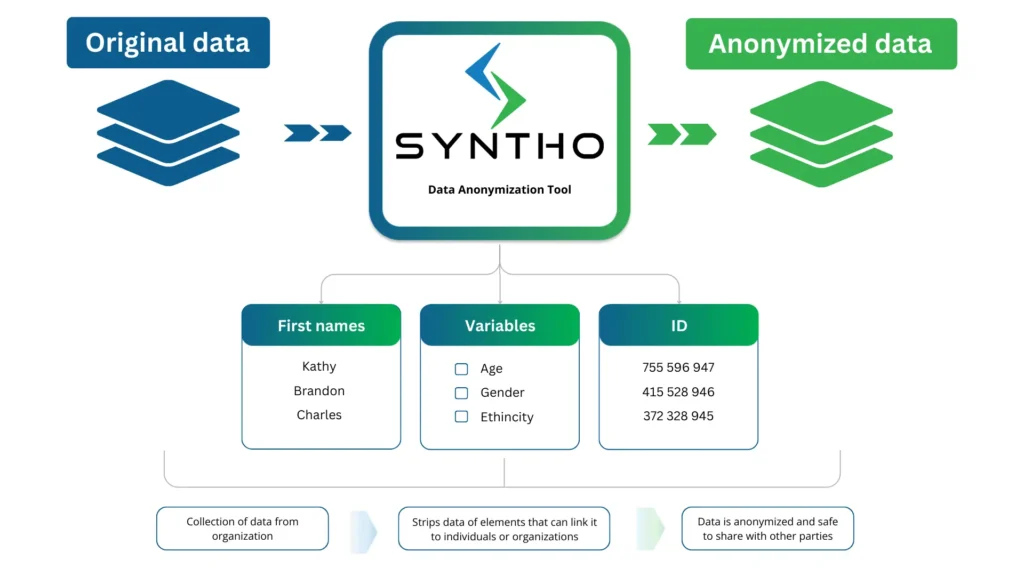
Anonimización de datos é a técnica de eliminar ou alterar información confidencial en conxuntos de datos. As organizacións non poden acceder, compartir e utilizar libremente os datos dispoñibles que se poden rastrexar directa ou indirectamente aos individuos.
- Regulamento xeral de protección de datos (GDPR). A lexislación da UE protexe a privacidade dos datos persoais, esixindo o consentimento para o procesamento de datos e concedendo aos individuos dereitos de acceso aos datos. O Reino Unido ten unha lei similar chamada UK-GDPR.
- Lei de privacidade do consumidor de California (CCPA). Lei de privacidade de California céntrase nos dereitos dos consumidores respecto compartición de datos.
- Lei de portabilidade e rendición de contas dos seguros de saúde (HIPAA). A regra de privacidade establece estándares para protexer a información sanitaria do paciente.
Como funcionan as ferramentas de anonimización de datos?
As ferramentas de anonimización de datos analizan conxuntos de datos en busca de información confidencial e substitúenos por datos artificiais. O software atopa eses datos en táboas e columnas, ficheiros de texto e documentos dixitalizados.
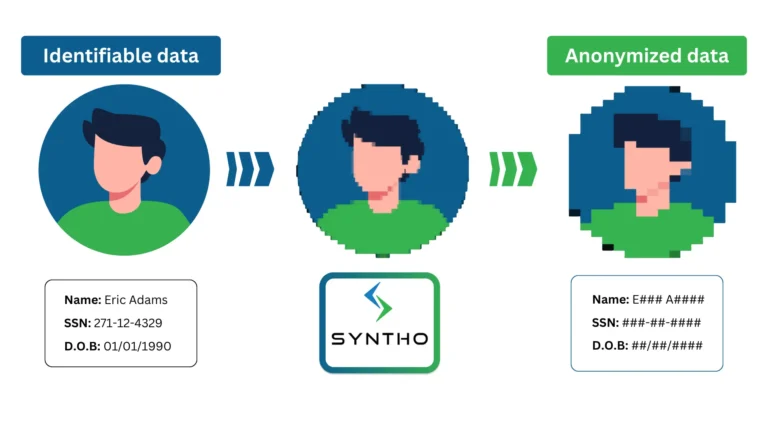
Este proceso elimina os datos dos elementos que poden vinculalos a persoas ou organizacións. Os tipos de datos ocultados por estas ferramentas inclúen:
- Información de identificación persoal (PII): Nomes, números de identificación, datas de nacemento, detalles de facturación, números de teléfono e enderezos de correo electrónico.
- Información sanitaria protexida (PHI): Abarca os rexistros médicos, os detalles do seguro de saúde e os datos persoais de saúde.
- Información financeira: Números de tarxeta de crédito, datos de conta bancaria, datos de investimento e outros que se poden vincular a entidades corporativas.
Por exemplo, as organizacións sanitarias anonimizan os enderezos dos pacientes e os datos de contacto para garantir o cumprimento da HIPAA para a investigación do cancro. Unha empresa financeira ocultaba as datas e localizacións das transaccións nos seus conxuntos de datos para cumprir coas leis do GDPR.
Aínda que o concepto é o mesmo, existen varias técnicas distintas para datos anónimos.
Técnicas de anonimización de datos
A anonimización ocorre de moitas maneiras e non todos os métodos son igualmente fiables para o seu cumprimento e utilidade. Esta sección describe a diferenza entre os distintos tipos de métodos.
Pseudonimización
A pseudonimización é un proceso reversible de desidentificación no que os identificadores persoais son substituídos por pseudónimos. Mantén un mapeo entre os datos orixinais e os alterados, coa táboa de mapeo almacenada por separado.
A desvantaxe da pseudónimo é que é reversible. Con información adicional, os actores maliciosos poden rastrexala ata o individuo. Segundo as regras do GDPR, os datos pseudónimos non se consideran datos anónimos. Segue suxeita á normativa de protección de datos.
Enmascaramento de datos
O método de enmascaramento de datos crea unha versión estruturalmente similar pero falsa dos seus datos para protexer a información confidencial. Esta técnica substitúe os datos reais por caracteres alterados, mantendo o mesmo formato para o seu uso normal. En teoría, isto axuda a manter a funcionalidade operativa dos conxuntos de datos.
Na práctica, datos de enmascaramento moitas veces reduce o utilidade de datos. Pode non conservar o datos orixinaisdistribución ou características de , o que o fai menos útil para a análise. Outro reto é decidir que enmascarar. Se se fai incorrectamente, os datos enmascarados aínda se poden volver identificar.
Xeneralización (agregación)
A xeneralización anonimiza os datos facéndoos menos detallados. Agrupa datos similares e diminúe a súa calidade, polo que é máis difícil distinguir os datos individuais. Este método a miúdo implica métodos de resumo de datos como a media ou a totalización para protexer os puntos de datos individuais.
A sobrexeneralización pode facer que os datos sexan case inútiles, mentres que a subxeneralización pode non ofrecer suficiente privacidade. Tamén existe o risco de revelación residual, xa que os conxuntos de datos agregados aínda poden proporcionar suficientes detalles de identificación cando se combinan con outros. fontes de datos.
Perturbación
A perturbación modifica os conxuntos de datos orixinais redondeando os valores e engadindo ruído aleatorio. Os puntos de datos cámbianse sutilmente, interrompendo o seu estado orixinal mentres se manteñen os patróns xerais de datos.
A desvantaxe da perturbación é que os datos non están totalmente anónimos. Se os cambios non son suficientes, existe o risco de que se poidan volver identificar as características orixinais.
Intercambio de datos
O intercambio é unha técnica na que se reorganizan os valores dos atributos dun conxunto de datos. Este método é particularmente sinxelo de implementar. Os conxuntos de datos finais non se corresponden cos rexistros orixinais e non se poden rastrexar directamente ás súas fontes orixinais.
Indirectamente, porén, os conxuntos de datos seguen sendo reversibles. Os datos intercambiados son vulnerables á divulgación incluso con fontes secundarias limitadas. Ademais, é difícil manter a integridade semántica dalgúns datos conmutados. Por exemplo, ao substituír os nomes nunha base de datos, o sistema pode non distinguir entre nomes masculinos e femininos.
Tokenización
A tokenización substitúe os elementos de datos sensibles por tokens, equivalentes non sensibles sen valores explotables. A información tokenizada adoita ser unha cadea aleatoria de números e caracteres. Esta técnica úsase a miúdo para salvagardar a información financeira mantendo as súas propiedades funcionais.
Algúns programas fan que sexa máis difícil xestionar e escalar as bóvedas de tokens. Este sistema tamén introduce un risco de seguridade: os datos sensibles poden estar en perigo se un atacante atravesa a bóveda de cifrado.
Aleatorización
A aleatorización altera os valores con datos aleatorios e simulados. É un enfoque sinxelo que axuda a preservar a confidencialidade das entradas de datos individuais.
Esta técnica non funciona se queres manter a distribución estatística exacta. Está garantido que compromete os datos utilizados para conxuntos de datos complexos, como datos xeoespaciais ou temporais. Os métodos de aleatorización inadecuados ou aplicados de forma inadecuada tampouco poden garantir a protección da privacidade.
Redacción de datos
A redacción de datos é o proceso de eliminar por completo a información dos conxuntos de datos: borrar, borrar ou borrar texto e imaxes. Isto impide o acceso a información sensible datos de produción e é unha práctica habitual nos documentos legais e oficiais. É igual de obvio que fai que os datos non sexan aptos para realizar análises estatísticas precisas, aprendizaxe de modelos e investigación clínica.
Como é evidente, estas técnicas teñen fallos que deixan lagoas que os actores malintencionados poden abusar. A miúdo eliminan elementos esenciais dos conxuntos de datos, o que limita a súa usabilidade. Este non é o caso das técnicas de última xeración.
Ferramentas de anonimización de última xeración
O software moderno de anonimización emprega técnicas sofisticadas para negar o risco de reidentificación. Ofrecen formas de cumprir todas as normas de privacidade mantendo a calidade estrutural dos datos.
Xeración de datos sintéticos
A xeración de datos sintéticos ofrece un enfoque máis intelixente para anonimizar os datos mantendo a súa utilidade. Esta técnica usa algoritmos para crear novos conxuntos de datos que reflicten a estrutura e as propiedades dos datos reais.
Os datos sintéticos substitúen a PII e a PHI por datos simulados que non se poden rastrexar ata persoas. Isto garante o cumprimento das leis de privacidade de datos, como GDPR e HIPAA. Ao adoptar ferramentas de xeración de datos sintéticos, as organizacións garanten a privacidade dos datos, mitigan os riscos de violacións de datos e aceleran o desenvolvemento de aplicacións baseadas en datos.
Cifrado homomórfico
Cifrado homomórfico (tradúcese como "a mesma estrutura") transforma datos en texto cifrado. Os conxuntos de datos cifrados conservan a mesma estrutura que os datos orixinais, o que resulta nunha excelente precisión para as probas.
Este método permite realizar cálculos complexos directamente sobre o datos cifrados sen necesidade de descifralo primeiro. As organizacións poden almacenar de forma segura ficheiros cifrados na nube pública e subcontratar o procesamento de datos a terceiros sen comprometer a seguridade. Estes datos tamén son compatibles, xa que as normas de privacidade non se aplican á información cifrada.
Non obstante, os algoritmos complexos requiren experiencia para a súa correcta implementación. Ademais, o cifrado homomórfico é máis lento que as operacións con datos sen cifrar. Quizais non sexa a solución óptima para os equipos de DevOps e Garantía de Calidade (QA), que requiren un acceso rápido aos datos para realizar probas.
Cálculo multipartito seguro
A computación multipartida segura (SMPC) é un método criptográfico para xerar conxuntos de datos cun esforzo conxunto de varios membros. Cada parte cifra a súa entrada, realiza cálculos e recibe datos procesados. Deste xeito, cada membro obtén o resultado que necesita mantendo en segredo os seus propios datos.
Este método require que varias partes descifran os conxuntos de datos producidos, o que o fai máis confidencial. Non obstante, o SMPC require un tempo importante para xerar resultados.
| Técnicas de anonimización de datos de xeración anterior | Ferramentas de anonimización de última xeración | ||||
|---|---|---|---|---|---|
| Pseudonimización | Substitúe os identificadores persoais por pseudónimos mantendo unha táboa de mapeo separada. | - Xestión de datos de RRHH - Interaccións de atención ao cliente - Enquisas de investigación | Xeración de datos sintéticos | Usa un algoritmo para crear novos conxuntos de datos que reflicten a estrutura dos datos reais ao tempo que garante a privacidade e o cumprimento. | - Desenvolvemento de aplicacións baseada en datos - Investigación clínica - Modelado avanzado - Marketing de clientes |
| Enmascaramento de datos | Modifica os datos reais con caracteres falsos, mantendo o mesmo formato. | - Informes financeiros - Contornas de formación de usuarios | Cifrado homomórfico | Transforma os datos en texto cifrado mantendo a estrutura orixinal, permitindo o cálculo en datos cifrados sen descifrar. | - Tratamento seguro de datos - Outsourcing de computación de datos - Análise avanzada de datos |
| Xeneralización (agregación) | Reduce o detalle dos datos, agrupando datos similares. | - Estudos demográficos - Estudos de mercado | Cálculo multipartito seguro | Método criptográfico onde varias partes cifran a súa entrada, realizan cálculos e conseguen resultados conxuntos. | - Análise colaborativa de datos - Agrupación de datos confidenciais |
| Perturbación | Modifica os conxuntos de datos redondeando os valores e engadindo ruído aleatorio. | - Análise de datos económicos - Investigación de patróns de tráfico - Análise de datos de vendas | |||
| Intercambio de datos | Reorganiza os valores dos atributos do conxunto de datos para evitar a rastrexabilidade directa. | - Estudos de transporte - Análise de datos educativos | |||
| Tokenización | Substitúe os datos confidenciais por tokens non confidenciais. | - Tramitación de pagamentos - Investigación da relación con clientes | |||
| Aleatorización | Engade datos aleatorios ou simulados para alterar os valores. | - Análise de datos xeoespaciais - Estudos do comportamento | |||
| Redacción de datos | Elimina información dos conxuntos de datos, | - Tramitación de documentos legais - Xestión de rexistros | |||
Táboa 1. A comparación entre as técnicas de anonimización anteriores e de próxima xeración
Desidentificación intelixente de datos como un novo enfoque para a anonimización de datos
Desidentificación intelixente anonimiza os datos mediante a IA xerada datos simulados sintéticos. As plataformas con funcións transforman información confidencial en datos compatibles e non identificables dos seguintes xeitos:
- O software de desidentificación analiza os conxuntos de datos existentes e identifica a PII e a PHI.
- As organizacións poden seleccionar que datos confidenciais substituír por información artificial.
- A ferramenta produce novos conxuntos de datos con datos compatibles.
Esta tecnoloxía é útil cando as organizacións necesitan colaborar e intercambiar datos valiosos de forma segura. Tamén é útil cando hai que facer que os datos sexan compatibles en varios bases de datos relacionales.
A desidentificación intelixente mantén intactas as relacións dentro dos datos mediante un mapeo coherente. As empresas poden usar os datos xerados para realizar análises empresariais en profundidade, adestramento de aprendizaxe automática e probas clínicas.
Con tantos métodos, necesitas un xeito de determinar se a ferramenta de anonimización é adecuada para ti.
Como elixir a ferramenta correcta de anonimización de datos
- Escalabilidade operativa. Escolla unha ferramenta capaz de aumentar e reducir a escala de acordo coas súas demandas operativas. Tómese o tempo para probar a eficiencia operativa baixo unha maior carga de traballo.
- Integración. As ferramentas de anonimización de datos deberían integrarse sen problemas cos seus sistemas e software analítico existentes, así como coa canalización de integración continua e implantación continua (CI/CD). A compatibilidade coas túas plataformas de almacenamento, cifrado e procesamento de datos é fundamental para realizar operacións sen problemas.
- Mapeo de datos consistente. Asegúrate de que os preservadores de datos anónimos teñan integridade e precisión estatística adecuadas ás túas necesidades. As técnicas de anonimización da xeración anterior borran elementos valiosos dos conxuntos de datos. As ferramentas modernas, con todo, manteñen a integridade referencial, facendo que os datos sexan o suficientemente precisos para casos de uso avanzados.
- Mecanismos de seguridade. Prioriza as ferramentas que protexen os conxuntos de datos reais e os resultados anónimos contra ameazas internas e externas. O software debe implantarse nunha infraestrutura de cliente segura, controis de acceso baseados en roles e API de autenticación de dous factores.
- Infraestrutura conforme. Asegúrese de que a ferramenta almacene os conxuntos de datos nun almacenamento seguro que cumpra coas normativas GDPR, HIPAA e CCPA. Ademais, debería admitir ferramentas de copia de seguridade e recuperación de datos para evitar a posibilidade de tempo de inactividade debido a erros inesperados.
- Modelo de pago. Considere os custos inmediatos e a longo prazo para comprender se a ferramenta se aliña co seu orzamento. Algunhas ferramentas están deseñadas para grandes empresas e medianas empresas, mentres que outras teñen modelos flexibles e plans baseados no uso.
- Soporte técnico. Avaliar a calidade e dispoñibilidade do soporte técnico e ao cliente. Un provedor pode axudarche a integrar as ferramentas de anonimización de datos, adestrar ao persoal e resolver problemas técnicos.
As 7 mellores ferramentas de anonimización de datos
Agora que sabes que buscar, imos explorar cales cremos que son as ferramentas máis fiables enmascarar información sensible.
1. Sinto
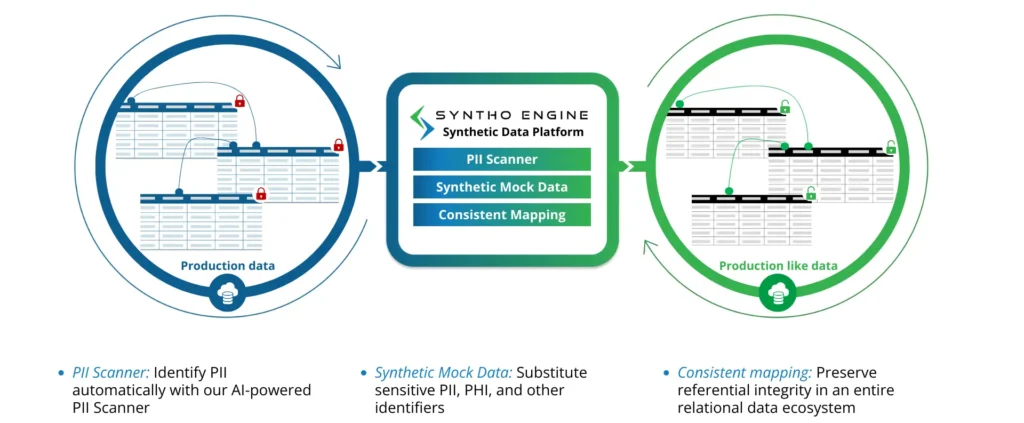
Syntho está alimentado por un software de xeración de datos sintéticos que ofrece oportunidades de desidentificación intelixente. A creación de datos baseada en regras da plataforma aporta versatilidade, o que permite ás organizacións elaborar datos segundo as súas necesidades.
Un escáner alimentado por intelixencia artificial identifica toda a PII e PHI en conxuntos de datos, sistemas e plataformas. As organizacións poden escoller que datos eliminar ou simular para cumprir cos estándares regulamentarios. Mentres tanto, a función de subconfiguración axuda a facer conxuntos de datos máis pequenos para probar, reducindo a carga dos recursos de almacenamento e procesamento.
A plataforma é útil en varios sectores, incluíndo a saúde, a xestión da cadea de subministración e as finanzas. As organizacións usan a plataforma Syntho para crear escenarios que non sexan de produción e desenvolver escenarios de proba personalizados.
Podes aprender máis sobre as capacidades de Syntho por programando unha demostración.
2. K2view
3. Broadcom
4. Principalmente AI
5. ARX
6. Amnesia
7. Tónica.ai
Casos de uso das ferramentas de anonimización de datos
As empresas de finanzas, saúde, publicidade e servizos públicos usan ferramentas de anonimización para cumprir coas leis de privacidade de datos. Os conxuntos de datos desidentificados úsanse para varios escenarios.
Desenvolvemento e probas de software
As ferramentas de anonimización permiten que os enxeñeiros de software, os probadores e os profesionais do control de calidade traballen con conxuntos de datos realistas sen expor PII. As ferramentas avanzadas axudan aos equipos a autoabastecer os datos necesarios que imiten as condicións de proba do mundo real sen problemas de cumprimento. Isto axuda ás organizacións a mellorar a súa eficiencia de desenvolvemento de software e a súa calidade.
Casos reais:
- O software de Syntho creou datos de proba anónimos que preserva os valores estatísticos dos datos reais, permitindo aos desenvolvedores probar diferentes escenarios a maior ritmo.
- O almacén BigQuery de Google ofrece unha función de anonimización do conxunto de datos para axudar ás organizacións a compartir datos con provedores sen romper as normas de privacidade.
Investigación clínica
Os investigadores médicos, especialmente na industria farmacéutica, anonimizan os datos para preservar a privacidade dos seus estudos. Os investigadores poden analizar as tendencias, a demografía dos pacientes e os resultados do tratamento, contribuíndo aos avances médicos sen arriscar a confidencialidade do paciente.
Casos reais:
- Erasmus Medical Center usa as ferramentas anónimas de xeración de IA de Syntho xerar e compartir conxuntos de datos de alta calidade para a investigación médica.
Prevención de fraudes
Na prevención da fraude, as ferramentas de anonimización permiten a análise segura dos datos transaccionais, identificando patróns maliciosos. As ferramentas de desidentificación tamén permiten adestrar o software de IA en datos reais para mellorar a detección de fraudes e riscos.
Casos reais:
- Brighterion adestrouse sobre os datos de transaccións anónimos de Mastercard para enriquecer o seu modelo de IA, mellorando as taxas de detección de fraudes ao tempo que reducen os falsos positivos.
Marketing de clientes
As técnicas de anonimización de datos axudan a avaliar as preferencias dos clientes. As organizacións comparten conxuntos de datos de comportamento desidentificados cos seus socios comerciais para mellorar as estratexias de mercadotecnia dirixidas e personalizar a experiencia do usuario.
Casos reais:
- A plataforma de anonimización de datos de Syntho predixo con precisión a perda de clientes mediante datos sintéticos xerado a partir dun conxunto de datos de máis de 56,000 clientes con 128 columnas.
Publicación de datos públicos
As axencias e os organismos gobernamentais usan a anonimización de datos para compartir e procesar información pública de forma transparente para diversas iniciativas públicas. Inclúen previsións de delincuencia baseadas en datos de redes sociais e antecedentes penais, planificación urbana baseada en datos demográficos e rutas de transporte público ou necesidades sanitarias entre rexións en función dos patróns de enfermidades.
Casos reais:
- A Universidade de Indiana utilizou datos anónimos de teléfonos intelixentes duns 10,000 policías en 21 cidades dos Estados Unidos para revelar discrepancias das patrullas de barrio en función de factores socioeconómicos.
Estes son só algúns exemplos que escollemos. O software de anonimización úsase en todas as industrias como un medio para sacar o máximo proveito dos datos dispoñibles.
Escolle as mellores ferramentas de anonimización de datos
Todas as empresas usan software de anonimización de bases de datos para cumprir coa normativa de privacidade. Cando se elimina a información persoal, os conxuntos de datos pódense utilizar e compartir sen riscos de multas ou procesos burocráticos.
Os métodos de anonimización máis antigos como o intercambio de datos, o enmascaramento e a redacción non son o suficientemente seguros. Desidentificación de datos segue sendo unha posibilidade, o que o fai incumprible ou arriscado. Ademais, pasado-xen software anonimizador moitas veces degrada a calidade dos datos, especialmente en grandes conxuntos de datos. As organizacións non poden confiar en tales datos para realizar análises avanzadas.
Deberías optar polo mellor anonimización de datos software. Moitas empresas elixen a plataforma Syntho polas súas principais capacidades de identificación de PII, enmascaramento e xeración de datos sintéticos.
Estás interesado en saber máis? Non dubides en explorar a documentación do noso produto ou póñase en contacto connosco para unha demostración.
Sobre o autor

Xerente de Desenvolvemento de Negocios
Uliana Krainska, un Executivo de Desenvolvemento de Negocios en Syntho, con experiencia internacional no desenvolvemento de software e na industria SaaS, ten un máster en Negocios Dixitais e Innovación, pola VU Amsterdam.
Durante os últimos cinco anos, Uliana demostrou un compromiso firme para explorar as capacidades de IA e proporcionar consultoría estratéxica de negocios para a implementación de proxectos de IA.

Garda a túa guía de datos sintéticos agora!
- Que son os datos sintéticos?
- Por que o utilizan as organizacións?
- Casos de clientes de datos sintéticos de valor engadido
- Como comezar
