Ried ris wa? 5 foarbylden wêrom it fuortsmiten fan nammen is gjin opsje



Ried ris wa? Hoewol ik d'r wis fan bin dat de measten fan jo dit spultsje fan 'e tiid kenne, hjir in koarte oersjoch. It doel fan it spul: ûntdek de namme fan it stripfiguer selekteare troch jo tsjinstanner troch 'ja' en 'nee' fragen te stellen, lykas 'hat de persoan in hoed op?' of 'draacht de persoan in bril'? Spilers eliminearje kandidaten op basis fan 'e reaksje fan' e tsjinstanner en leare attributen dy't relatearje oan it mysterieuze karakter fan har tsjinstanner. De earste spiler dy't it mystearje -karakter fan 'e oare spiler útfynt wint it spul.
Jo hawwe it. Men moat it yndividu identifisearje út in dataset troch allinich tagong te hawwen ta de oerienkommende attributen. Yn feite sjogge wy dit konsept regelmjittich fan Guess Who tapast yn 'e praktyk, mar dan brûkt op datasets opmakke mei rigen en kolommen mei attributen fan echte minsken. It wichtichste ferskil by it wurkjen mei gegevens is dat minsken de neiging hawwe te ûnderskatte it gemak wêrtroch echte yndividuen kinne wurde ûntmaskerd troch tagong te hawwen ta mar in pear attributen.
Lykas it spultsje Guess Who yllustreart, kin immen yndividuen identifisearje troch tagong te hawwen ta mar in pear attributen. It tsjinnet as in ienfâldich foarbyld wêrom it fuortheljen fan allinich 'nammen' (of oare direkte identifisearders) út jo dataset mislearret as in anonymisaasjetechnyk. Yn dit blog leverje wy fjouwer praktyske gefallen om jo te ynformearjen oer de privacyrisiko's ferbûn mei it ferwiderjen fan kolommen as middel foar anonymisaasje fan gegevens.
It risiko fan in keppelingoanfallen is de wichtichste reden wêrom allinich it ferwiderjen fan nammen net (mear) wurket as in metoade foar anonymisaasje. Mei in keppelingsoanfal kombineart de oanfaller de orizjinele gegevens mei oare tagonklike gegevensboarnen om in yndividu unyk te identifisearjen en (faaks gefoelige) ynformaasje oer dizze persoan te learen.
Hjir is de kaai de beskikberens fan oare gegevensboarnen dy't no oanwêzich binne, of yn 'e takomst oanwêzich kinne wurde. Tink oer josels. Hoefolle fan jo eigen persoanlike gegevens binne te finen op Facebook, Instagram of LinkedIn dy't mooglik kinne wurde misbrûkt foar in keppelingsoanfal?
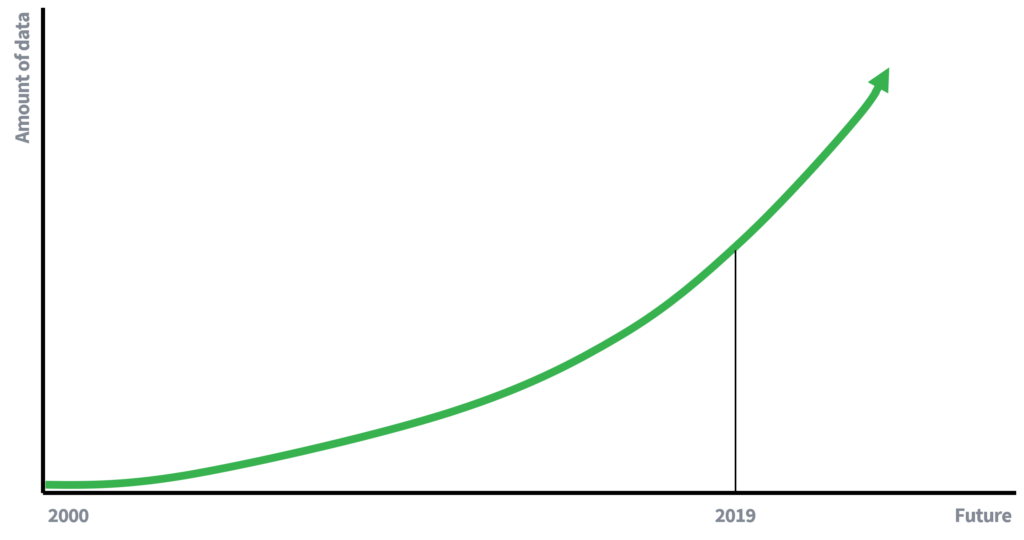
Yn eardere dagen wie de beskikberens fan gegevens folle mear beheind, wat foar in part ferklearret wêrom't it fuortheljen fan nammen genôch wie om de privacy fan yndividuen te behâlden. Minder beskikbere gegevens betsjutte minder kânsen foar it keppeljen fan gegevens. Wy binne lykwols no (aktive) dielnimmers oan in data-oandreaune ekonomy, wêr't de hoemannichte gegevens groeit mei in eksponentiell taryf. Mear gegevens, en ferbettering fan technology foar it sammeljen fan gegevens sil liede ta ferhege potensjeel foar oanslach op oansluting. Wat soe men yn 10 jier skriuwe oer it risiko op in keppelingsoanfal?
Yllustraasje 1
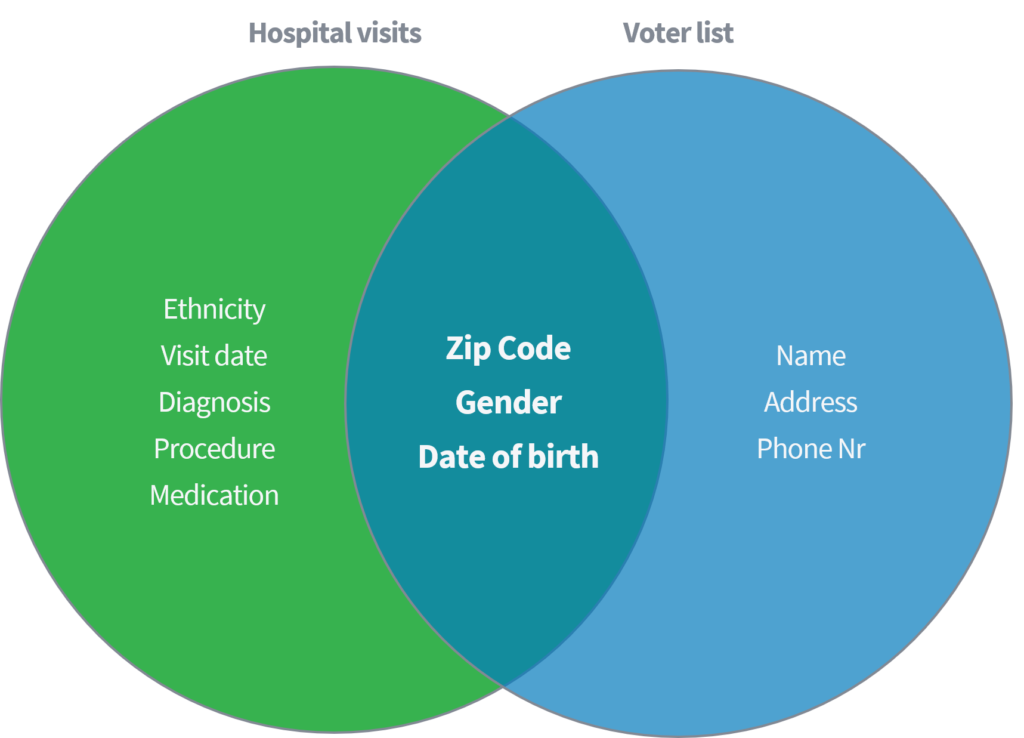
Sweeney (2002) demonstrearre yn in akademysk papier hoe't se gefoelige medyske gegevens koe identifisearje en ophelje fan yndividuen op basis fan it keppeljen fan in publike beskikbere dataset fan 'sikehûsbesites' oan de iepenbier beskikber stimmegistrar yn 'e Feriene Steaten. Beide datasets waarden oannommen dat se goed anonymisearre wiene troch it wiskjen fan nammen en oare direkte identifisearders.
Yllustraasje 2
Op grûn fan allinich de trije parameters (1) postkoade, (2) geslacht en (3) bertedatum, liet se sjen dat 87% fan 'e heule Amerikaanske befolking opnij koe wurde identifisearre troch oerienkommende neamde attributen fan beide datasets. Sweeney herhelle doe har wurk mei it hawwen fan 'lân' as alternatyf foar 'Postkoade'. Derneist toande se dat 18% fan 'e heule Amerikaanske befolking allinich koe wurde identifisearre troch tagong te hawwen ta in dataset mei ynformaasje oer it (1) heitelân, (2) geslacht en (3) bertedatum. Tink oer de niisneamde iepenbiere boarnen, lykas Facebook, LinkedIn of Instagram. Is jo lân, geslacht en bertedatum sichtber, of kinne oare brûkers it ôflûke?
Yllustraasje 3
| Kwasi-identifisearders | % unyk identifisearre fan 'e Amerikaanske befolking (248 miljoen) |
| 5-sifers ZIP, geslacht, bertedatum | 87% |
| plak, geslacht, bertedatum | 53% |
| lân, geslacht, bertedatum | 18% |
Dit foarbyld lit sjen dat it opmerklik maklik kin wêze om persoanen te de-anonymisearjen yn skynber anonime gegevens. Earst jout dizze stúdzje in enoarme omfang fan risiko oan, lykas 87% fan 'e Amerikaanske befolking kin maklik wurde identifisearre mei pear skaaimerken. Twad, de bleatstelde medyske gegevens yn dizze stúdzje wiene heul gefoelich. Foarbylden fan gegevens fan bleatstelde persoanen út 'e dataset fan sikehûsbesites omfetsje etnisiteit, diagnoaze en medisinen. Eigenskippen dy't men leaver geheim hâlde kin, bygelyks fan fersekeringsbedriuwen.
In oar risiko om allinich direkte identifisearders te ferwiderjen, lykas nammen, ûntstiet as ynformeare persoanen superieure kennis of ynformaasje hawwe oer trekken of gedrach fan spesifike persoanen yn 'e dataset. Op grûn fan har kennis kin de oanfaller dan mooglik spesifike gegevensrekords keppelje oan wirklike minsken.
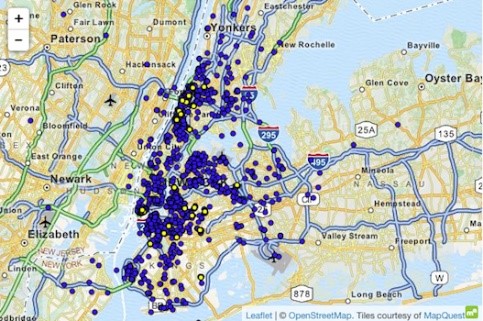
In foarbyld fan in oanfal op in dataset mei superieure kennis is de taksy -saak yn New York, wêr't Atockar (2014) spesifike persoanen koe ûntmaskerje. De brûkte dataset befette alle taksyreizen yn New York, ferrike mei basisattributen lykas startkoördinaten, einkoördinaten, priis en tip fan 'e rit.
In ynformeare yndividu dy't wit dat New York taksyreizen koe ôfliede nei folwoeksen klub 'Hustler'. Troch de 'einlokaasje' te filterjen, lei hy de krekte startadressen ôf en identifisearre dêrmei ferskate faak besikers. Lykwols koe men taksyreizen ôfliede doe't it thúsadres fan it yndividu bekend wie. De tiid en lokaasje fan ferskate ferneamde filmstjerren waarden ûntdutsen op roddelplakken. Nei it keppeljen fan dizze ynformaasje oan 'e NYC -taksydata, wie it maklik om har taksyreizen ôf te lieden, it bedrach dat se betelle, en oft se hiene tipt.
Yllustraasje 4
drop-off koördinaten Hustler
Bradley Cooper
Jessica Alba
In mienskiplike line fan argumintaasje is 'dizze gegevens binne weardeleas' of 'nimmen kin wat dwaan mei dizze gegevens'. Dit is faaks in misferstân. Sels de meast ûnskuldige gegevens kinne in unike 'fingerprint' foarmje en wurde brûkt om persoanen opnij te identifisearjen. It is it risiko ôflaat fan 'e leauwe dat de gegevens sels weardeleas binne, wylst it net is.
It risiko op identifikaasje sil tanimme mei de tanimming fan gegevens, AI, en oare ark en algoritmen dy't it ûntdekken fan komplekse relaasjes yn gegevens mooglik meitsje. Dêrom, sels as jo dataset no net kin wurde ûntdekt, en nei alle gedachten nutteloos is foar hjoed foar net autorisearre persoanen, kin it moarn net wêze.
In geweldich foarbyld is it gefal wêryn Netflix fan doel wie syn R & D -ôfdieling te crowdsource troch in iepen Netflix -konkurrinsje yn te fieren om har systeem foar oanbefelling foar films te ferbetterjen. 'Dejinge dy't it gearwurkingsfilteralgoritme ferbetteret foar it foarsizzen fan brûkersbeoardielingen foar films wint in priis fan US $ 1,000,000'. Om de mannichte te stypjen publisearre Netflix in dataset mei allinich de folgjende basisattributen: userID, film, datum fan graad en graad (dus gjin fierdere ynformaasje oer de brûker as film sels).
Yllustraasje 5
| UserID | Film | Datum fan graad | Klasse |
| 123456789 | Unmooglike missy | 10-12-2008 | 4 |
Yn isolemint ferskynden de gegevens nutteloos. By it stellen fan de fraach 'Is d'r klantynformaasje yn' e dataset dy't privee moat wurde hâlden? ', Wie it antwurd:
'Nee, alle klantidentifisearjende ynformaasje is fuorthelle; alles wat oerbliuwt binne wurdearrings en datums. Dit folget ús privacybelied ... '
Narayanan (2008) fan 'e Universiteit fan Teksas yn Austin bewiisde lykwols oars. De kombinaasje fan graden, datum fan graad en film fan in yndividu foarmet in unike film-fingerprint. Tink oer jo eigen Netflix -gedrach. Hoefolle minsken tinke jo dat se deselde set films seagen? Hoefolle seagen deselde set films tagelyk?
Haadfraach, hoe kin dizze fingerprint oerienkomme? It wie earder simpel. Op grûn fan ynformaasje fan 'e bekende film-wurdearring-webside IMDb (Internet Movie Database), koe in ferlykbere fingerprint wurde foarme. Dêrom kinne persoanen opnij wurde identifisearre.
Wylst gedrach fan films sjen miskien net wurdt beskôge as gefoelige ynformaasje, tink dan oer jo eigen gedrach-soene jo it slim fine as it iepenbier waard? Foarbylden dy't Narayanan yn syn papier levere, binne politike foarkarren (wurdearrings oer 'Jezus fan Nazareth' en 'It evangeelje fan Johannes') en seksuele foarkarren (wurdearrings op 'Bent' en 'Queer as folk') dy't maklik kinne wurde distillearre.
GDPR is miskien net superspannend, noch de sulveren kûgel ûnder blog-ûnderwerpen. Dochs is it handich om de definysjes direkt te krijen by it ferwurkjen fan persoanlike gegevens. Sûnt dit blog giet oer de mienskiplike miskonsepsje fan it ferwiderjen fan kolommen as in manier om gegevens te anonymisearjen en jo op te lieden as gegevensprosessor, litte wy begjinne mei it ferkennen fan de definysje fan anonymisaasje neffens GDPR.
Neffens oerweging 26 fan 'e GDPR wurdt anonymisearre ynformaasje definieare as:
'ynformaasje dy't net relatearret oan in identifisearre as identifisearbere natuerlike persoan as persoanlike gegevens dy't anonime binne makke op sa'n manier dat it ûnderwerp net al dan net identifisearber is.'
Om't men persoanlike gegevens ferwurket dy't betrekking hat op in natuerlike persoan, is mar diel 2 fan 'e definysje relevant. Om te foldwaan oan 'e definysje, moat men derfoar soargje dat it ûnderwerp (yndividu) net of net mear identifisearber is. Lykas oanjûn yn dit blog, is it lykwols opmerklik ienfâldich om persoanen te identifisearjen op basis fan in pear attributen. Dat, it ferwiderjen fan nammen út in dataset foldocht net oan de GDPR -definysje fan anonymisaasje.
Wy daagden ien gewoan beskôge en, spitigernôch, noch faak tapaste oanpak fan gegevensanonimisaasje út: nammen ferwiderje. Yn it Guess Who -spiel en fjouwer oare foarbylden oer:
it waard oantoand dat it ferwiderjen fan nammen mislearret as anonymisaasje. Hoewol de foarbylden opfallende gefallen binne, toant elk de ienfâld fan weridentifikaasje en de mooglike negative ynfloed op de privacy fan yndividuen.
Ta beslút, it ferwiderjen fan nammen út jo dataset resulteart net yn anonime gegevens. Dêrom moatte wy better foarkomme dat wy beide termen trochinoar brûke. Ik hoopje oprjocht dat jo dizze oanpak net sille tapasse foar anonymisaasje. En, as jo dat noch dogge, soargje derfoar dat jo en jo team de privacyrisiko's folslein begripe, en tastien binne om dy risiko's te akseptearjen út namme fan 'e troffen persoanen.
Nim kontakt op mei Syntho en ien fan ús saakkundigen sil yn kontakt komme mei jo op 'e snelheid fan ljocht om de wearde fan syntetyske gegevens te ferkennen!