

Wat binne syntetyske gegevens?
It antwurd is relatyf ienfâldich. Wylst orizjinele gegevens wurde sammele yn al jo ynteraksjes mei echte persoanen (bgl. kliïnten, pasjinten, meiwurkers ensfh.) En fia al jo ynterne prosessen, wurde syntetyske gegevens generearre troch in kompjûteralgoritme. Dit kompjûteralgoritme genereart folslein nije en keunstmjittige datapunten.
Los útdagings foar gegevensprivacy op
Syntetysk oanmakke gegevens besteane út folslein nije en keunstmjittige datapunten mei gjin ien-op-ien relaasjes mei de orizjinele gegevens. Hjirtroch kin gjin fan 'e syntetyske gegevenspunten werom te finen of omkeard wurde makke nei orizjinele gegevens. As gefolch, syntetyske gegevens binne frijsteld fan privacy regeljouwing, lykas de GDPR en tsjinnet as oplossing foar it oplossen en oerwinne gegevens-privacy útdagings.
Fergrutsje en simulearje
It generative aspekt fan syntetyske gegevensgeneraasje makket it mooglik om folslein nije gegevens te fergrutsjen en te simulearjen. Dit fungearret as oplossing as jo net genôch gegevens hawwe (datakrapte), edge-gefallen wolle up-sample of as jo noch gjin gegevens hawwe.
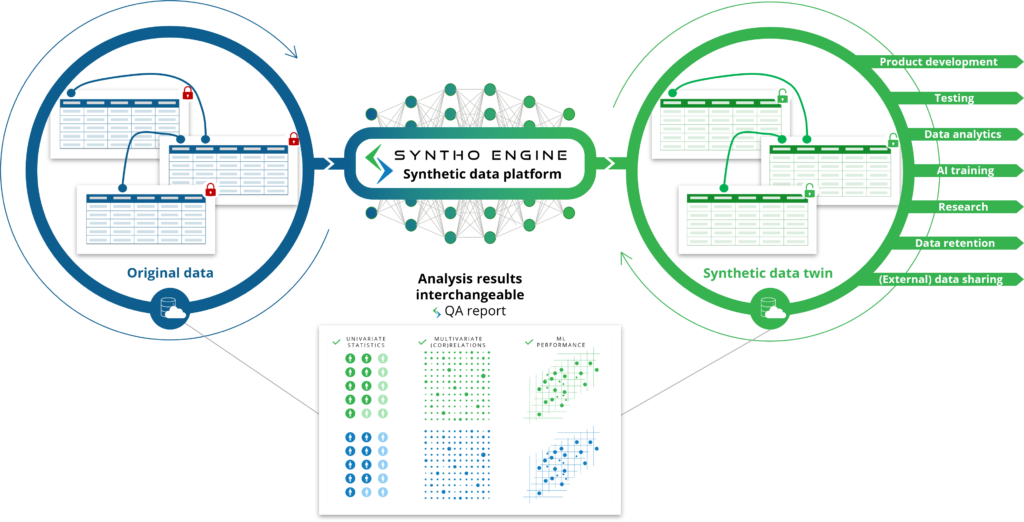
Hjir is de fokus fan Syntho struktureare gegevens (gegevens opmakke yn tabellen mei rigen en kolommen, lykas jo sjogge yn in Excel -blêden), mar wy yllustrearje altyd altyd it konsept fan syntetyske gegevens fia ôfbyldings, om't it oantrekliker is.
Trije soarten syntetyske gegevens besteane wol binnen de syntetyske gegevensparaplu. Dy 3 soarten syntetyske gegevens binne: dummy gegevens, regel-basearre oanmakke syntetyske gegevens en syntetyske gegevens oanmakke troch keunstmjittige yntelliginsje (AI). Wy ferklearje koart wat de 3 ferskillende soarten syntetyske gegevens binne.
Dummy gegevens binne willekeurich oanmakke gegevens (bgl. troch in mock data generator).
Dêrtroch wurde skaaimerken, relaasjes en statistyske patroanen dy't yn 'e orizjinele gegevens binne net bewarre, fêstlein en reprodusearre yn' e generearre dummygegevens. Hjirtroch is de represintativiteit fan dummygegevens / mockgegevens minimaal yn ferliking mei de orizjinele gegevens.
Regel-basearre oanmakke syntetyske gegevens binne syntetyske gegevens oanmakke troch in foarôf definiearre set fan regels. Foarbylden fan dy foarôf definieare regels kinne wêze dat jo syntetyske gegevens hawwe wolle mei in bepaalde minimumwearde, maksimumwearde of gemiddelde wearde. Elk fan 'e skaaimerken, relaasjes en statistyske patroanen dy't jo wolle hawwe reprodusearre yn' e regel-basearre generearre syntetyske gegevens, moatte foarôf definieare wurde.
Dêrtroch sil de gegevenskwaliteit sa goed wêze as de foarôf definieare set regels. Dit resulteart yn útdagings as hege gegevenskwaliteit fan essinsje is. Earst kin men mar in beheinde set regels definiearje dy't wurde fêstlein yn 'e syntetyske gegevens. Derneist sil it ynstellen fan meardere regels typysk resultearje yn oerlappende en tsjinstridige regels. Boppedat sille jo noait alle relevante regels folslein dekke. Fierder kinne der relevante regels wêze wêrfan jo net iens bewust binne. En as lêste (en net te ferjitten), dit sil jo in protte tiid en enerzjy nimme, wat resulteart yn in net-effisjinte oplossing.
Lykas jo fan 'e namme ferwachtsje, binne syntetyske gegevens generearre troch keunstmjittige yntelliginsje (AI) syntetyske gegevens generearre troch in keunstmjittige yntelliginsje (AI) algoritme. It AI-model wurdt oplaat op 'e orizjinele gegevens om alle skaaimerken, relaasjes en statistyske patroanen te learen. Dêrnei is dit AI-algoritme yn steat om folslein nije datapunten te generearjen en dizze nije datapunten op sa'n manier te modellen dat it de skaaimerken, relaasjes en statistyske patroanen fan 'e orizjinele dataset reprodusearret. Dit is wat wy neame in syntetyske gegevens twilling.
It AI-model mimiket orizjinele gegevens om syntetyske gegevenstwillingen te generearjen dy't kinne wurde brûkt as-as it orizjinele gegevens binne. Dit ûntsluten ferskate gebrûksgefallen wêr't de AI-genereare syntetyske gegevens kinne wurde brûkt as alternatyf foar it brûken fan orizjinele (gefoelige) gegevens, lykas it brûken fan AI-genereare syntetyske gegevens as testgegevens, demogegevens of foar analytiken.
Yn ferliking mei regelbasearre generearre syntetyske gegevens: ynstee fan jo relevante regels te studearjen en te definiearjen, docht it AI-algoritme dit automatysk foar jo. Hjir sille net allinich skaaimerken, relaasjes en statistyske patroanen wurde behannele wêrfan jo bewust binne, ek skaaimerken, relaasjes en statistyske patroanen wêrfan jo net iens bewust binne, wurde behannele.
Ofhinklik fan jo gebrûk, wurdt in kombinaasje fan dummy-gegevens / mock-gegevens, regel-basearre generearre syntetyske gegevens of syntetyske gegevens generearre troch keunstmjittige yntelliginsje (AI) advisearre. Dit oersjoch jout jo in earste yndikaasje fan hokker type syntetyske gegevens jo moatte brûke. Om't Syntho se allegear stipet, nim dan gerêst kontakt op mei ús saakkundigen om jo gebrûksgefal mei ús te ferdjipjen.
