حدس بزنید چه کسی؟ 5 مثال که چرا حذف نام ها یک گزینه نیست



حدس بزن کی؟ اگرچه مطمئن هستم که اکثر شما این بازی را در گذشته می شناسید ، اما در اینجا خلاصه ای کوتاه از آن است. هدف بازی: نام شخصیت کارتونی انتخاب شده توسط حریف خود را با پرسیدن س yesالات "بله" و "نه" ، مانند "آیا شخص کلاه می گذارد؟" یا "آیا فرد عینک می زند"؟ بازیکنان بر اساس پاسخ حریف نامزدها را حذف می کنند و ویژگی هایی را که مربوط به شخصیت مرموز حریف است یاد می گیرند. اولین بازیکنی که شخصیت مرموز بازیکن دیگر را تشخیص می دهد برنده بازی است.
فهمیدی. شخص باید تنها با دسترسی به ویژگی های مربوطه ، یک مجموعه داده را شناسایی کند. در واقع ، ما به طور مرتب این مفهوم Guess Who را در عمل به کار می بریم ، اما سپس بر روی مجموعه داده های قالب بندی شده با سطرها و ستون ها که شامل ویژگی های افراد واقعی است ، استفاده می شود. تفاوت اصلی هنگام کار با داده ها این است که مردم تمایل دارند نقصی را که افراد واقعی می توانند با دسترسی به چند ویژگی دسترسی نداشته باشند ، نادیده بگیرند.
همانطور که بازی Guess Who نشان می دهد ، شخصی می تواند افراد را تنها با دسترسی به چند ویژگی شناسایی کند. این به عنوان یک مثال ساده از این است که چرا حذف "نام" (یا سایر شناسه های مستقیم) از مجموعه داده شما به عنوان یک روش ناشناس ماندن ناموفق است. در این وبلاگ ، ما چهار مورد کاربردی ارائه می دهیم تا شما را در مورد خطرات حریم خصوصی مرتبط با حذف ستون ها به عنوان وسیله ای برای ناشناس ماندن اطلاعات مطلع کنیم.
خطر حملات پیوندی مهمترین دلیل این است که چرا حذف نامها (دیگر) به عنوان روشی برای ناشناس ماندن کار نمی کند. با حمله پیوندی ، مهاجم داده های اصلی را با سایر منابع داده در دسترس ترکیب می کند تا بتواند یک فرد را به طور منحصر به فرد شناسایی کرده و اطلاعات (اغلب حساس) را در مورد این شخص بیاموزد.
نکته اصلی در دسترس بودن سایر منابع داده ای است که در حال حاضر وجود دارند یا ممکن است در آینده نیز وجود داشته باشند. به فکر خودت باش. چه مقدار از اطلاعات شخصی شما را می توان در فیس بوک ، اینستاگرام یا LinkedIn یافت که به طور بالقوه می تواند برای حمله پیوند مورد سوء استفاده قرار گیرد؟
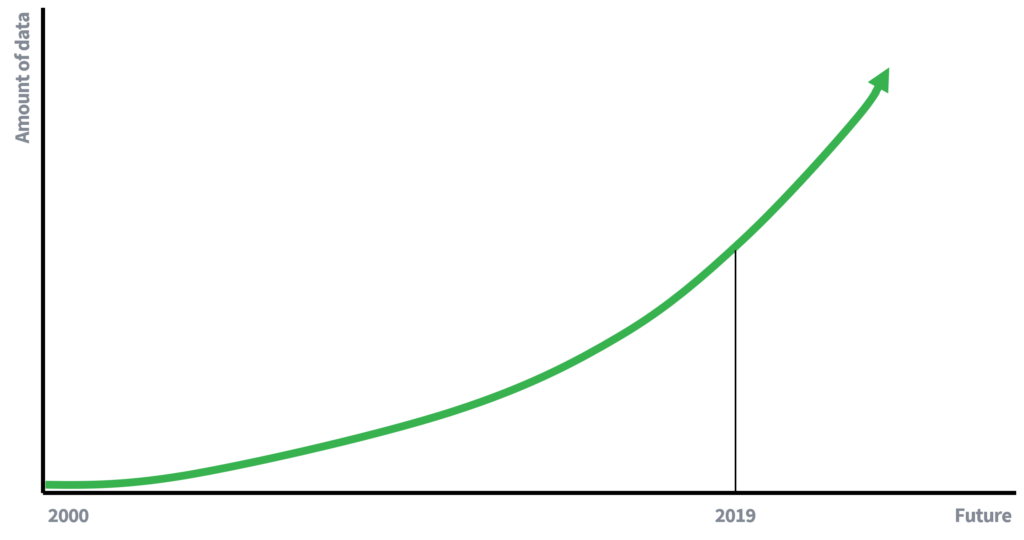
در روزهای گذشته ، دسترسی به داده ها بسیار محدودتر بود ، که تا حدی توضیح می دهد که چرا حذف نام ها برای حفظ حریم خصوصی افراد کافی بود. داده های کمتر در دسترس به معنی فرصت های کمتر برای پیوند داده ها است. با این حال ، ما در حال حاضر (فعال) در اقتصاد داده محور مشارکت داریم (جایی که میزان داده ها با سرعت نمایی در حال رشد است. داده های بیشتر و بهبود فناوری جمع آوری داده ها منجر به افزایش پتانسیل حملات پیوندی می شود. چه کسی در 10 سال آینده در مورد خطر حمله پیوندی می نویسد؟
تصویر 1
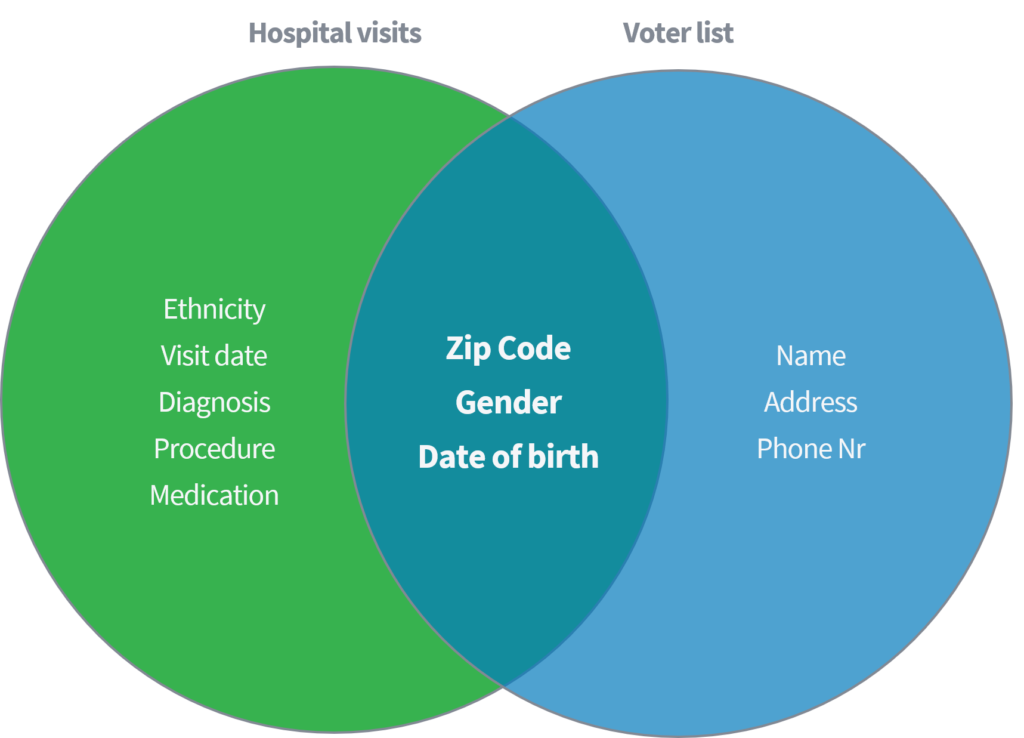
سوینی (2002) در مقاله ای دانشگاهی نشان داد که چگونه می تواند داده های حساس پزشکی را از افراد بر اساس پیوند مجموعه داده های عمومی "بازدید از بیمارستان" به ثبت کننده رای عمومی در ایالات متحده پیوند بخورد و بازیابی کند. هر دو مجموعه داده از طریق حذف نام ها و سایر شناسه های مستقیم به طور صحیح ناشناس هستند.
تصویر 2
تنها بر اساس سه پارامتر (1) کد پستی ، (2) جنسیت و (3) تاریخ تولد ، وی نشان داد که 87٪ از کل جمعیت ایالات متحده را می توان با تطبیق ویژگی های فوق از هر دو مجموعه داده دوباره شناسایی کرد. سوینی سپس کار خود را با داشتن "کشور" به عنوان جایگزینی برای "کد پستی" تکرار کرد. علاوه بر این ، او نشان داد که 18 درصد از کل جمعیت ایالات متحده را فقط می توان با دسترسی به مجموعه داده حاوی اطلاعات مربوط به (1) کشور مبدا ، (2) جنسیت و (3) تاریخ تولد شناسایی کرد. به منابع عمومی ذکر شده مانند فیس بوک ، لینکدین یا اینستاگرام فکر کنید. آیا کشور ، جنسیت و تاریخ تولد شما قابل مشاهده است یا سایر کاربران می توانند آن را کسر کنند؟
تصویر 3
| شبه شناسه ها | ٪ از جمعیت ایالات متحده به طور منحصر به فرد شناسایی شده است (248 میلیون نفر) |
| ZIP 5 رقمی ، جنسیت ، تاریخ تولد | ٪۱۰۰ |
| محل، جنسیت ، تاریخ تولد | ٪۱۰۰ |
| کشور، جنسیت ، تاریخ تولد | ٪۱۰۰ |
این مثال نشان می دهد که به راحتی می توان افراد ناشناس را در داده های به ظاهر ناشناس حذف کرد. اول ، این مطالعه نشان می دهد که خطر بزرگی وجود دارد 87٪ از جمعیت ایالات متحده را می توان با استفاده از آن به راحتی شناسایی کرد چند ویژگیبه دوم ، داده های پزشکی در معرض در این مطالعه بسیار حساس بود. نمونه هایی از داده های افراد در معرض مجموعه داده های مراجعه به بیمارستان شامل قومیت ، تشخیص و دارو است. ویژگیهایی که ممکن است به عنوان مثال از شرکتهای بیمه مخفی بماند.
خطر دیگری برای حذف فقط شناسه های مستقیم ، مانند نام ها ، زمانی ایجاد می شود که افراد مطلع از دانش یا اطلاعات برتر در مورد ویژگی ها یا رفتار افراد خاص در مجموعه داده برخوردار باشند.به بر اساس دانش خود ، مهاجم ممکن است بتواند سوابق داده های خاص را به افراد واقعی پیوند دهد.
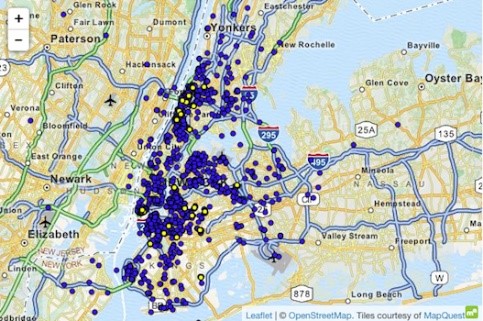
نمونه ای از حمله به مجموعه داده با استفاده از دانش برتر ، مورد تاکسی نیویورک است ، جایی که Atockar (2014) توانست افراد خاصی را نقاب کند. مجموعه داده های به کار گرفته شده شامل تمام سفرهای تاکسی در نیویورک ، غنی شده با ویژگی های اساسی مانند مختصات شروع ، مختصات پایان ، قیمت و نکته سواری است.
یک فرد آگاه که می داند نیویورک می تواند سفرهای تاکسی به باشگاه بزرگسالان "Hustler" انجام دهد. با فیلتر کردن "محل پایان" ، آدرس دقیق شروع را بدست آورد و از این طریق بازدیدکنندگان مکرر مختلف را شناسایی کرد. به طور مشابه ، زمانی که آدرس منزل فرد مشخص شد ، می توان از تاکسی سواری استفاده کرد. زمان و مکان چندین ستاره مشهور سینما در سایت های شایعات کشف شد. پس از پیوند دادن این اطلاعات به داده های تاکسی نیویورک ، به راحتی می توان از سواری تاکسی آنها ، مبلغی که پرداخت کرده اند و آیا آنها تخفیف دریافت کرده اند ، استفاده کرد.
تصویر 4
drop-off مختصات Hustler
بردلی کوپر
جسیکا آلبا
یک استدلال رایج این است که "این داده ها بی ارزش هستند" یا "هیچ کس نمی تواند با این داده ها کاری انجام دهد". این اغلب یک تصور اشتباه است. حتی بی گناه ترین داده ها می توانند یک "اثر انگشت" منحصر به فرد ایجاد کرده و برای شناسایی مجدد افراد استفاده شوند. این ریسک ناشی از این باور است که داده ها به خودی خود بی ارزش هستند ، در حالی که چنین نیست.
خطر شناسایی با افزایش داده ها ، هوش مصنوعی و سایر ابزارها و الگوریتم ها که کشف روابط پیچیده در داده ها را امکان پذیر می کند ، افزایش می یابد. در نتیجه ، حتی اگر نمی توان مجموعه داده شما را در حال حاضر کشف کرد ، و احتمالاً برای افراد غیرمجاز امروز بی فایده است ، ممکن است فردا نباشد.
یک مثال عالی در مورد مواردی است که Netflix قصد داشت با معرفی یک مسابقه باز Netflix برای بهبود سیستم توصیه فیلم خود ، بخش تحقیق و توسعه خود را جمع آوری کند. "الگوریتم فیلترینگ مشارکتی برای پیش بینی رتبه کاربران برای فیلم ها جایزه ای معادل 1,000,000،XNUMX،XNUMX دلار دریافت می کند". به منظور حمایت از جمعیت ، Netflix مجموعه داده ای را منتشر کرد که فقط شامل ویژگیهای اصلی زیر بود: userID ، فیلم ، تاریخ درجه و درجه (بنابراین اطلاعات بیشتری در مورد کاربر یا خود فیلم وجود ندارد).
تصویر 5
| شناسه کاربری | فیلم سینما | تاریخ نمره | درجه |
| 123456789 | ماموریت غیر ممکن است | 10-12-2008 | 4 |
به صورت جداگانه ، داده ها بیهوده به نظر می رسند. هنگام پرسیدن سوال "آیا اطلاعات مشتری در مجموعه داده وجود دارد که باید خصوصی نگه داشته شود؟" ، پاسخ این بود:
نه ، همه اطلاعات شناسایی مشتری حذف شده است. تنها چیزی که باقی می ماند رتبه بندی و تاریخ است. این از سیاست حفظ حریم خصوصی ما پیروی می کند… '
با این حال ، نارایانان (2008) از دانشگاه تگزاس در آستین خلاف این را ثابت کرد. ترکیب نمرات ، تاریخ نمره و فیلم یک فرد یک اثر انگشت فیلم منحصر به فرد را تشکیل می دهد. به رفتار Netflix خودتان فکر کنید. فکر می کنید چند نفر همان مجموعه فیلم را تماشا کرده اند؟ چند نفر همزمان مجموعه فیلم های مشابه را تماشا کردند؟
سوال اصلی ، چگونه می توان با این اثر انگشت مطابقت داد؟ نسبتاً ساده بود بر اساس اطلاعات وب سایت مشهور رتبه بندی فیلم IMDb (Internet Movie Database) ، می توان یک اثر انگشت مشابه ایجاد کرد. در نتیجه می توان افراد را دوباره شناسایی کرد.
در حالی که رفتار تماشای فیلم ممکن است به عنوان اطلاعات حساس در نظر گرفته نشود ، به رفتار خود فکر کنید-اگر در معرض دید عموم قرار بگیرد ، برای شما مهم نیست؟ نمونه هایی که نارایانان در مقاله خود آورده است ترجیحات سیاسی (رتبه بندی "عیسی ناصری" و "انجیل یوحنا") و ترجیحات جنسی (رتبه بندی "Bent" و "Queer as folk") است که به راحتی قابل تقطیر است.
GDPR ممکن است نه فوق العاده هیجان انگیز باشد ، نه گلوله نقره ای در میان موضوعات وبلاگ. با این حال ، بدست آوردن تعاریف مستقیم هنگام پردازش داده های شخصی مفید است. از آنجا که این وبلاگ در مورد تصور غلط رایج در مورد حذف ستون ها به عنوان راهی برای ناشناس ماندن داده ها و آموزش شما به عنوان پردازنده داده است ، اجازه دهید با بررسی تعریف ناشناس ماندن بر اساس GDPR شروع کنیم.
طبق بند 26 GDPR ، اطلاعات ناشناس به شرح زیر تعریف می شود:
"اطلاعاتی که مربوط به شخص حقیقی یا شناسایی نشده یا داده های شخصی ناشناس است به گونه ای که موضوع داده ها قابل شناسایی یا دیگر قابل شناسایی نیست."
از آنجا که داده های شخصی مربوط به شخص حقیقی پردازش می شود ، فقط قسمت 2 این تعریف مربوط است. برای مطابقت با تعریف ، باید اطمینان حاصل شود که موضوع داده (فرد) قابل شناسایی نیست یا دیگر قابل شناسایی نیست. همانطور که در این وبلاگ نشان داده شده است ، اما شناسایی افراد بر اساس چند ویژگی بسیار ساده است. بنابراین ، حذف نامها از مجموعه داده مطابق با تعریف ناشناس ماندن GDPR نیست.
ما یک رویکرد متداول و متأسفانه هنوز مکرر برای ناشناس ماندن داده ها را حذف کردیم: حذف نام. در بازی Guess Who و چهار مثال دیگر درباره:
نشان داده شد که حذف نام ها به عنوان ناشناس ناموفق است. اگرچه مثالها موارد قابل توجهی هستند ، اما هر کدام سادگی شناسایی مجدد را نشان می دهند و تأثیر منفی بالقوه بر حریم خصوصی افراد.
در نتیجه ، حذف نامها از مجموعه داده شما منجر به داده های ناشناس نمی شود. بنابراین ، بهتر است از به کار بردن هر دو واژه به جای یکدیگر اجتناب کنیم. من صمیمانه امیدوارم که این روش را برای ناشناس ماندن اعمال نکنید. و اگر هنوز هم می دانید ، اطمینان حاصل کنید که شما و تیم شما خطرات حریم خصوصی را به طور کامل درک کرده اید و اجازه دارید این خطرات را به نمایندگی از افراد آسیب دیده بپذیرید.
با سینتو تماس بگیرید و یکی از کارشناسان ما با سرعت نور با شما تماس می گیرد تا ارزش داده های مصنوعی را کشف کند!