

داده های مصنوعی چیست؟
پاسخ نسبتا ساده است. در حالی که داده های اصلی در تمام تعاملات شما با افراد واقعی (مانند مشتریان، بیماران، کارمندان و غیره) جمع آوری می شود و از طریق تمام فرآیندهای داخلی شما، داده های مصنوعی توسط یک الگوریتم کامپیوتری تولید می شود. این الگوریتم کامپیوتری نقاط داده کاملاً جدید و مصنوعی تولید می کند.
چالش های حفظ حریم خصوصی داده ها را حل کنید
داده های مصنوعی تولید شده از نقاط داده کاملاً جدید و مصنوعی تشکیل شده است که هیچ رابطه یک به یک با داده های اصلی ندارند. از این رو، هیچ یک از نقاط داده مصنوعی را نمی توان به داده های اصلی ردیابی کرد یا مهندسی معکوس کرد. در نتیجه، داده های مصنوعی از مقررات حفظ حریم خصوصی، مانند GDPR مستثنی هستند و به عنوان راه حلی برای حل و غلبه بر چالش های حریم خصوصی داده ها عمل می کنند.
تقویت و شبیه سازی
جنبه تولیدی تولید داده های مصنوعی امکان تقویت و شبیه سازی داده های کاملاً جدید را فراهم می کند. این به عنوان راه حل عمل می کند زمانی که شما داده کافی ندارید (کمبود داده)، می خواهید موارد لبه را نمونه برداری کنید یا زمانی که هنوز داده ای ندارید.
در اینجا ، تمرکز Syntho بر داده های ساختار یافته است (داده هایی که در جداول حاوی سطرها و ستون ها قالب بندی شده اند ، مانند آنچه در برگه های Excel مشاهده می کنید) ، اما ما همیشه دوست داریم مفهوم داده های مصنوعی را از طریق تصاویر نشان دهیم ، زیرا جذابیت بیشتری دارد.
سه نوع داده مصنوعی در چتر داده مصنوعی وجود دارد. این 3 نوع داده مصنوعی عبارتند از: داده های ساختگی، داده های مصنوعی تولید شده مبتنی بر قانون و داده های مصنوعی تولید شده توسط هوش مصنوعی (AI). ما به طور خلاصه توضیح می دهیم که 3 نوع مختلف داده مصنوعی چیست.
دادههای ساختگی دادههایی هستند که بهطور تصادفی تولید میشوند (مثلاً توسط یک تولیدکننده داده ساختگی).
در نتیجه، ویژگیها، روابط و الگوهای آماری که در دادههای اصلی هستند، در دادههای ساختگی تولید شده حفظ، ضبط و تکثیر نمیشوند. از این رو، نمایندگی داده های ساختگی / داده های ساختگی در مقایسه با داده های اصلی حداقل است.
داده های مصنوعی تولید شده مبتنی بر قانون، داده های مصنوعی است که توسط مجموعه ای از قوانین از پیش تعریف شده تولید می شود. نمونه هایی از آن قوانین از پیش تعریف شده می تواند این باشد که می خواهید داده های مصنوعی با حداقل مقدار معین، حداکثر مقدار یا مقدار متوسط داشته باشید. هر یک از ویژگیها، روابط و الگوهای آماری که میخواهید در دادههای مصنوعی تولید شده مبتنی بر قانون بازتولید شود، باید از قبل تعریف شده باشد.
در نتیجه، کیفیت داده ها به خوبی مجموعه قوانین از پیش تعریف شده خواهد بود. این منجر به چالش هایی می شود که کیفیت داده بالا از اهمیت بالایی برخوردار است. اول، می توان تنها مجموعه محدودی از قوانین را برای ثبت در داده های مصنوعی تعریف کرد. علاوه بر این، تنظیم قوانین متعدد معمولاً منجر به همپوشانی و تضاد قوانین می شود. علاوه بر این، شما هرگز تمام قوانین مربوطه را به طور کامل پوشش نمی دهید. علاوه بر این، ممکن است قوانین مرتبطی وجود داشته باشد که شما حتی از آنها آگاه نباشید. و در نهایت (و فراموش نکنیم)، این کار زمان و انرژی زیادی از شما می گیرد و در نتیجه یک راه حل غیر کارآمد ایجاد می شود.
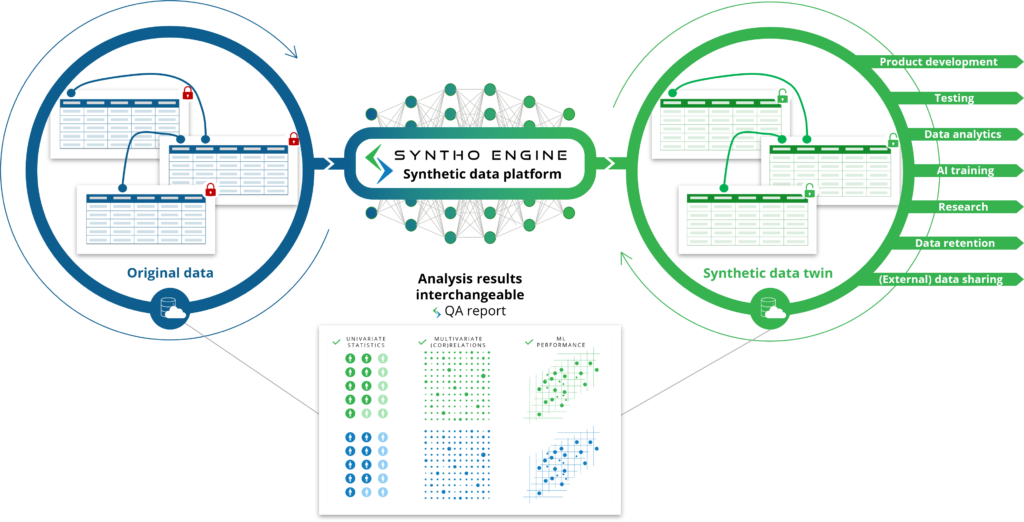
همانطور که از نام انتظار دارید، داده های مصنوعی تولید شده توسط هوش مصنوعی (AI) داده های مصنوعی تولید شده توسط یک الگوریتم هوش مصنوعی (AI) است. مدل هوش مصنوعی بر روی داده های اصلی آموزش داده شده است تا تمام ویژگی ها، روابط و الگوهای آماری را بیاموزد. پس از آن، این الگوریتم هوش مصنوعی قادر است نقاط داده کاملاً جدیدی تولید کند و آن نقاط داده جدید را به گونهای مدلسازی کند که ویژگیها، روابط و الگوهای آماری را از مجموعه داده اصلی بازتولید کند. این همان چیزی است که ما به آن داده های مصنوعی دوقلو می گوییم.
مدل هوش مصنوعی از دادههای اصلی تقلید میکند تا دوقلوهای داده مصنوعی تولید کند که میتوانند به عنوان دادههای اصلی استفاده شوند. این قفل موارد استفاده مختلف را باز می کند که در آن داده های مصنوعی تولید شده توسط هوش مصنوعی می تواند به عنوان جایگزین برای استفاده از داده های اصلی (حساس) استفاده شود، مانند استفاده از داده های مصنوعی تولید شده توسط هوش مصنوعی به عنوان داده های آزمایشی، داده های آزمایشی یا برای تجزیه و تحلیل.
در مقایسه با داده های مصنوعی تولید شده مبتنی بر قانون: به جای اینکه شما قوانین مربوطه را مطالعه و تعریف کنید، الگوریتم هوش مصنوعی این کار را به طور خودکار برای شما انجام می دهد. در اینجا نه تنها ویژگی ها، روابط و الگوهای آماری که شما از آنها آگاه هستید، پوشش داده می شود، همچنین ویژگی ها، روابط و الگوهای آماری که شما حتی از آنها اطلاع ندارید نیز پوشش داده می شود.
بسته به مورد استفاده شما، ترکیبی از داده های ساختگی / داده های ساختگی، داده های مصنوعی تولید شده مبتنی بر قانون یا داده های مصنوعی تولید شده توسط هوش مصنوعی (AI) توصیه می شود. این نمای کلی به شما اولین نشانه ای از نوع داده مصنوعی را ارائه می دهد. از آنجایی که Syntho از همه آنها پشتیبانی می کند، با کارشناسان ما تماس بگیرید تا موارد استفاده خود را با ما در عمق پیدا کنید.
