AI-generated Synthetic Data, sayon ug paspas nga pag-access sa taas nga kalidad nga datos?
Ang AI nakamugna og sintetikong datos sa praktis
Si Syntho, usa ka eksperto sa AI-generated synthetic data, nagtumong sa pagliso privacy by design ngadto sa usa ka competitive nga bentaha sa AI-generated synthetic data. Gitabangan nila ang mga organisasyon nga magtukod usa ka lig-on nga pundasyon sa datos nga adunay dali ug paspas nga pag-access sa taas nga kalidad nga datos ug bag-o lang nakadaog sa Philips Innovation Award.
Bisan pa, ang paghimo sa sintetikong datos nga adunay AI usa ka bag-o nga solusyon nga kasagaran nagpaila sa kanunay nga gipangutana nga mga pangutana. Aron matubag kini, gisugdan ni Syntho ang usa ka case-study kauban ang SAS, market leader sa Advanced Analytics ug AI software.
Sa pakigtambayayong sa Dutch AI Coalition (NL AIC), ilang giimbestigar ang bili sa sintetikong datos pinaagi sa pagtandi sa AI-generated synthetic data nga namugna sa Syntho Engine uban sa orihinal nga datos pinaagi sa nagkalain-laing pagtasa sa kalidad sa datos, legal nga balido ug usability.
Dili ba solusyon ang data anonymization?
Ang mga klasiko nga pamaagi sa pag-anonymize adunay managsama nga ilang gimaniobra ang orihinal nga datos aron mapugngan ang pagsubay sa mga indibidwal. Ang mga pananglitan mao ang generalization, pagsumpo, pagpahid, pseudonymization, data masking, ug shuffling sa mga row ug column. Makita nimo ang mga pananglitan sa lamesa sa ubos.
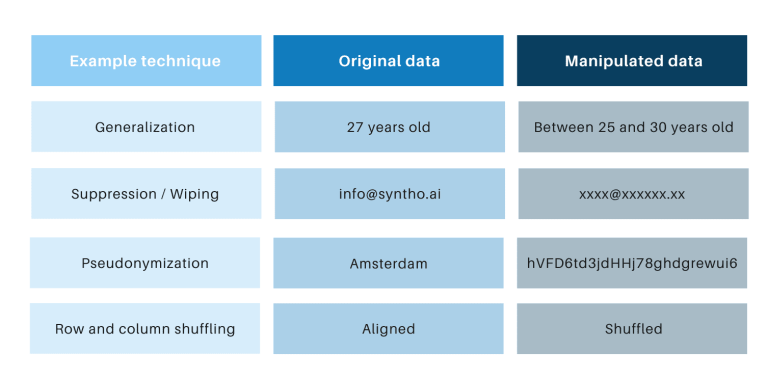
Kini nga mga teknik nagpaila sa 3 nga hinungdanon nga mga hagit:
- Lahi ang ilang pagtrabaho matag tipo sa datos ug matag dataset, nga nagpalisud kanila sa pagsukod. Dugang pa, tungod kay lahi ang ilang pagtrabaho, kanunay adunay debate kung unsang mga pamaagi ang magamit ug kung unsang kombinasyon sa mga teknik ang kinahanglan.
- Kanunay adunay usa-sa-usa nga relasyon sa orihinal nga datos. Nagpasabot kini nga kanunay adunay peligro sa pagkapribado, labi na tungod sa tanan nga bukas nga mga datos ug magamit nga mga pamaagi aron masumpay ang mga datos.
- Gimanipula nila ang datos ug sa ingon giguba ang datos sa proseso. Labi nga makaguba kini alang sa mga buluhaton sa AI diin ang "pagtagna nga gahum" hinungdanon, tungod kay ang dili maayo nga kalidad nga datos moresulta sa dili maayo nga mga panan-aw gikan sa modelo sa AI (Ang garbage-in moresulta sa basura).
Kini nga mga punto gisusi usab pinaagi niining case study.
Usa ka pasiuna sa case study
Para sa case study, ang target dataset usa ka telecom dataset nga gihatag sa SAS nga adunay sulod nga data sa 56.600 customer. Ang dataset adunay 128 ka mga kolum, lakip ang usa ka kolum nga nagpakita kung ang usa ka kustomer mibiya sa kompanya (ie 'nahugno') o wala. Ang tumong sa case study mao ang paggamit sa sintetikong datos sa pagbansay sa pipila ka mga modelo sa pagtagna sa customer churn ug sa pagtimbang-timbang sa performance niadtong nabansay nga mga modelo. Ingon nga ang churn prediction kay usa ka classification task, ang SAS mipili ug upat ka popular nga classification models para maghimo sa mga predictions, lakip ang:
- Random nga lasang
- Pagdugang sa gradient
- Logistic regression
- Neural network
Sa wala pa paghimo sa sintetikong datos, ang SAS random nga nagbahin sa telecom dataset ngadto sa usa ka set sa tren (para sa pagbansay sa mga modelo) ug usa ka set sa holdout (para sa pag-iskor sa mga modelo). Ang pagbaton ug bulag nga holdout set para sa pag-iskor nagtugot sa walay bias nga pagtimbang-timbang kon unsa kamaayo ang mahimo sa modelo sa klasipikasyon kung i-apply sa bag-ong datos.
Gamit ang set sa tren isip input, gigamit ni Syntho ang Syntho Engine niini aron makamugna og sintetikong dataset. Para sa benchmarking, naghimo usab ang SAS og manipulated nga bersyon sa set sa tren human magamit ang lain-laing mga teknik sa anonymization aron maabot ang usa ka piho nga threshold (sa k-anonimity). Ang kanhing mga lakang miresulta ngadto sa upat ka mga dataset:
- Usa ka dataset sa tren (ie ang orihinal nga dataset minus ang holdout dataset)
- Usa ka holdout dataset (ie usa ka subset sa orihinal nga dataset)
- Usa ka wala mailhi nga dataset (base sa dataset sa tren)
- Usa ka sintetikong dataset (base sa dataset sa tren)
Ang mga dataset 1, 3 ug 4 gigamit sa pagbansay sa matag modelo sa klasipikasyon, nga miresulta sa 12 (3 x 4) nga nabansay nga mga modelo. Sunod nga gigamit sa SAS ang holdout dataset aron masukod ang katukma sa matag modelo nga nagtagna sa pag-churn sa kustomer. Ang mga resulta gipresentar sa ubos, sugod sa pipila ka batakang estadistika.
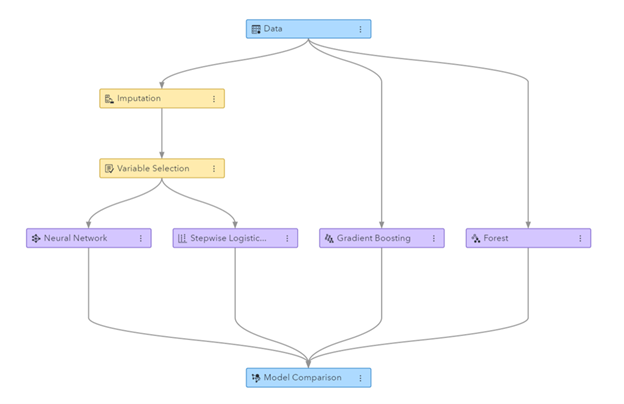
Figure: Machine Learning pipeline nga namugna sa SAS Visual Data Mining ug Machine Learning
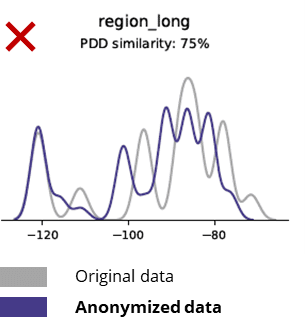
Mga sukaranan nga estadistika kung itandi ang wala mailhi nga datos sa orihinal nga datos
Ang mga teknik sa anonymization makaguba bisan sa mga batakang sumbanan, lohika sa negosyo, mga relasyon ug estadistika (sama sa pananglitan sa ubos). Ang paggamit sa wala mailhi nga datos alang sa sukaranan nga pag-analisa sa ingon nagpatunghag dili kasaligan nga mga sangputanan. Sa tinuud, ang dili maayo nga kalidad sa wala mailhi nga datos naghimo nga hapit imposible nga magamit kini alang sa mga advanced nga buluhaton sa pag-analisa (eg AI/ML modeling ug dashboarding).
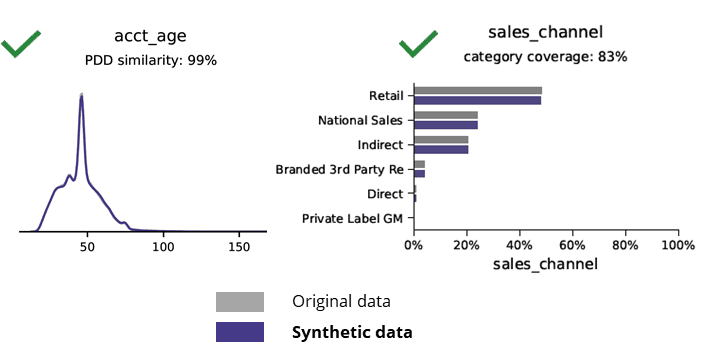
Panguna nga estadistika kung itandi ang sintetikong datos sa orihinal nga datos
Ang paghimo sa sintetikong datos nga adunay AI nagpreserbar sa sukaranan nga mga sumbanan, lohika sa negosyo, mga relasyon ug estadistika (sama sa pananglitan sa ubos). Ang paggamit sa sintetikong datos para sa batakang pag-analisa sa ingon nagpatunghag kasaligang mga resulta. Panguna nga pangutana, ang sintetikong datos ba nagkupot alang sa mga advanced analytics nga buluhaton (eg AI/ML modeling ug dashboarding)?
AI-generated synthetic data ug advanced analytics
Ang sintetikong datos nagkupot dili lamang alang sa mga batakang sumbanan (sama sa gipakita sa kanhi nga mga laraw), nakuha usab niini ang lawom nga 'tinago' nga mga sumbanan sa istatistika nga gikinahanglan alang sa mga advanced nga buluhaton sa analytics. Ang ulahi gipakita sa bar chart sa ubos, nga nagpakita nga ang katukma sa mga modelo nga gibansay sa sintetikong datos kumpara sa mga modelo nga gibansay sa orihinal nga datos parehas. Dugang pa, nga adunay usa ka lugar sa ilawom sa kurba (AUC*) nga hapit sa 0.5, ang mga modelo nga gibansay sa wala mailhi nga datos naghimo sa labing daotan. Ang bug-os nga report uban sa tanan nga advanced analytics assessments sa sintetikong data kon itandi sa orihinal nga data anaa sa hangyo.
*AUC: ang lugar sa ilawom sa kurba usa ka sukod alang sa katukma sa mga advanced nga modelo sa analytics, nga gikonsiderar ang tinuod nga positibo, sayup nga positibo, sayup nga negatibo ug tinuod nga negatibo. Ang 0,5 nagpasabot nga ang usa ka modelo nagtagna nga random ug walay predictive nga gahum ug ang 1 nagpasabot nga ang modelo kanunay nga husto ug adunay bug-os nga predictive nga gahum.
Dugang pa, kini nga sintetikong datos mahimong magamit aron masabtan ang mga kinaiya sa datos ug nag-unang mga variable nga gikinahanglan alang sa aktuwal nga pagbansay sa mga modelo. Ang mga input nga gipili sa mga algorithm sa sintetikong datos kumpara sa orihinal nga datos parehas kaayo. Busa, ang proseso sa pagmodelo mahimo sa kini nga sintetikong bersyon, nga makapamenos sa peligro sa mga paglapas sa datos. Bisan pa, kung nag-inferencing sa indibidwal nga mga rekord (eg. kustomer sa telco) ang pag-retraining sa orihinal nga datos girekomenda alang sa pagpatin-aw, dugang nga pagdawat o tungod lang sa regulasyon.
AUC pinaagi sa Algorithm nga gi-grupo sa Pamaagi
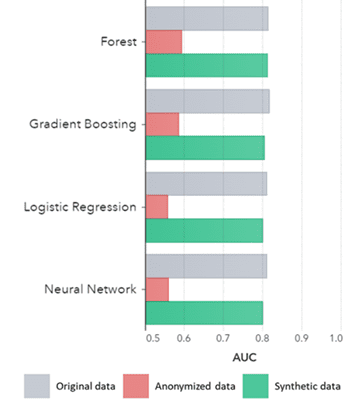
Mga konklusyon:
- Ang mga modelo nga gibansay sa sintetikong datos kumpara sa mga modelo nga gibansay sa orihinal nga datos nagpakita og susama kaayo nga performance
- Ang mga modelo nga gibansay sa wala mailhi nga datos nga adunay 'classic nga mga teknik sa anonymization' nagpakita nga mas ubos nga pasundayag kung itandi sa mga modelo nga gibansay sa orihinal nga datos o sintetikong datos
- Sayon ug paspas ang paghimo sa sintetikong datos tungod kay parehas ra ang pamaagi sa matag dataset ug matag tipo sa datos.
Mga kaso sa paggamit sa sintetikong datos nga nagdugang bili
Gamita ang kaso 1: Sintetikong datos alang sa pagpalambo sa modelo ug advanced analytics
Ang pagbaton ug lig-on nga pundasyon sa datos nga adunay dali ug paspas nga pag-access sa magamit, taas nga kalidad nga datos hinungdanon aron makahimo og mga modelo (eg dashboard [BI] ug advanced analytics [AI & ML]). Bisan pa, daghang mga organisasyon ang nag-antos sa usa ka suboptimal nga pundasyon sa datos nga nagresulta sa 3 nga hinungdanon nga mga hagit:
- Ang pag-access sa datos nagkinahanglan og edad tungod sa mga regulasyon (privacy), sulud nga proseso o mga data silo
- Ang klasiko nga mga teknik sa anonymization nagguba sa datos, nga naghimo sa datos nga dili na angay alang sa pag-analisa ug advanced analytics (basura in = basura out)
- Ang kasamtangan nga mga solusyon dili scalable tungod kay kini lahi sa pagtrabaho kada dataset ug kada data type ug dili makadumala sa dagkong multi-table databases
Sintetikong pamaagi sa datos: paghimo og mga modelo nga adunay ingon ka maayo nga tinuod nga sintetikong datos aron:
- Pagminusan ang paggamit sa orihinal nga datos, nga dili makababag sa imong mga developer
- Pag-abli sa kaugalingon nga datos ug pag-access sa daghang datos nga kaniadto gikutuban (pananglitan tungod sa pagkapribado)
- Dali ug dali nga pag-access sa datos sa may kalabutan nga datos
- Adunay sukaranan nga solusyon nga parehas nga molihok alang sa matag dataset, datatype ug alang sa daghang database
Gitugotan niini ang organisasyon nga magtukod usa ka lig-on nga pundasyon sa datos nga adunay dali ug paspas nga pag-access sa magamit, taas nga kalidad nga datos aron maablihan ang datos ug magamit ang mga oportunidad sa datos.
Gamita ang kaso 2: smart synthetic test data para sa software testing, development ug delivery
Ang pagsulay ug pag-uswag nga adunay taas nga kalidad nga datos sa pagsulay hinungdanon aron mahatagan ang labing kabag-o nga mga solusyon sa software. Ang paggamit sa orihinal nga datos sa produksiyon daw klaro, apan dili gitugotan tungod sa (privacy) nga mga regulasyon. Alternatibo Test Data Management (TDM) nga mga himan nagpaila "legacy-by-design"sa pagkuha sa datos sa pagsulay nga husto:
- Ayaw ipakita ang datos sa produksiyon ug ang lohika sa negosyo ug ang integridad sa referential dili mapreserbar
- Hinay ang pagtrabaho ug usik ug panahon
- Gikinahanglan ang manwal nga trabaho
Sintetikong pamaagi sa datos: Pagsulay ug pagpalambo gamit ang AI-generated nga sintetikong datos sa pagsulay aron maghatag ug state-of-the-art nga mga solusyon sa software nga maalamon sa:
- Ang datos nga sama sa produksiyon nga adunay gipreserbar nga lohika sa negosyo ug integridad sa referential
- Dali ug dali nga paghimo sa datos nga adunay state-of-the art AI
- Privacy-by-design
- Sayon, paspas ug agile
Gitugotan niini ang organisasyon sa pagsulay ug pag-uswag gamit ang sunod nga lebel nga datos sa pagsulay aron mahatagan ang labing kaayo nga mga solusyon sa software!
Dugang nga impormasyon
Interesado? Para sa dugang nga impormasyon bahin sa synthetic data, bisitaha ang Syntho website o kontaka si Wim Kees Janssen. Para sa dugang nga impormasyon bahin sa SAS, bisitaha www.sas.com o kontaka ang kees@syntho.ai.
Niini nga kaso sa paggamit, ang Syntho, SAS ug ang NL AIC nagtinabangay aron makab-ot ang gituyo nga mga resulta. Si Syntho usa ka eksperto sa AI-generated synthetic data ug ang SAS usa ka market leader sa analytics ug nagtanyag og software para sa pagsuhid, pag-analisar ug paghanduraw sa datos.
* Nagtagna sa 2021 - Mga Istratehiya sa Data ug Pag-analisa sa Pagdumala, Pagsukod ug Pagbag-o sa Digital nga Negosyo, Gartner, 2020.

I-save ang imong synthetic data guide karon!
- Unsa ang datos nga synthetic?
- Ngano nga gigamit kini sa mga organisasyon?
- Pagdugang og bili sa mga kaso sa kliyente sa sintetikong datos
- Giunsa pagsugod
