Avārijas kursa sintētiskie dati
Uzzināt vairāk
SAZINIETIES AR MUMS
Ievads
Kas ir sintētiskie dati?
Atbilde ir salīdzinoši vienkārša. Sākotnējie dati tiek vākti visās jūsu saskarsmēs ar reālām personām (piemēram, klientiem, pacientiem, darbiniekiem utt.) un visos jūsu iekšējos procesos, bet sintētiskos datus ģenerē datora algoritms. Šis datora algoritms ģenerē pilnīgi jaunus un mākslīgus datu punktus.
Atrisiniet datu privātuma problēmas
Sintētiski ģenerētie dati sastāv no pilnīgi jauniem un mākslīgiem datu punktiem, kuriem nav tiešas attiecības ar sākotnējiem datiem. Tādējādi nevienu no sintētiskajiem datu punktiem nevar izsekot vai apgriezties pēc sākotnējiem datiem. Tā rezultātā sintētiskie dati ir atbrīvoti no privātuma regulējuma, piemēram, GDPR, un kalpo kā risinājums datu privātuma problēmu risināšanai un pārvarēšanai.
Palieliniet un simulējiet
Sintētisko datu ģenerēšanas ģeneratīvais aspekts ļauj papildināt un simulēt pilnīgi jaunus datus. Tas darbojas kā risinājums, ja jums nav pietiekami daudz datu (datu trūkums), vēlaties veikt malas gadījumu izlasi vai ja jums vēl nav datu.
Šeit Syntho uzmanības centrā ir strukturēti dati (dati, kas formatēti tabulās, kurās ir rindas un kolonnas, kā jūs redzat Excel lapās), taču mums vienmēr patīk ilustrēt sintētisko datu jēdzienu, izmantojot attēlus, jo tas ir pievilcīgāk.
Sintētisko datu veidi
Sintētisko datu jumta ietvaros pastāv trīs sintētisko datu veidi. Šie 3 sintētisko datu veidi ir: fiktīvi dati, uz noteikumiem balstīti sintētiskie dati un mākslīgā intelekta (AI) ģenerētie sintētiskie dati. Mēs īsi paskaidrojam, kas ir 3 dažādi sintētisko datu veidi.
Neīstie dati / izspēles dati
Dummy dati ir nejauši ģenerēti dati (piemēram, ar viltus datu ģeneratoru).
Līdz ar to raksturlielumi, attiecības un statistikas modeļi, kas ir oriģinālajos datos, netiek saglabāti, tverti un reproducēti ģenerētajos fiktīvajos datos. Tādējādi fiktīvu datu / imitācijas datu reprezentativitāte ir minimāla salīdzinājumā ar sākotnējiem datiem.
- Kad to izmantot: lai aizstātu tiešos identifikatorus (PII) vai ja jums nav datu (vēl) un nevēlaties tērēt laiku un enerģiju noteikumu definēšanai.
Uz noteikumiem balstīti ģenerēti sintētiskie dati
Uz kārtulām balstīti ģenerēti sintētiskie dati ir sintētiski dati, ko ģenerē iepriekš noteikta noteikumu kopa. Šo iepriekš definēto noteikumu piemēri varētu būt sintētiskie dati ar noteiktu minimālo vērtību, maksimālo vērtību vai vidējo vērtību. Jebkurš no raksturlielumiem, attiecībām un statistikas modeļiem, ko vēlaties reproducēt uz kārtulām balstītajos ģenerētajos sintētiskos datos, ir iepriekš jādefinē.
Līdz ar to datu kvalitāte būs tikpat laba kā iepriekš noteiktais noteikumu kopums. Tas rada problēmas, ja ļoti svarīga ir augsta datu kvalitāte. Pirmkārt, var definēt tikai ierobežotu noteikumu kopumu, kas jāietver sintētiskos datos. Turklāt, iestatot vairākas kārtulas, parasti noteikumi pārklājas un konfliktē. Turklāt jūs nekad pilnībā neaptvērsit visus attiecīgos noteikumus. Turklāt var būt atbilstoši noteikumi, par kuriem jūs pat nezināt. Un visbeidzot (un neaizmirstiet), ka tas prasīs jums daudz laika un enerģijas, kā rezultātā tiks izveidots neefektīvs risinājums.
- Kad to izmantot: kad jums nav datu (vēl)
Sintētiskie dati, ko ģenerē mākslīgais intelekts (AI)
Kā jūs sagaidāt no nosaukuma, mākslīgā intelekta (AI) ģenerētie sintētiskie dati ir mākslīgā intelekta (AI) algoritma ģenerēti sintētiski dati. AI modelis ir apmācīts, pamatojoties uz sākotnējiem datiem, lai uzzinātu visas īpašības, attiecības un statistikas modeļus. Pēc tam šis AI algoritms spēj ģenerēt pilnīgi jaunus datu punktus un modelēt šos jaunos datu punktus tā, lai tas reproducētu sākotnējās datu kopas raksturlielumus, attiecības un statistikas modeļus. Tas ir tas, ko mēs saucam par sintētisko datu dvīni.
AI modelis atdarina sākotnējos datus, lai ģenerētu sintētiskos datu dvīņus, kurus var izmantot tā, it kā tie būtu oriģinālie dati. Tas atbloķē dažādus lietošanas gadījumus, kad AI ģenerētos sintētiskos datus var izmantot kā alternatīvu oriģinālo (sensitīvo) datu izmantošanai, piemēram, AI ģenerētu sintētisko datu izmantošanai kā testa datiem, demonstrācijas datiem vai analītikai.
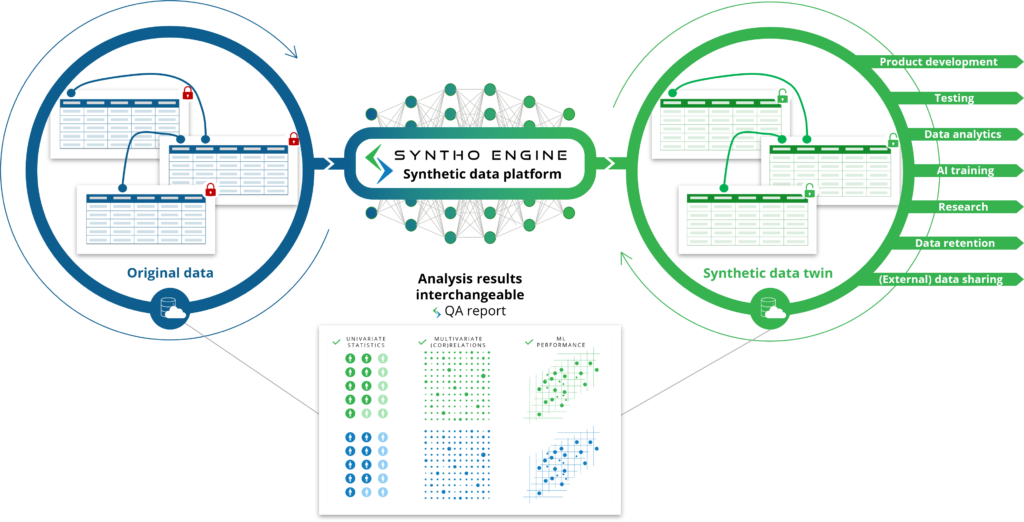
Salīdzinot ar kārtulu ģenerētiem sintētiskiem datiem: tā vietā, lai jūs pētītu un definētu atbilstošos noteikumus, AI algoritms to dara automātiski jūsu vietā. Šeit tiks apskatītas ne tikai īpašības, attiecības un statistikas modeļi, par kuriem jūs zināt, bet arī īpašības, attiecības un statistikas modeļi, par kuriem jūs pat nezināt.
- Kad to izmantot: ja jums ir (daži) dati, lai atdarinātu vai izmantotu kā sākumpunktu viedām datu ģenerēšanas un papildināšanas funkcijām
Kāda veida sintētiskos datus izmantot?
Atkarībā no jūsu lietošanas gadījuma ir ieteicama fiktīvu datu / imitācijas datu, uz noteikumiem balstītu sintētisko datu vai mākslīgā intelekta (AI) ģenerētu sintētisko datu kombinācija. Šis pārskats sniedz pirmo norādi par to, kāda veida sintētiskos datus izmantot. Tā kā Syntho tos visus atbalsta, sazinieties ar mūsu ekspertiem, lai kopā ar mums izpētītu jūsu lietošanas gadījumu.


