

Izvješće o osiguranju kvalitete tvrtke Syntho procjenjuje generirane sintetičke podatke i pokazuje točnost, privatnost i brzinu sintetičkih podataka u usporedbi s izvornim podacima.
U Synthu razumijemo važnost pouzdanih i točnih sintetičkih podataka. Zato nudimo sveobuhvatno izvješće o osiguranju kvalitete za svako pokretanje sintetičkih podataka. Naše izvješće o kvaliteti uključuje različite metrike kao što su distribucije, korelacije, multivarijatne distribucije, metrike privatnosti i više. Na taj način možete jednostavno procijeniti da su sintetički podaci koje pružamo najviše kvalitete i da se mogu koristiti s istom razinom točnosti i pouzdanosti kao i vaši izvorni podaci.
Hvatanje kratkog pogleda: ovaj odjeljak ilustrira najvažnije iz našeg izvješća o kvaliteti sintetičkih podataka. Naše procjene ispituju sintetičke podatke u usporedbi sa stvarnim podacima u različitim dimenzijama.
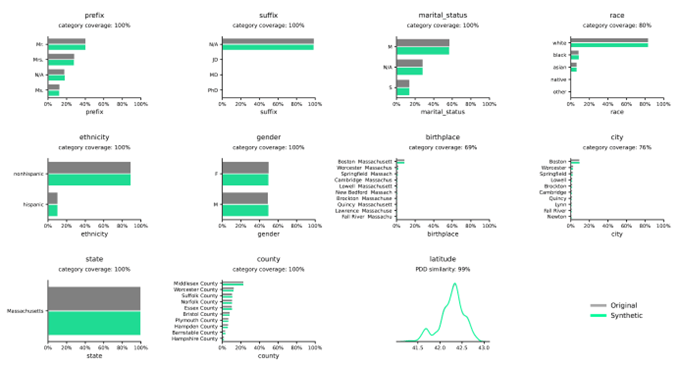
Distribucije sintetičkih podataka u usporedbi sa stvarnim podacima
Distribucije ilustriraju učestalost varijabli unutar zadanih kategorija ili vrijednosti i točno ih bilježi Syntho Engine.
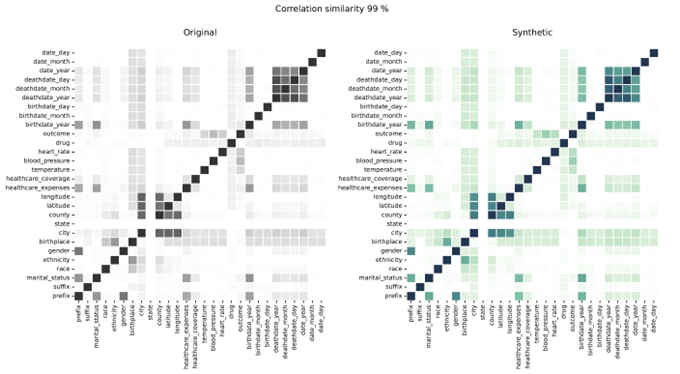
Korelacije sintetičkih podataka u usporedbi sa stvarnim podacima
Korelacije pokazuju odnos između varijabli, ilustrirajući stupanj do kojeg su varijable povezane. Syntho Engine točno bilježi te odnose.
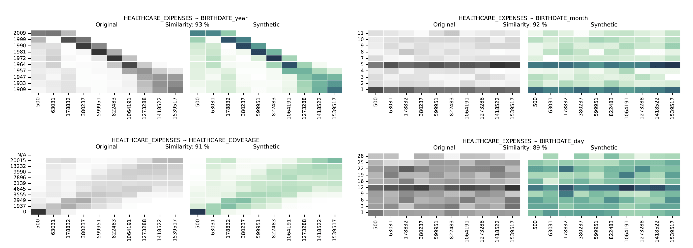
Multivarijatne distribucije sintetičkih podataka u usporedbi sa stvarnim podacima
Multivarijatne distribucije i multivarijatne korelacije vode nas dalje od pojedinačnih dimenzija, pružajući sveobuhvatan pogled na to kako su višestruke varijable povezane. Syntho Engine bilježi te odnose.
Generiranje sintetičkih podataka je složeno i zamke postoje i treba ih kontrolirati. Kod algoritama umjetne inteligencije, prekomjerno opremanje je rizik, a to je također slučaj za generiranje sintetičkih podataka pomoću umjetne inteligencije. Stoga treba kontrolirati rizik od prekomjernog opremanja prilikom generiranja sintetičkih podataka. Rizik od prekomjernog opremanja kontroliran je u Syntho Engineu. Povrh toga, izvješće Syntho Quality Assurance (QA) omogućuje organizacijama da pokažu da sintetički podaci nisu pretjerano odgovarali izvornim podacima. Također procjenjujemo aspekte koji se više odnose na privatnost, što često koriste interni revizori.
Testirajte "točna podudaranja" s omjerom identičnog podudaranja (IMR)
Dokazivanje da omjer zapisa sintetičkih podataka koji odgovaraju stvarnom zapisu iz izvornih podataka nije značajno veći od omjera koji se može očekivati pri analizi podataka o vlaku.
Testirajte na “Slična podudaranja” s udaljenošću do najbližeg zapisa (DCR)
Dokazivanje da normalizirana udaljenost za zapise sintetičkih podataka do njihovog najbližeg stvarnog zapisa unutar izvornih podataka nije znatno bliža od udaljenosti koja se može očekivati pri analizi podataka o vlaku.
Testirajte na “Outliers” s Omjer udaljenosti najbližeg susjeda (NNDR)
Dokazivanje da omjer udaljenosti između najbližeg i drugog najbližeg sintetičkog zapisa u odnosu na njihov najbliži zapis unutar izvornih podataka nije znatno bliži od omjera koji se može očekivati za podatke vlaka.
Ovo je samo snimka koja sažima bit našeg istraživanja kvalitete sintetičkih podataka i izvješća o osiguranju kvalitete. Nudi nijansirano razumijevanje distribucija, korelacija i multivarijantnih distribucija kao dijela sintetičkih podataka koji su obuhvaćeni naprednim mogućnostima Syntho Enginea. Više pojedinosti o našem izvješću o osiguranju kvalitete dostupno je na zahtjev.