क्रैश कोर्स सिंथेटिक डेटा
और अधिक जानें
हमसे संपर्क करें
परिचय
सिंथेटिक डेटा क्या है?
उत्तर अपेक्षाकृत सरल है। जबकि वास्तविक डेटा (जैसे क्लाइंट, मरीज़, कर्मचारी आदि) के साथ आपके सभी इंटरैक्शन में मूल डेटा एकत्र किया जाता है और आपकी सभी आंतरिक प्रक्रियाओं के माध्यम से, सिंथेटिक डेटा एक कंप्यूटर एल्गोरिथम द्वारा उत्पन्न किया जाता है। यह कंप्यूटर एल्गोरिथम पूरी तरह से नए और कृत्रिम डेटापॉइंट उत्पन्न करता है।
डेटा गोपनीयता चुनौतियों का समाधान करें
कृत्रिम रूप से उत्पन्न डेटा में पूरी तरह से नए और कृत्रिम डेटापॉइंट होते हैं, जिनका मूल डेटा से कोई एक-से-एक संबंध नहीं होता है। इसलिए, किसी भी सिंथेटिक डेटापॉइंट का पता नहीं लगाया जा सकता है या मूल डेटा में रिवर्स इंजीनियर नहीं किया जा सकता है। नतीजतन, सिंथेटिक डेटा को जीडीपीआर जैसे गोपनीयता नियमों से छूट दी गई है और यह डेटा-गोपनीयता चुनौतियों को हल करने और दूर करने के समाधान के रूप में कार्य करता है।
बढ़ाना और अनुकरण करना
सिंथेटिक डेटा जनरेशन का जनरेटिव पहलू पूरी तरह से नए डेटा को बढ़ाने और अनुकरण करने की अनुमति देता है। यह समाधान के रूप में कार्य करता है जब आपके पास पर्याप्त डेटा नहीं होता है (डेटा की कमी), एज-केस का नमूना लेना चाहते हैं या जब आपके पास अभी तक डेटा नहीं है।
यहां, सिंथो का फोकस संरचित डेटा है (डेटा को पंक्तियों और स्तंभों वाली तालिकाओं में स्वरूपित किया गया है, जैसा कि आप एक्सेल शीट में देखते हैं), लेकिन हम हमेशा छवियों के माध्यम से सिंथेटिक डेटा की अवधारणा को चित्रित करना पसंद करते हैं, क्योंकि यह अधिक आकर्षक है।
सिंथेटिक डेटा के प्रकार
सिंथेटिक डेटा छत्र के भीतर तीन प्रकार के सिंथेटिक डेटा मौजूद हैं। सिंथेटिक डेटा के वे 3 प्रकार हैं: डमी डेटा, नियम-आधारित जनित सिंथेटिक डेटा और कृत्रिम बुद्धिमत्ता (एआई) द्वारा उत्पन्न सिंथेटिक डेटा। हम शीघ्र ही समझाते हैं कि 3 विभिन्न प्रकार के सिंथेटिक डेटा क्या हैं।
डमी डेटा / नकली डेटा
डमी डेटा बेतरतीब ढंग से उत्पन्न डेटा है (उदाहरण के लिए एक नकली डेटा जनरेटर द्वारा)।
नतीजतन, विशेषताओं, संबंधों और सांख्यिकीय पैटर्न जो मूल डेटा में हैं, उन्हें बनाए गए डमी डेटा में संरक्षित, कैप्चर और पुन: प्रस्तुत नहीं किया जाता है। इसलिए, मूल डेटा की तुलना में डमी डेटा / नकली डेटा का प्रतिनिधित्व न्यूनतम है।
- इसका उपयोग कब करें: प्रत्यक्ष पहचानकर्ताओं (PII) को बदलने के लिए या जब आपके पास डेटा (अभी तक) नहीं है और आप नियमों को परिभाषित करने में समय और ऊर्जा खर्च नहीं करना चाहते हैं।
नियम-आधारित जनरेट किया गया सिंथेटिक डेटा
नियम-आधारित जनरेट किया गया सिंथेटिक डेटा, नियमों के पूर्व-निर्धारित सेट द्वारा उत्पन्न सिंथेटिक डेटा है। उन पूर्व-निर्धारित नियमों के उदाहरण यह हो सकते हैं कि आप एक निश्चित न्यूनतम मान, अधिकतम मान या औसत मान के साथ सिंथेटिक डेटा रखना चाहते हैं। कोई भी विशेषता, संबंध और सांख्यिकीय पैटर्न, जिसे आप नियम-आधारित जनित सिंथेटिक डेटा में पुन: प्रस्तुत करना चाहते हैं, को पूर्व-परिभाषित करने की आवश्यकता है।
नतीजतन, डेटा की गुणवत्ता नियमों के पूर्व-निर्धारित सेट जितनी अच्छी होगी। यह चुनौतियों का परिणाम है जब उच्च डेटा गुणवत्ता सार की होती है। सबसे पहले, सिंथेटिक डेटा में कैप्चर किए जाने वाले नियमों के केवल एक सीमित सेट को परिभाषित किया जा सकता है। इसके अतिरिक्त, कई नियम स्थापित करने से आम तौर पर अतिव्यापी और परस्पर विरोधी नियम होंगे। इसके अलावा, आप कभी भी सभी प्रासंगिक नियमों को पूरी तरह से कवर नहीं करेंगे। इसके अलावा, ऐसे प्रासंगिक नियम हो सकते हैं जिनके बारे में आपको जानकारी भी नहीं है। और अंत में (और भूलना नहीं), इसमें आपको बहुत समय और ऊर्जा लगेगी जिसके परिणामस्वरूप एक गैर-कुशल समाधान होगा।
- इसका उपयोग कब करें: जब आपके पास डेटा नहीं है (अभी तक)
कृत्रिम बुद्धि (एआई) द्वारा उत्पन्न सिंथेटिक डेटा
जैसा कि आप नाम से उम्मीद करते हैं, कृत्रिम बुद्धि (एआई) द्वारा उत्पन्न सिंथेटिक डेटा कृत्रिम बुद्धि (एआई) एल्गोरिदम द्वारा उत्पन्न सिंथेटिक डेटा है। सभी विशेषताओं, संबंधों और सांख्यिकीय पैटर्न को सीखने के लिए एआई मॉडल को मूल डेटा पर प्रशिक्षित किया जाता है। इसके बाद, यह एआई एल्गोरिदम पूरी तरह से नए डेटापॉइंट उत्पन्न करने में सक्षम है और उन नए डेटापॉइंट्स को इस तरह से मॉडल करता है कि यह मूल डेटासेट से विशेषताओं, संबंधों और सांख्यिकीय पैटर्न को पुन: उत्पन्न करता है। इसे हम सिंथेटिक डेटा ट्विन कहते हैं।
एआई मॉडल सिंथेटिक डेटा ट्विन्स उत्पन्न करने के लिए मूल डेटा की नकल करता है जिसका उपयोग मूल डेटा के रूप में किया जा सकता है। यह विभिन्न उपयोग के मामलों को अनलॉक करता है जहां एआई उत्पन्न सिंथेटिक डेटा को मूल (संवेदनशील) डेटा का उपयोग करने के विकल्प के रूप में उपयोग किया जा सकता है, जैसे एआई उत्पन्न सिंथेटिक डेटा का परीक्षण डेटा, डेमो डेटा या एनालिटिक्स के लिए उपयोग करना।
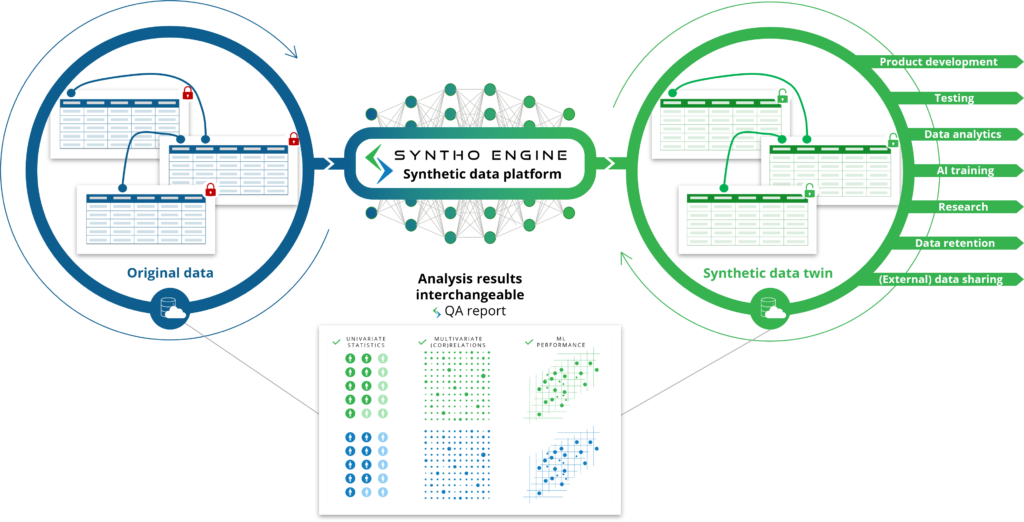
नियम-आधारित जनरेट किए गए सिंथेटिक डेटा की तुलना में: प्रासंगिक नियमों का अध्ययन करने और उन्हें परिभाषित करने के बजाय, AI एल्गोरिथम आपके लिए यह स्वचालित रूप से करता है। यहां, न केवल विशेषताओं, संबंधों और सांख्यिकीय पैटर्न को कवर किया जाएगा, जिनके बारे में आप जानते हैं, उन विशेषताओं, संबंधों और सांख्यिकीय पैटर्न को भी शामिल किया जाएगा जिनके बारे में आप जानते भी नहीं हैं।
- इसका उपयोग कब करें: जब आपके पास (कुछ) डेटा की नकल करने के लिए इनपुट के रूप में या स्मार्ट डेटा पीढ़ी और वृद्धि सुविधाओं के लिए शुरुआती बिंदु के रूप में उपयोग करने के लिए हो
किस प्रकार के सिंथेटिक डेटा का उपयोग करना है?
आपके उपयोग के मामले के आधार पर, कृत्रिम बुद्धि (एआई) द्वारा उत्पन्न नकली डेटा / नकली डेटा, नियम-आधारित सिंथेटिक डेटा या सिंथेटिक डेटा के संयोजन की सलाह दी जाती है। यह अवलोकन आपको पहला संकेत प्रदान करता है कि किस प्रकार के सिंथेटिक डेटा का उपयोग करना है। जैसा कि सिंथो उन सभी का समर्थन करता है, हमारे साथ अपने उपयोग के मामले को गहरा करने के लिए हमारे विशेषज्ञों से बेझिझक संपर्क करें।


