Datos sintéticos xerados pola intelixencia artificial, acceso fácil e rápido a datos de alta calidade?
A IA xerou datos sintéticos na práctica
Syntho, un experto en datos sintéticos xerados pola IA, pretende virar privacy by design nunha vantaxe competitiva con datos sintéticos xerados por IA. Axudan ás organizacións a construír unha base de datos sólida con acceso fácil e rápido a datos de alta calidade e recentemente gañaron o premio Philips Innovation Award.
Non obstante, a xeración de datos sintéticos con IA é unha solución relativamente nova que adoita introducir preguntas frecuentes. Para responder a isto, Syntho iniciou un estudo de caso xunto con SAS, líder do mercado en analítica avanzada e software de intelixencia artificial.
En colaboración coa Dutch AI Coalition (NL AIC), investigaron o valor dos datos sintéticos comparando os datos sintéticos xerados pola IA xerados polo Syntho Engine cos datos orixinais mediante varias avaliacións sobre a calidade dos datos, a validez legal e a usabilidade.
A anonimización de datos non é unha solución?
As técnicas clásicas de anonimización teñen en común que manipulan datos orixinais para dificultar o rastrexo dos individuos. Exemplos son a xeneralización, supresión, borrado, pseudónimo, enmascaramento de datos e mestura de filas e columnas. Podes atopar exemplos na seguinte táboa.
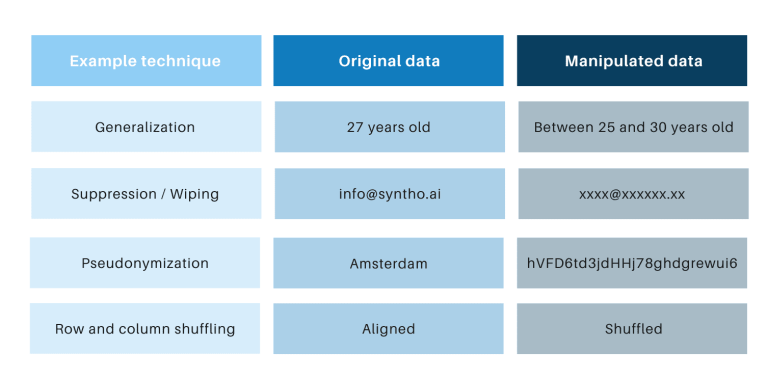
Estas técnicas presentan 3 desafíos fundamentais:
- Funcionan de forma diferente por tipo de datos e por conxunto de datos, polo que son difíciles de escalar. Ademais, dado que funcionan de forma diferente, sempre haberá debate sobre que métodos aplicar e que combinación de técnicas son necesarias.
- Sempre hai unha relación un a un cos datos orixinais. Isto significa que sempre haberá un risco de privacidade, especialmente debido a todos os conxuntos de datos abertos e ás técnicas dispoñibles para vincular eses conxuntos de datos.
- Manipulan datos e, polo tanto, destrúen os datos no proceso. Isto é especialmente devastador para as tarefas de intelixencia artificial nas que o "poder preditivo" é esencial, porque os datos de mala calidade darán lugar a malas perspectivas do modelo de intelixencia artificial (o lixo provocará a eliminación do lixo).
Estes puntos tamén se avalían a través deste estudo de caso.
Unha introdución ao estudo de caso
Para o estudo de caso, o conxunto de datos obxectivo foi un conxunto de datos de telecomunicacións proporcionado por SAS que contén os datos de 56.600 clientes. O conxunto de datos contén 128 columnas, incluída unha columna que indica se un cliente abandonou a empresa (é dicir, "permitiu") ou non. O obxectivo do estudo de caso era utilizar os datos sintéticos para adestrar algúns modelos para predecir a perda de clientes e avaliar o rendemento deses modelos adestrados. Como a predición do churn é unha tarefa de clasificación, SAS seleccionou catro modelos de clasificación populares para facer as predicións, incluíndo:
- Bosque aleatorio
- Aumento do gradiente
- Regresión loxística
- Rede neuronal
Antes de xerar os datos sintéticos, SAS dividiu aleatoriamente o conxunto de datos de telecomunicacións nun conxunto de trens (para adestrar os modelos) e nun conxunto de retención (para puntuar os modelos). Ter un conxunto de puntos de retención separado para a puntuación permite unha avaliación imparcial do bo rendemento do modelo de clasificación cando se aplica a datos novos.
Usando o conxunto de trens como entrada, Syntho utilizou o seu motor Syntho para xerar un conxunto de datos sintético. Para o benchmarking, SAS tamén creou unha versión manipulada do conxunto de trens despois de aplicar varias técnicas de anonimización para alcanzar un determinado limiar (de k-anonimidade). Os pasos anteriores deron lugar a catro conxuntos de datos:
- Un conxunto de datos do tren (é dicir, o conxunto de datos orixinal menos o conxunto de datos de retención)
- Un conxunto de datos de retención (é dicir, un subconxunto do conxunto de datos orixinal)
- Un conxunto de datos anónimo (baseado no conxunto de datos do tren)
- Un conxunto de datos sintéticos (baseado no conxunto de datos do tren)
Os conxuntos de datos 1, 3 e 4 utilizáronse para adestrar cada modelo de clasificación, resultando en 12 (3 x 4) modelos adestrados. Posteriormente, SAS utilizou o conxunto de datos de retención para medir a precisión coa que cada modelo prevé o abandono do cliente. Os resultados preséntanse a continuación, comezando por algunhas estatísticas básicas.
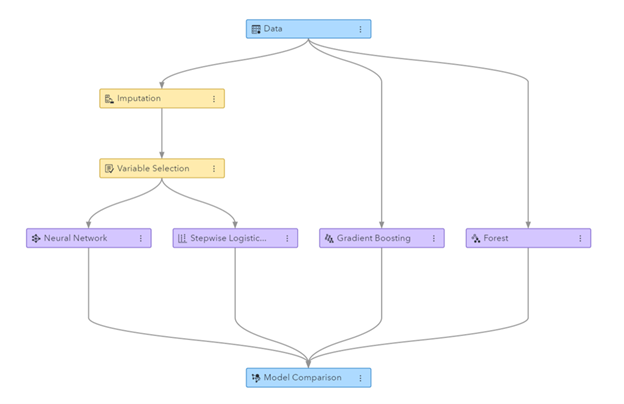
Figura: pipeline de Machine Learning xerado en SAS Visual Data Mining e Machine Learning
Estatísticas básicas ao comparar datos anónimos cos datos orixinais
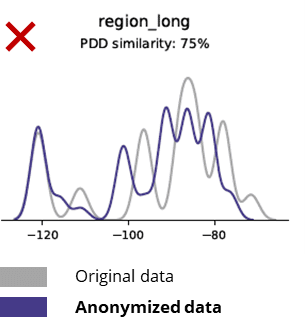
As técnicas de anonimización destrúen incluso os patróns básicos, a lóxica empresarial, as relacións e as estatísticas (como no seguinte exemplo). O uso de datos anónimos para análises básicas produce resultados pouco fiables. De feito, a mala calidade dos datos anónimos facía case imposible usalos para tarefas de análise avanzada (por exemplo, modelado e dashboard de AI/ML).
Estatísticas básicas ao comparar datos sintéticos con datos orixinais
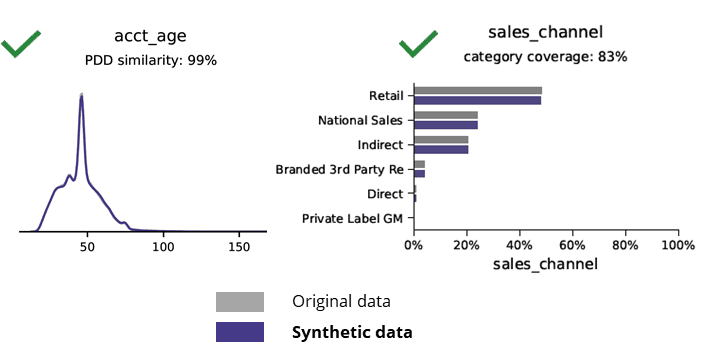
A xeración de datos sintéticos con intelixencia artificial preserva os patróns básicos, a lóxica empresarial, as relacións e as estatísticas (como no seguinte exemplo). O uso de datos sintéticos para a análise básica produce resultados fiables. Pregunta clave, os datos sintéticos son reservados para tarefas de análise avanzada (por exemplo, modelado e dashboard de IA/ML)?
Datos sintéticos xerados pola intelixencia artificial e análises avanzadas
Os datos sintéticos valen non só para patróns básicos (como se mostra nos gráficos anteriores), tamén capturan patróns estatísticos "ocultos" profundos necesarios para tarefas de análise avanzada. Este último demóstrase no gráfico de barras a continuación, o que indica que a precisión dos modelos adestrados en datos sintéticos fronte aos modelos adestrados en datos orixinais é semellante. Ademais, cunha área baixo a curva (AUC*) próxima a 0.5, os modelos adestrados con datos anónimos son os peores resultados. O informe completo con todas as avaliacións analíticas avanzadas sobre datos sintéticos en comparación cos datos orixinais está dispoñible baixo petición.
*AUC: a área baixo a curva é unha medida da precisión dos modelos analíticos avanzados, tendo en conta os verdadeiros positivos, falsos positivos, falsos negativos e verdadeiros negativos. 0,5 significa que un modelo predice aleatoriamente e non ten poder preditivo e 1 significa que o modelo é sempre correcto e ten poder preditivo total.
Ademais, estes datos sintéticos pódense utilizar para comprender as características dos datos e as principais variables necesarias para o adestramento real dos modelos. As entradas seleccionadas polos algoritmos sobre datos sintéticos en comparación cos datos orixinais foron moi similares. Polo tanto, o proceso de modelado pódese facer nesta versión sintética, o que reduce o risco de violacións de datos. Non obstante, ao inferenciar rexistros individuais (por exemplo, cliente de telecomunicacións) recoméndase a reciclaxe dos datos orixinais para explicar, aumentar a aceptación ou só por mor da regulación.
AUC por Algoritmo agrupado por Método
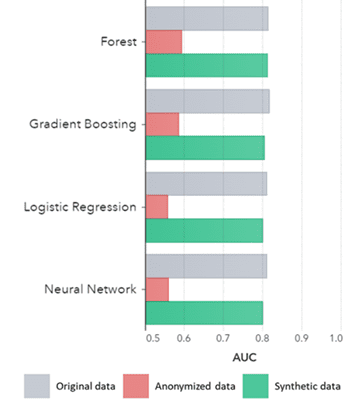
Conclusións:
- Os modelos adestrados en datos sintéticos en comparación cos modelos adestrados en datos orixinais mostran un rendemento moi similar
- Os modelos adestrados en datos anónimos con "técnicas clásicas de anonimización" mostran un rendemento inferior en comparación cos modelos adestrados en datos orixinais ou datos sintéticos
- A xeración de datos sintéticos é sinxela e rápida porque a técnica funciona exactamente igual por conxunto de datos e por tipo de datos.
Casos de uso de datos sintéticos de valor engadido
Caso de uso 1: datos sintéticos para o desenvolvemento de modelos e análises avanzadas
Ter unha base de datos sólida con acceso fácil e rápido a datos utilizables de alta calidade é esencial para desenvolver modelos (por exemplo, paneis [BI] e análises avanzadas [AI e ML]). Non obstante, moitas organizacións padecen unha base de datos subóptima que resulta en 3 desafíos clave:
- Conseguir acceso aos datos leva bastantes anos debido á normativa (privacidade), aos procesos internos ou aos silos de datos
- As técnicas clásicas de anonimización destrúen os datos, facendo que os datos xa non sexan adecuados para a análise e as análises avanzadas (lixo entra = lixo saído)
- As solucións existentes non son escalables porque funcionan de forma diferente por conxunto de datos e por tipo de datos e non poden xestionar grandes bases de datos de varias táboas
Enfoque de datos sintéticos: desenvolve modelos con datos sintéticos tan bos como reais para:
- Minimiza o uso de datos orixinais sen obstaculizar aos teus desenvolvedores
- Desbloquear datos persoais e ter acceso a máis datos que antes estaban restrinxidos (por exemplo, debido á privacidade)
- Acceso fácil e rápido aos datos relevantes
- Solución escalable que funciona igual para cada conxunto de datos, tipos de datos e bases de datos masivas
Isto permite que a organización constrúa unha base de datos sólida con acceso fácil e rápido a datos utilizables e de alta calidade para desbloquear datos e aproveitar as oportunidades de datos.
Caso de uso 2: datos de probas sintéticas intelixentes para probas, desenvolvemento e entrega de software
A proba e o desenvolvemento con datos de proba de alta calidade son esenciais para ofrecer solucións de software de última xeración. O uso de datos de produción orixinais parece obvio, pero non está permitido debido ás normas (de privacidade). Alternativa Test Data Management (TDM) introducen "legacy-by-design” para obter correctamente os datos da proba:
- Non reflicten os datos de produción e a lóxica empresarial e a integridade referencial non se preservan
- Traballar lento e lento
- Requírese traballo manual
Enfoque de datos sintéticos: proba e desenvolve con datos de proba sintéticos xerados pola IA para ofrecer solucións de software de última xeración intelixentes con:
- Datos similares á produción con lóxica empresarial preservada e integridade referencial
- Xeración de datos sinxela e rápida con IA de última xeración
- Privacidade por deseño
- Fácil, rápido e agile
Isto permite á organización probar e desenvolverse con datos de proba de nivel seguinte para ofrecer solucións de software de última xeración.
Máis información
Interesado? Para obter máis información sobre os datos sintéticos, visite o sitio web de Syntho ou póñase en contacto con Wim Kees Janssen. Para obter máis información sobre SAS, visite www.sas.com ou póñase en contacto con kees@syntho.ai.
Neste caso de uso, Syntho, SAS e NL AIC traballan xuntos para acadar os resultados previstos. Syntho é un experto en datos sintéticos xerados por IA e SAS é líder do mercado en análise e ofrece software para explorar, analizar e visualizar datos.
* Predice 2021: estratexias de datos e análise para gobernar, escalar e transformar o negocio dixital, Gartner, 2020.

Garda a túa guía de datos sintéticos agora!
- Que son os datos sintéticos?
- Por que o utilizan as organizacións?
- Casos de clientes de datos sintéticos de valor engadido
- Como comezar
